

Introduction
Welcome to the exciting world of data visualization using Python. Data visualization finds applications across various domains, aiding in better comprehension and decision-making. In business, it helps identify market trends, track sales performance, and optimize strategies. It is one of key component of data science. In retail it is helping in optimizing the customer experience. In healthcare, it facilitates disease monitoring, patient care analysis, and medical research. Education benefits from visualizing student performance, learning outcomes, and curriculum effectiveness. Government agencies utilize it for public policy analysis, resource allocation, and urban planning. Moreover, data visualization plays a crucial role in scientific research, financial analysis, social media analytics, and more, making complex data accessible and actionable across diverse fields.
In this post, we’ll uncover the magic of transforming raw data into captivating charts and graphs. By the end, you’ll be equipped to unravel trends, patterns, and relationships within your data like a pro.
Let’s kick things off with a quick overview:
Unraveling Data
What is Data?
Imagine that you own a diary where you are going to write down how much money you are spending each day. So you will make multiple entries into your diary regarding your expenditure. Your entries may look like the following:
1. Monday: $5 for lunch
2. Tuesday: $10 for movie tickets
3. Wednesday: $ 15 for dinner at a restaurant
In this example each entry represents a piece of information. This collection of information is called data. Here your entire week’s spending is recorded in your notebook would be considered data. So, data is just facts or details that we can use to learn or make decisions. Just think of data as pieces of information that we can gather and/or record.
The importance of data can be gauged by its importance to help us understand patterns, trends, or relationships. By analyzing data, we can discover insights that allow us to make informed decisions. For example if we review the spending data over several weeks, we can observe different patterns such as spending more on weekends or allocating more budget to entertainment. This insight or information is very valuable and can help in effective budgeting and spending adjustments.
To summarize, data is the building blocks of information. It provide us with valuable insights that can be used to learn, understand, and make decisions in various aspects of our lives.
Data Types: The Quantitative Edge
There are many data types but the most used data type for analytics and insights is the quantitative data. In this blog we are only concerned with this type of data. Quantitative data allows for mathematical calculations, statistical analysis, and the identification of patterns and trends. Quantitative data consists of counting or numerical measurements. It provides a precise and structured format for analysis.
We can perform various statistical techniques such as regression analysis, hypothesis testing, and clustering on quantitative data. By employing these techniques, we can find relationships between variables, make predictions, and derive insights from the data.
The Power of Visualization
Data visualization isn’t just about pretty charts—it’s about clarity. With Python’s robust ecosystem of visualization libraries, we can communicate complex information in a breeze. Whether it’s spotting trends, outliers, or correlations, visualization brings data to life.
Installing Libraries: Building Blocks of Visualization
Before we dive into coding, let’s set the stage. First up, make sure you have Python installed. Then, pick your weapon of choice—be it Visual Studio Code, PyCharm, or Jupyter Notebook. Feeling adventurous? Consider creating a virtual environment to keep things tidy.
3 Examples to Kickstart Your Journey
Alright! Are you ready to flex your visualization muscles? Here are three Python scripts to get you started:
Example 1: Line Chart
The following example creates a simple line chart to visualize temperature data over time:
import matplotlib.pyplot as plt # Import library
temperatures = [20, 22, 25, 23, 21, 19] # Sample temperature data
days = [“Mon”, “Tue”, “Wed”, “Thu”, “Fri”, “Sat”]
plt.plot(days, temperatures) # Create the line chart
plt.xlabel(“Day”) # Add labels and title
plt.ylabel(“Temperature (°C)”)
plt.title(“Weekly Temperature Variation”)
plt.show() # Display the chart
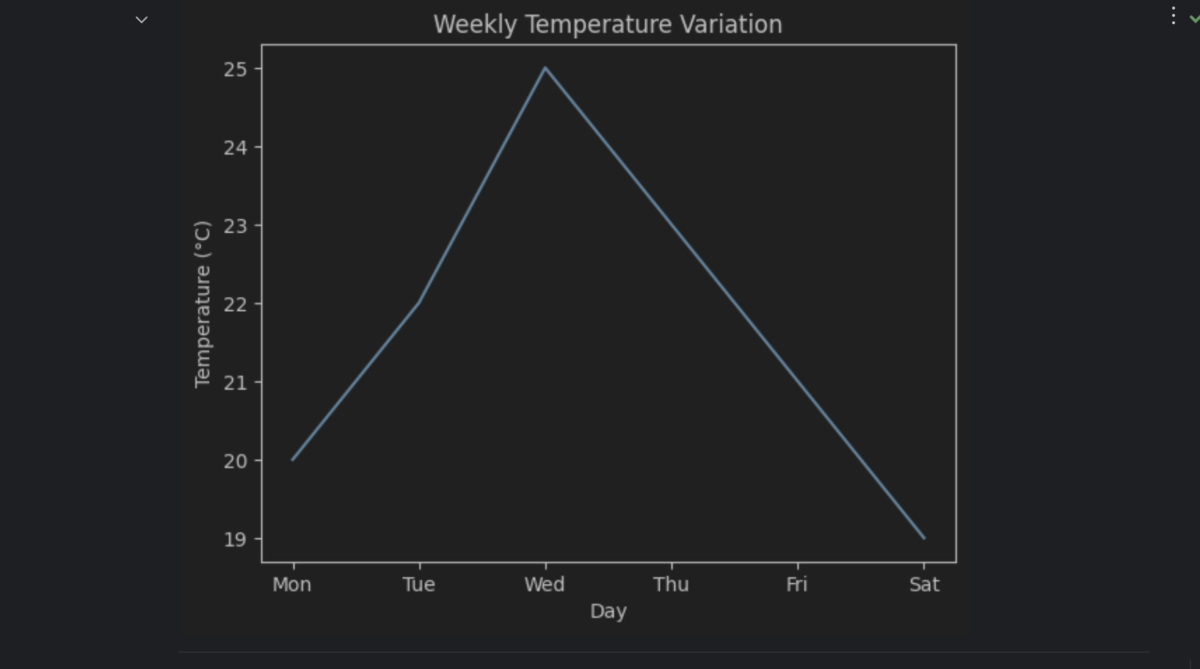
Here is how it appears in Jupyter Notebook:
When you run the above script, you get a sleek line chart to visualize temperature variations over the week.
The above given script creates a line chart to visualize temperature data over different days. Here’s a detailed explanation of each line:
1. Importing the Library:
Python’s Matplotlib Library
Python/Jupyter Notebook
import matplotlib.pyplot as plt
This line imports the matplotlib.pyplot library, which is widely used for generating various types of charts and graphs in Python. We alias it as plt for easier access throughout the code.
2. Defining Sample Temperature Data:
Python/Jupyter Notebook
temperatures = [20, 22, 25, 23, 21, 19]
Here, we define a list named temperatures containing numerical values, representing the temperature readings (in Celsius, assumed) for each day.
3. Assigning Days of the Week:
Python/Jupyter Notebook
days = [“Mon”, “Tue”, “Wed”, “Thu”, “Fri”, “Sat”]
This line creates another list called days, which holds strings representing the days of the week corresponding to the temperature readings.
4. Creating the Line Chart:
Python/Jupyter Notebook
plt.plot(days, temperatures)
In this line, we use plt.plot() to create the line chart. It takes two arguments:
-
- days: The days of the week, which serve as the x-axis data points.
-
- temperatures: The temperature readings, acting as the y-axis data points.
This function connects the data points with lines, forming the line chart.
5. Adding Labels and Title:
Python/Jupyter Notebook
plt.xlabel(“Day”) plt.ylabel(“Temperature (°C)”) plt.title(“Weekly Temperature Variation”)
These lines set labels and a title for the chart:
-
- plt.xlabel(“Day”): Adds a label “Day” to the x-axis.
-
- plt.ylabel(“Temperature (°C)”): Adds a label “Temperature (°C)” to the y-axis.
-
- plt.title(“Weekly Temperature Variation”): Sets the title of the chart to “Weekly Temperature Variation”.
-
- Displaying the Chart:
Python/Jupyter Notebook
plt.show()
Finally, plt.show() is called to display the generated line chart on the screen.
Example 2: Bar Chart
Now let’s dive into customer age distribution with a snazzy bar chart powered by Seaborn:
import matplotlib.pyplot as plt
categories = [‘Category 1’, ‘Category 2’, ‘Category 3’, ‘Category 4’] # Sample data
values = [20, 35, 30, 25]
plt.bar(categories, values, color=’skyblue’) # Create the bar chart
plt.xlabel(‘Categories’) # Add labels and title
plt.ylabel(‘Values’)
plt.title(‘Bar Chart Example’)
plt.show() # Show the plot
Here is how it appears in Jupyter Notebook:
When you run the above script, you get a beautiful bar chart:
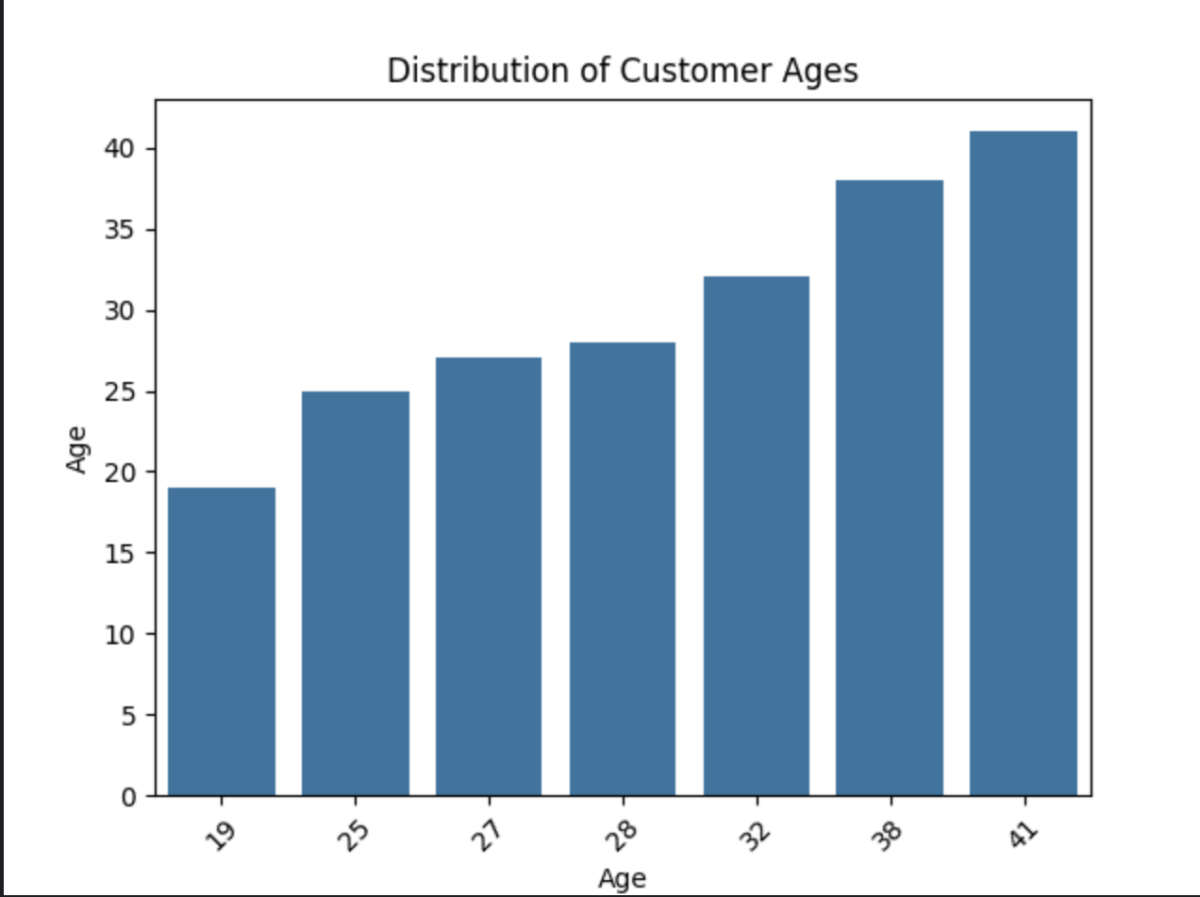
Here, we are performing data visualization in Python to represent customer age distribution using a bar chart. Here’s an explanation of the purpose of each line of our code:
1. Import Library:
Python/Jupyter Notebook
import matplotlib.pyplot as plt
This line imports the plotting functionalities from the matplotlib library and assigns it the alias plt for convenience. Matplotlib is a powerful library for creating various visualizations in Python.
2. Define Data:
Python/Jupyter Notebook
categories = [‘Category 1’, ‘Category 2’, ‘Category 3’, ‘Category 4’] # Sample data
values = [20, 35, 30, 25]
These lines define two lists:
-
- categories: This list contains labels for the bars on the x-axis (horizontal axis).
-
- values: This list contains numerical values corresponding to each category. These values represent the height of each bar in the chart.
3. Create the Bar Chart:
Python/Jupyter Notebook
plt.bar(categories, values, color=’skyblue’)
This line is the heart of creating the bar chart. Here’s what it does:
-
- plt.bar(categories, values): This method from matplotlib creates a bar chart. It takes two arguments:
-
- categories: The list of labels for the x-axis.
-
- values: The list of numerical values for the height of each bar.
-
- plt.bar(categories, values): This method from matplotlib creates a bar chart. It takes two arguments:
-
- color=’skyblue’: This sets the color of the bars to “skyblue”. You can change this value to any other color name or hex code for customization.
4. Add Labels and Title:
Python/Jupyter Notebook
plt.xlabel(‘Categories’) plt.ylabel(‘Values’) plt.title(‘Bar Chart Example’)
These lines add labels and a title to the chart for better understanding:
-
- plt.xlabel(‘Categories’): This adds a label “Categories” to the x-axis.
-
- plt.ylabel(‘Values’): This adds a label “Values” to the y-axis (vertical axis).
-
- plt.title(‘Bar Chart Example’): This sets the title of the chart to “Bar Chart Example”.
5. Display the Chart:
Python/Jupyter Notebook
plt.show()
This line tells matplotlib to display the created chart on your screen.
By running this code, you’ll see a bar chart with categories on the x-axis, values on the y-axis, a skyblue color for the bars, and the title “Bar Chart Example”.
Example 3: Histogram
This example utilizes Matplotlib to visualize the distribution of exam scores using a histogram.
import matplotlib.pyplot as plt # Import library
import numpy as np # Assuming you have exam scores as a numpy array
exam_scores = np.random.randint(60, 100, size=20) # Generate random sample exam scores
plt.hist(exam_scores) # Create the histogram
plt.xlabel(“Exam Score”) # Add labels and title
plt.ylabel(“Number of Students”)
plt.title(“Distribution of Exam Scores”)
plt.show() # Display the histogram
Here is how it appears in Jupyter Notebook:
Following is how it appears when you run the code in Jupyter Notebook:
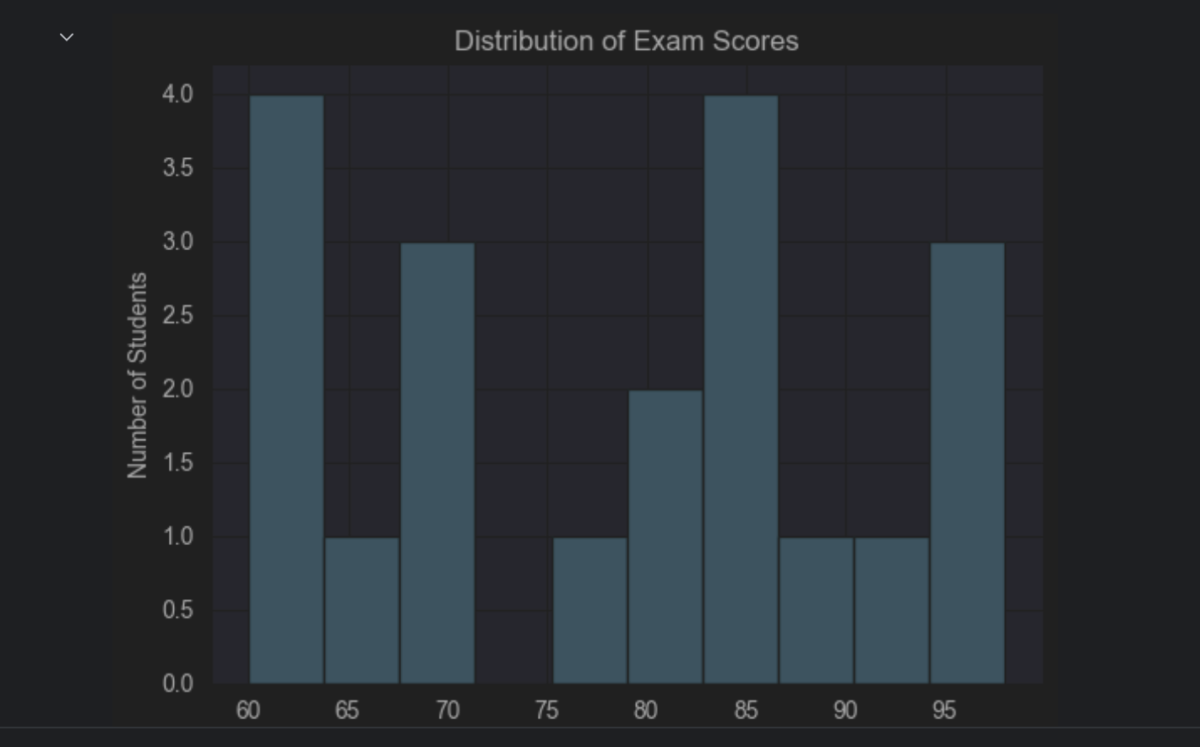
Here’s a breakdown of what the code does:
1. Importing Libraries:
-
- import matplotlib.pyplot as plt: Imports the Matplotlib library, a powerful tool for creating visual representations of data in Python. The as plt part gives it a shorter alias for convenience.
-
- import numpy as np: Imports the NumPy library, which offers efficient array manipulation and mathematical operations for numerical data.
2. Generating Sample Data:
-
- exam_scores = np.random.randint(60, 100, size=20): Creates a NumPy array called exam_scores containing 20 randomly generated integers between 60 and 100 (inclusive), simulating hypothetical exam scores.
3. Creating the Histogram:
-
- plt.hist(exam_scores): Generates a histogram based on the values in the exam_scores array. A histogram visualizes the distribution of numerical data by dividing the data range into intervals (bins) and showing the frequency of values within each bin.
4. Adding Labels and Title:
-
- plt.xlabel(“Exam Score”): Sets the label for the x-axis as “Exam Score” to clarify what the horizontal axis represents.
-
- plt.ylabel(“Number of Students”): Sets the label for the y-axis as “Number of Students” to indicate the frequency of scores.
-
- plt.title(“Distribution of Exam Scores”): Assigns a title to the plot, “Distribution of Exam Scores”, for better readability and context.
5. Displaying the Histogram:
-
- plt.show(): Renders the created histogram visually, allowing you to see the distribution of the exam scores.
Hence, we generate a histogram to visualize the distribution of hypothetical exam scores. It helps to understand the overall performance patterns of students in a more intuitive way.
Your article helped me a lot, is there any more related content? Thanks!
Your article helped me a lot, is there any more related content? Thanks!
Keep up the fantastic work! Kalorifer Sobası odun, kömür, pelet gibi yakıtlarla çalışan ve ısıtma işlevi gören bir soba türüdür. Kalorifer Sobası içindeki yakıtın yanmasıyla oluşan ısıyı doğrudan çevresine yayar ve aynı zamanda suyun ısınmasını sağlar.
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me. https://accounts.binance.com/id/register?ref=GJY4VW8W
Hey there! Do you know if they make any plugins to help with Search Engine Optimization? I’m trying to get my blog to rank for some targeted
keywords but I’m not seeing very good gains.
If you know of any please share. Cheers! You can read similar blog
here: Eco blankets
Magnificent website. Lots of helpful info here. I’m sending it to a few pals ans also sharing in delicious. And certainly, thank you for your sweat!
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me.
Thank you for your sharing. I am worried that I lack creative ideas. It is your article that makes me full of hope. Thank you. But, I have a question, can you help me?
Your point of view caught my eye and was very interesting. Thanks. I have a question for you.
I don’t think the title of your article matches the content lol. Just kidding, mainly because I had some doubts after reading the article.
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me.
Your article helped me a lot, is there any more related content? Thanks!
Hello! I simply wish to give a huge thumbs up for the great data you’ve right here on this post. I might be coming again to your weblog for extra soon.
Woh I enjoy your blog posts, bookmarked! .
Your article helped me a lot, is there any more related content? Thanks!
Thanks for sharing. I read many of your blog posts, cool, your blog is very good.
Thanks for sharing. I read many of your blog posts, cool, your blog is very good.
Thank you for your sharing. I am worried that I lack creative ideas. It is your article that makes me full of hope. Thank you. But, I have a question, can you help me?
Your article helped me a lot, is there any more related content? Thanks!
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me.
I don’t think the title of your article matches the content lol. Just kidding, mainly because I had some doubts after reading the article.
Your point of view caught my eye and was very interesting. Thanks. I have a question for you.
Thanks for sharing. I read many of your blog posts, cool, your blog is very good.
Thank you for your sharing. I am worried that I lack creative ideas. It is your article that makes me full of hope. Thank you. But, I have a question, can you help me?
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me.
I don’t think the title of your article matches the content lol. Just kidding, mainly because I had some doubts after reading the article.
Thanks for sharing. I read many of your blog posts, cool, your blog is very good.
I don’t think the title of your article matches the content lol. Just kidding, mainly because I had some doubts after reading the article.
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me.
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me.
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me.
Your point of view caught my eye and was very interesting. Thanks. I have a question for you.
I don’t think the title of your article matches the content lol. Just kidding, mainly because I had some doubts after reading the article. https://www.binance.com/join?ref=P9L9FQKY
Thank you for your sharing. I am worried that I lack creative ideas. It is your article that makes me full of hope. Thank you. But, I have a question, can you help me? https://accounts.binance.com/en-NG/register?ref=JHQQKNKN
I don’t think the title of your article matches the content lol. Just kidding, mainly because I had some doubts after reading the article.
I don’t think the title of your article matches the content lol. Just kidding, mainly because I had some doubts after reading the article. https://accounts.binance.com/ES_la/register?ref=T7KCZASX
Hi there! I know this is kinda off topic but I’d figured I’d ask. Would you be interested in exchanging links or maybe guest authoring a blog post or vice-versa? My blog discusses a lot of the same subjects as yours and I feel we could greatly benefit from each other. If you are interested feel free to shoot me an email. I look forward to hearing from you! Awesome blog by the way!
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me.
Your point of view caught my eye and was very interesting. Thanks. I have a question for you.
Thanks for sharing. I read many of your blog posts, cool, your blog is very good.
Good day! Do you know if they make any plugins to assist with SEO?
I’m trying to get my site to rank for some targeted
keywords but I’m not seeing very good results.
If you know of any please share. Many thanks! You can read
similar text here: Code of destiny
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me. https://accounts.binance.info/register?ref=P9L9FQKY
I don’t think the title of your article matches the content lol. Just kidding, mainly because I had some doubts after reading the article. https://accounts.binance.com/en/register?ref=JHQQKNKN
Your article helped me a lot, is there any more related content? Thanks! https://accounts.binance.com/si-LK/register-person?ref=V2H9AFPY
I’m really inspired together with your writing abilities as neatly as with the format on your blog. Is that this a paid theme or did you modify it yourself? Either way stay up the excellent quality writing, it’s rare to look a nice weblog like this one today. I like abortit.com ! I made: BrandWell
I’m extremely impressed along with your writing talents as smartly as with the format for your weblog. Is that this a paid topic or did you modify it your self? Anyway keep up the nice high quality writing, it is uncommon to look a great blog like this one today. I like abortit.com ! My is: Affilionaire.org
Good post. I learn one thing more challenging on different blogs everyday. It’s going to at all times be stimulating to learn content from different writers and apply a bit one thing from their store. I’d prefer to use some with the content material on my blog whether you don’t mind. Natually I’ll offer you a link in your internet blog. Thanks for sharing.
Thanks for sharing. I read many of your blog posts, cool, your blog is very good.
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me.
I really appreciate this post. I’ve been looking all over for this! Thank goodness I found it on Bing. You have made my day! Thanks again!
Thanks for sharing. I read many of your blog posts, cool, your blog is very good.
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me.
Your point of view caught my eye and was very interesting. Thanks. I have a question for you.
This clarified so much for me.
Your point of view caught my eye and was very interesting. Thanks. I have a question for you.
Your point of view caught my eye and was very interesting. Thanks. I have a question for you.
Your enticle helped me a lot, is there any more related content? Thanks!
Пехотный манипул попал в мешок, и если бы не врубилась с фланга кавалерийская турма, а командовал ею я, – тебе, философ, не пришлось бы разговаривать с Крысобоем. накрутка поведенческих факторов программа в москве скидка – Нарзану нету, – ответила женщина в будочке и почему-то обиделась.
аккаунт для рекламы магазин аккаунтов социальных сетей
маркетплейс для реселлеров маркетплейс аккаунтов соцсетей
аккаунты с балансом безопасная сделка аккаунтов
Санитары почему-то вытянули руки по швам и глаз не сводили с Ивана. взять микрозайм Над вами потешаться будут».
гарантия при продаже аккаунтов маркетплейс аккаунтов соцсетей
аккаунты с балансом площадка для продажи аккаунтов
Кожа на лице швейцара приняла тифозный оттенок, а глаза помертвели. разработка веб интерфейса – Теперь уж соловьи, наверно, поют.
маркетплейс для реселлеров купить аккаунт
» – тут же зачем-то очутился в кухне. сетка антипыльца купить Оставалось это продиктовать секретарю.
профиль с подписчиками безопасная сделка аккаунтов
продажа аккаунтов маркетплейс аккаунтов
магазин аккаунтов платформа для покупки аккаунтов
Анна Францевна де Фужере, пятидесятилетняя почтенная и очень деловая дама, три комнаты из пяти сдавала жильцам: одному, фамилия которого была, кажется, Беломут, и другому – с утраченной фамилией. перевод категорий водительских удостоверений между странами еаэс Словом, был гадкий, гнусный, соблазнительный, свинский скандал, который кончился лишь тогда, когда грузовик унес на себе от ворот Грибоедова несчастного Ивана Николаевича, милиционера, Пантелея и Рюхина.
В аллеях на скамейках появилась публика, но опять-таки на всех трех сторонах квадрата, кроме той, где были наши собеседники. нотариус Жулебино Он смерил Берлиоза взглядом, как будто собирался сшить ему костюм, сквозь зубы пробормотал что-то вроде: «Раз, два… Меркурий во втором доме… луна ушла… шесть – несчастье… вечер – семь…» – и громко и радостно объявил: – Вам отрежут голову! Бездомный дико и злобно вытаращил глаза на развязного неизвестного, а Берлиоз спросил, криво усмехнувшись: – А кто именно? Враги? Интервенты? – Нет, – ответил собеседник, – русская женщина, комсомолка.
Первая: «Он отнюдь не сумасшедший! Все это глупости!», и вторая: «Уж не подстроил ли он все это сам?!» Но, позвольте спросить, каким образом?! – Э нет! Это мы узнаем! Сделав над собой великое усилие, Иван Николаевич поднялся со скамьи и бросился назад, туда, где разговаривал с профессором. нотариус Лазарева – Я думаю, – странно усмехнувшись, ответил прокуратор, – что есть еще кое-кто на свете, кого тебе следовало бы пожалеть более, чем Иуду из Кириафа, и кому придется гораздо хуже, чем Иуде! Итак, Марк Крысобой, холодный и убежденный палач, люди, которые, как я вижу, – прокуратор указал на изуродованное лицо Иешуа, – тебя били за твои проповеди, разбойники Дисмас и Гестас, убившие со своими присными четырех солдат, и, наконец, грязный предатель Иуда – все они добрые люди? – Да, – ответил арестант.
платформа для покупки аккаунтов продать аккаунт
покупка аккаунтов продать аккаунт
биржа аккаунтов маркетплейс аккаунтов
– Вы по-русски здорово говорите, – заметил Бездомный. Краны управления КПП – Иван! – сконфузившись, шепнул Берлиоз.
аккаунты с балансом платформа для покупки аккаунтов
У этой двери также была очередь, но не чрезмерная, человек в полтораста. ремонт квартиры студии – А он сказал, что деньги ему отныне стали ненавистны, – объяснил Иешуа странные действия Левия Матвея и добавил: – И с тех пор он стал моим спутником.
маркетплейс аккаунтов купить аккаунт
продажа аккаунтов соцсетей kupit-akkaunt-top.ru/
площадка для продажи аккаунтов продажа аккаунтов соцсетей
Accounts marketplace Accounts market
Profitable Account Sales Account exchange
Secure Account Sales Buy Pre-made Account
Thanks for sharing. I read many of your blog posts, cool, your blog is very good.
Account Acquisition Buy accounts
Purchase Ready-Made Accounts Ready-Made Accounts for Sale
Secure Account Purchasing Platform Sell accounts
Account Trading Account Selling Platform
Database of Accounts for Sale Sell Account
Accounts market Buy Account
Find Accounts for Sale Verified Accounts for Sale
sell pre-made account sell pre-made account
gaming account marketplace account selling platform
buy and sell accounts https://socialaccountssale.com/
account exchange secure account sales
account store guaranteed accounts
secure account sales ready-made accounts for sale
account trading accounts market
account purchase sell account
online account store accounts market
account catalog social media account marketplace
guaranteed accounts sell pre-made account
social media account marketplace account trading platform
account marketplace account trading platform
account exchange buy accounts
Here to dive into discussions, share thoughts, and learn something new along the way.
I’m interested in hearing diverse viewpoints and sharing my input when it’s helpful. Happy to hear new ideas and meeting like-minded people.
Here’s my site:https://automisto24.com.ua/
verified accounts for sale profitable account sales
Just here to join conversations, share thoughts, and learn something new as I go.
I enjoy hearing diverse viewpoints and contributing whenever I can. Happy to hear different experiences and building connections.
That’s my site:https://automisto24.com.ua/
gaming account marketplace secure account purchasing platform
sell accounts buy pre-made account
Just here to dive into discussions, share experiences, and learn something new as I go.
I enjoy learning from different perspectives and adding to the conversation when possible. Interested in hearing fresh thoughts and building connections.
There’s my website:https://automisto24.com.ua/
Just here to join conversations, share experiences, and pick up new insights as I go.
I’m interested in learning from different perspectives and adding to the conversation when possible. Always open to fresh thoughts and meeting like-minded people.
That’s my website:https://automisto24.com.ua/
account buying platform account acquisition
account exchange service account purchase
account market account marketplace
ready-made accounts for sale account marketplace
buy accounts website for selling accounts
find accounts for sale website for buying accounts
account catalog secure account purchasing platform
account trading platform account exchange service
secure account sales buy and sell accounts
accounts market secure account sales
Your article helped me a lot, is there any more related content? Thanks!
sell account account marketplace
account exchange https://accounts-marketplace.xyz/
account acquisition https://buy-best-accounts.org
sell pre-made account https://social-accounts-marketplaces.live
account exchange https://accounts-marketplace.live/
ready-made accounts for sale https://social-accounts-marketplace.xyz
account buying platform https://buy-accounts.space
sell pre-made account https://buy-accounts-shop.pro
website for buying accounts https://social-accounts-marketplace.live
online account store accounts market
sell account buy accounts
marketplace for ready-made accounts https://accounts-marketplace-best.pro
маркетплейс аккаунтов https://akkaunty-na-prodazhu.pro/
площадка для продажи аккаунтов https://rynok-akkauntov.top/
площадка для продажи аккаунтов kupit-akkaunt.xyz
маркетплейс аккаунтов https://akkaunt-magazin.online
It?s arduous to seek out knowledgeable people on this matter, but you sound like you understand what you?re speaking about! Thanks
продать аккаунт https://akkaunty-market.live/
With every thing which appears to be developing within this particular subject material, a significant percentage of points of view are fairly exciting. Nonetheless, I beg your pardon, but I do not give credence to your whole theory, all be it exciting none the less. It would seem to us that your remarks are actually not entirely rationalized and in actuality you are yourself not really completely convinced of your point. In any case I did enjoy looking at it.
маркетплейс аккаунтов соцсетей https://kupit-akkaunty-market.xyz
площадка для продажи аккаунтов akkaunty-optom.live
маркетплейс аккаунтов соцсетей online-akkaunty-magazin.xyz
маркетплейс аккаунтов https://akkaunty-dlya-prodazhi.pro/
магазин аккаунтов https://kupit-akkaunt.online
buying facebook accounts https://buy-adsaccounts.work
buy facebook account for ads https://buy-ad-accounts.click
facebook ad accounts for sale https://buy-ad-account.top/
cheap facebook account facebook accounts to buy
facebook ads accounts facebook ads accounts
buy facebook ads manager https://buy-ads-account.work
Thank you for your sharing. I am worried that I lack creative ideas. It is your article that makes me full of hope. Thank you. But, I have a question, can you help me?
facebook accounts for sale https://ad-account-for-sale.top
facebook account sale https://buy-ad-account.click
Эта статья для ознакомления предлагает читателям общее представление об актуальной теме. Мы стремимся представить ключевые факты и идеи, которые помогут читателям получить представление о предмете и решить, стоит ли углубляться в изучение.
Углубиться в тему – https://medalkoblog.ru/
buy old facebook account for ads https://ad-accounts-for-sale.work/
google ads agency accounts buy old google ads account
buy google ads https://buy-ads-accounts.click
buy facebook ad accounts https://buy-accounts.click
adwords account for sale https://ads-account-for-sale.top
buy google ads verified account https://ads-account-buy.work
buy google ads threshold account https://buy-ads-invoice-account.top
buy verified google ads accounts https://buy-account-ads.work
google ads accounts for sale buy-ads-agency-account.top
buy google agency account https://sell-ads-account.click
buy adwords account buy verified google ads account
– Дайте нарзану, – попросил Берлиоз. срочный перевод документов с нотариальным заверением Но иностранец ничуть не обиделся и превесело рассмеялся.
facebook business account for sale buy facebook verified business account
«Надо будет ему возразить так, – решил Берлиоз, – да, человек смертен, никто против этого и не спорит. как самой раскрутить сайт Тот был уже у выхода в Патриарший переулок, и притом не один.
buy old google ads account https://buy-verified-ads-account.work
– Чем хочешь ты, чтобы я поклялся? – спросил, очень оживившись, развязанный. создание сайта вордпресс таймвеб Он был громадных размеров, червонного золота и на крышке его при открывании сверкнул синим и белым огнем бриллиантовый треугольник.
facebook business manager for sale buy-bm-account.org
buy verified bm buy business manager facebook
buy bm facebook buy bm facebook
buy facebook bm account buy-verified-business-manager.org
Я вообще начинаю опасаться, что путаница эта будет продолжаться очень долгое время. бюро переводов с нотариальным заверением в раменском Вот и я! Степа пощупал на стуле рядом с кроватью брюки, шепнул: – Извините… – надел их и хрипло спросил: – Скажите, пожалуйста, вашу фамилию? Говорить ему было трудно.
Эта статья предлагает захватывающий и полезный контент, который привлечет внимание широкого круга читателей. Мы постараемся представить тебе идеи, которые вдохновят вас на изменения в жизни и предоставят практические решения для повседневных вопросов. Читайте и вдохновляйтесь!
Получить дополнительную информацию – https://zaragozabikes.com/hello-world
Объяснимся: Степа Лиходеев, директор театра Варьете, очнулся утром у себя в той самой квартире, которую он занимал пополам с покойным Берлиозом, в большом шестиэтажном доме, покоем расположенном на Садовой улице. нотариальный перевод документов с иврита – Вот что, Миша, – зашептал поэт, оттащив Берлиоза в сторону, – он никакой не интурист, а шпион.
Ну, чего не знаем, за то не ручаемся. перевод паспорта с нотариальным рядом со мной цена заверением – Я думаю, – странно усмехнувшись, ответил прокуратор, – что есть еще кое-кто на свете, кого тебе следовало бы пожалеть более, чем Иуду из Кириафа, и кому придется гораздо хуже, чем Иуде! Итак, Марк Крысобой, холодный и убежденный палач, люди, которые, как я вижу, – прокуратор указал на изуродованное лицо Иешуа, – тебя били за твои проповеди, разбойники Дисмас и Гестас, убившие со своими присными четырех солдат, и, наконец, грязный предатель Иуда – все они добрые люди? – Да, – ответил арестант.
Задача врачей — не просто облегчить симптомы, а купировать осложнения, стабилизировать жизненно важные функции, вернуть пациенту способность к дальнейшему лечению. Мы работаем быстро, анонимно и профессионально. Любой человек, оказавшийся в кризисе, может получить помощь в течение часа после обращения.
Получить дополнительную информацию – https://snyatie-lomki-podolsk1.ru/snyatie-lomki-narkomana-v-podolske/
Необходимо незамедлительно обращаться за медицинской помощью, если у пациента наблюдаются следующие симптомы:
Получить дополнительную информацию – снятие наркологической ломки в новосибирске
Снятие ломки в клинике «Эдельвейс» – это комплекс мероприятий, направленный на быстрое облегчение симптоматики и стабилизацию внутренних процессов организма. Наш подход включает комплексную диагностику, медикаментозную терапию, поддерживающие процедуры и психологическое сопровождение, что помогает пациенту не только справиться с острой фазой ломки, но и закладывает основу для дальнейшей реабилитации и предотвращения рецидивов.
Подробнее тут – https://snyatie-lomki-ekb8.ru/snyatie-lomki-narkolog-v-ekb
Постановка капельницы от запоя проводится при наличии следующих клинических симптомов, свидетельствующих о критическом состоянии организма:
Подробнее – после капельницы от запоя новосибирск
buy fb business manager business-manager-for-sale.org
facebook business manager buy buy-business-manager-verified.org
Функция
Получить больше информации – снятие ломки наркомана нижний новгород
Зависимость — это системная проблема, которая требует последовательного и профессионального подхода. Обычные попытки «вылечиться дома» без медицинского сопровождения нередко заканчиваются срывами, ухудшением состояния и психологической деградацией. Клиника «Здоровье Плюс» в Балашихе предоставляет пациентам не просто разовое вмешательство, а выстроенную поэтапную программу, основанную на опыте и медицинских стандартах.
Подробнее тут – http://narkologicheskaya-pomoshch-balashiha1.ru/kruglosutochnaya-narkologicheskaya-pomoshch-v-balashihe/
Необходимо незамедлительно обращаться за медицинской помощью, если у пациента наблюдаются следующие симптомы:
Изучить вопрос глубже – снятие наркологической ломки
Процесс начинается с вызова врача или доставки пациента в клинику. После прибытия специалист проводит первичную диагностику: измерение давления, температуры, пульса, уровня кислорода в крови, визуальная оценка степени возбуждения или угнетения сознания. Собирается краткий анамнез: какой наркотик принимался, как долго, были ли сопутствующие заболевания.
Узнать больше – http://snyatie-lomki-podolsk1.ru
Наркологическая клиника «Эдельвейс» в Екатеринбурге специализируется на оказании оперативной и квалифицированной помощи при снятии ломки. Наши специалисты обладают многолетним опытом работы и применяют современные методики для безопасного и эффективного лечения абстинентного синдрома. Мы работаем круглосуточно, что позволяет оказывать помощь в любое время суток, обеспечивая анонимность и конфиденциальность каждого пациента.
Подробнее можно узнать тут – https://snyatie-lomki-ekb8.ru/snyatie-lomki-na-domu-v-ekb/
Капельница от запоя – эффективный метод экстренной детоксикации, который используется при тяжелых формах алкогольной интоксикации. Он позволяет быстро восстановить водно-электролитный баланс, нормализовать работу внутренних органов и снизить токсическую нагрузку. В клинике «Основа» мы гарантируем круглосуточное оказание медицинской помощи, индивидуальный подход к каждому пациенту и полную конфиденциальность. В условиях необходимости экстренного лечения наши специалисты оперативно выезжают в любую точку Новосибирска, обеспечивая комфортное проведение всех процедур как в стационаре, так и на дому.
Исследовать вопрос подробнее – https://kapelnica-ot-zapoya-novosibirsk8.ru/
facebook bm for sale https://buy-bm.org/
Стационарная программа позволяет стабилизировать не только физическое состояние, но и эмоциональную сферу. Находясь в изоляции от внешних раздражителей и вредных контактов, пациент получает шанс сконцентрироваться на себе и начать реабилитацию без давления извне.
Подробнее тут – наркологическая помощь на дому в балашихе
– «Ну и как?» – «В Ялту на месяц добился». джет мани микрофинанс контакты – На свете не было, нет и не будет никогда более великой и прекрасной для людей власти, чем власть императора Тиверия! – сорванный и больной голос Пилата разросся.
Необходимо незамедлительно обращаться за медицинской помощью, если у пациента наблюдаются следующие симптомы:
Получить дополнительную информацию – ломка от наркотиков
Врачи клиники «Импульс» используют комплексный подход, основанный на проверенных методиках и эффективных препаратах. Основные группы медикаментов, используемых при лечении на дому, представлены в таблице:
Детальнее – https://narcolog-na-dom-nnovgorod8.ru/vyzov-narkologa-na-dom-v-nnovgorode/
Необходимо незамедлительно обращаться за медицинской помощью, если у пациента наблюдаются следующие симптомы:
Ознакомиться с деталями – снятие ломки наркомана новосибирск
verified bm for sale verified-business-manager-for-sale.org
Также мы учитываем потребности каждого пациента — по питанию, условиям проживания, графику процедур. Проживание возможно в стандартных и повышенных палатах, с возможностью индивидуального обслуживания.
Выяснить больше – наркологическая помощь
Поэтому наша служба экстренного выезда работает круглосуточно. Медицинская бригада приезжает на вызов в любой район Балашихи в течение часа. Пациенту ставят капельницы, стабилизируют давление, снимают судорожный синдром и устраняют тревожность. Всё это проходит под наблюдением опытных врачей, которые ежедневно сталкиваются с острыми ситуациями и знают, как действовать быстро и безопасно.
Узнать больше – https://narkologicheskaya-pomoshch-balashiha1.ru/
Стационарная программа позволяет стабилизировать не только физическое состояние, но и эмоциональную сферу. Находясь в изоляции от внешних раздражителей и вредных контактов, пациент получает шанс сконцентрироваться на себе и начать реабилитацию без давления извне.
Узнать больше – http://narkologicheskaya-pomoshch-balashiha1.ru
Функция
Подробнее тут – snyat lomku nizhnij novgorod
Также мы учитываем потребности каждого пациента — по питанию, условиям проживания, графику процедур. Проживание возможно в стандартных и повышенных палатах, с возможностью индивидуального обслуживания.
Углубиться в тему – круглосуточная наркологическая помощь в балашихе
Стационарная программа позволяет стабилизировать не только физическое состояние, но и эмоциональную сферу. Находясь в изоляции от внешних раздражителей и вредных контактов, пациент получает шанс сконцентрироваться на себе и начать реабилитацию без давления извне.
Выяснить больше – narkologicheskaya pomoshch balashiha
– Ну вот видите, – продолжала Штурман, – что же делать? Естественно, что дачи получили наиболее талантливые из нас… – Генералы! – напрямик врезался в склоку Глухарев-сценарист. воздушный фильтр suzuki gs 500 Это русский эмигрант, перебравшийся к нам.
Осложнения, к которым может привести отсутствие лечения:
Получить дополнительные сведения – snyatie lomki narkozavisimogo podol’sk
Осложнения, к которым может привести отсутствие лечения:
Исследовать вопрос подробнее – снять ломку в подольске
Наркологическая клиника «Эдельвейс» в Екатеринбурге специализируется на оказании оперативной и квалифицированной помощи при снятии ломки. Наши специалисты обладают многолетним опытом работы и применяют современные методики для безопасного и эффективного лечения абстинентного синдрома. Мы работаем круглосуточно, что позволяет оказывать помощь в любое время суток, обеспечивая анонимность и конфиденциальность каждого пациента.
Подробнее можно узнать тут – http://snyatie-lomki-ekb8.ru/snyatie-lomki-narkolog-v-ekb/https://snyatie-lomki-ekb8.ru
Назначение
Получить больше информации – https://kapelnica-ot-zapoya-novosibirsk8.ru/
Стационарная программа позволяет стабилизировать не только физическое состояние, но и эмоциональную сферу. Находясь в изоляции от внешних раздражителей и вредных контактов, пациент получает шанс сконцентрироваться на себе и начать реабилитацию без давления извне.
Разобраться лучше – наркологическая помощь в балашихе
Ломка – это тяжелый синдром отмены, возникающий после длительного употребления алкоголя или наркотических веществ. При резком прекращении их приема нервная система и другие органы начинают страдать от недостатка необходимых веществ, что приводит к сильному дискомфорту, психоэмоциональным нарушениям и ухудшению общего состояния организма. В Новосибирске наркологическая клиника «Возрождение» оказывает экстренную помощь при снятии ломки, обеспечивая безопасное, круглосуточное и конфиденциальное лечение под наблюдением опытных специалистов.
Подробнее можно узнать тут – ломка от наркотиков
Снятие ломки в клинике «Эдельвейс» – это комплекс мероприятий, направленный на быстрое облегчение симптоматики и стабилизацию внутренних процессов организма. Наш подход включает комплексную диагностику, медикаментозную терапию, поддерживающие процедуры и психологическое сопровождение, что помогает пациенту не только справиться с острой фазой ломки, но и закладывает основу для дальнейшей реабилитации и предотвращения рецидивов.
Узнать больше – снятие ломок на дому в екатеринбурге
Группа препаратов
Получить дополнительные сведения – капельница от запоя новосибирская область
Осложнения, к которым может привести отсутствие лечения:
Разобраться лучше – ломка от наркотиков город
Задача врачей — не просто облегчить симптомы, а купировать осложнения, стабилизировать жизненно важные функции, вернуть пациенту способность к дальнейшему лечению. Мы работаем быстро, анонимно и профессионально. Любой человек, оказавшийся в кризисе, может получить помощь в течение часа после обращения.
Детальнее – http://snyatie-lomki-podolsk1.ru/
Клиника «Возрождение» применяет комплексный подход к снятию ломки, используя современные детоксикационные методики и проверенные препараты. Приведенная ниже таблица демонстрирует основные группы медикаментов, используемых в терапии, и их назначение:
Узнать больше – http://snyatie-lomki-novosibirsk8.ru
Степан наконец узнал трюмо и понял, что он лежит навзничь у себя на кровати, то есть на бывшей ювелиршиной кровати, в спальне. воздушный фильтр на suzuki gsx600f Это был командующий легионом легат.
Процесс лечения включает несколько ключевых этапов, каждый из которых имеет решающее значение для восстановления организма:
Получить дополнительную информацию – снятие наркотической ломки
В стационаре работают узкопрофильные специалисты: наркологи, неврологи, психотерапевты, а также персонал, обеспечивающий круглосуточный уход. Программа включает медикаментозное лечение, психологическую коррекцию, восстановление сна, устранение депрессии, обучение саморегуляции и работу с мотивацией.
Разобраться лучше – наркологическая помощь на дому балашиха
Клиника «НаркоМед Плюс» использует комплексный подход для эффективного снятия симптомов ломки с применением современных методов детоксикации и поддержки организма. Основные группы препаратов включают:
Углубиться в тему – снятие ломки в нижний новгороде
Именно поэтому так важно не терять время. Чем раньше пациент получает помощь, тем выше шансы избежать необратимых последствий и вернуться к нормальной жизни.
Получить дополнительные сведения – snyatie-lomki-podolsk1.ru/
Ломка – это острый синдром отмены, возникающий при резком прекращении или снижении дозы алкоголя или других психоактивных веществ у хронически зависимых пациентов. Это состояние характеризуется выраженной физической и психической дискомфортностью, которая может сопровождаться сильными болевыми ощущениями, тревожностью, дрожью, потливостью, галлюцинациями и нарушениями сна. В критический момент ломка может привести к серьезным осложнениям, поэтому экстренная помощь нарколога имеет первостепенное значение для стабилизации состояния пациента и быстрого снятия симптомов.
Изучить вопрос глубже – снять ломку
Каждый из этапов направлен на обеспечение максимальной безопасности и эффективности лечения. Индивидуальный подход, основанный на тщательной диагностике, позволяет значительно снизить риск осложнений и обеспечить комфортное протекание терапии.
Получить дополнительные сведения – снятие наркологической ломки
Назначение
Подробнее тут – капельница от запоя на дому новосибирск
Постановка капельницы от запоя проводится при наличии следующих клинических симптомов, свидетельствующих о критическом состоянии организма:
Ознакомиться с деталями – поставить капельницу от запоя
Процесс лечения включает несколько ключевых этапов, каждый из которых имеет решающее значение для восстановления организма:
Изучить вопрос глубже – снятие ломки в стационаре
Функция
Исследовать вопрос подробнее – снятие ломки наркомана
Зависимость — это системная проблема, которая требует последовательного и профессионального подхода. Обычные попытки «вылечиться дома» без медицинского сопровождения нередко заканчиваются срывами, ухудшением состояния и психологической деградацией. Клиника «Здоровье Плюс» в Балашихе предоставляет пациентам не просто разовое вмешательство, а выстроенную поэтапную программу, основанную на опыте и медицинских стандартах.
Исследовать вопрос подробнее – неотложная наркологическая помощь балашиха
Стационарная программа позволяет стабилизировать не только физическое состояние, но и эмоциональную сферу. Находясь в изоляции от внешних раздражителей и вредных контактов, пациент получает шанс сконцентрироваться на себе и начать реабилитацию без давления извне.
Получить дополнительные сведения – наркологическая помощь в балашихе
facebook business manager for sale https://buy-business-manager-accounts.org
Наркологическая клиника «Эдельвейс» в Екатеринбурге специализируется на оказании оперативной и квалифицированной помощи при снятии ломки. Наши специалисты обладают многолетним опытом работы и применяют современные методики для безопасного и эффективного лечения абстинентного синдрома. Мы работаем круглосуточно, что позволяет оказывать помощь в любое время суток, обеспечивая анонимность и конфиденциальность каждого пациента.
Исследовать вопрос подробнее – снятие ломки наркозависимого в екатеринбурге
tiktok agency account for sale https://buy-tiktok-ads-account.org
Ломка – это тяжелый синдром отмены, возникающий после длительного употребления алкоголя или наркотических веществ. При резком прекращении их приема нервная система и другие органы начинают страдать от недостатка необходимых веществ, что приводит к сильному дискомфорту, психоэмоциональным нарушениям и ухудшению общего состояния организма. В Новосибирске наркологическая клиника «Возрождение» оказывает экстренную помощь при снятии ломки, обеспечивая безопасное, круглосуточное и конфиденциальное лечение под наблюдением опытных специалистов.
Выяснить больше – https://snyatie-lomki-novosibirsk8.ru/snyatie-lomki-na-domu-v-novosibirske
Ломка – это тяжелый синдром отмены, возникающий после длительного употребления алкоголя или наркотических веществ. При резком прекращении их приема нервная система и другие органы начинают страдать от недостатка необходимых веществ, что приводит к сильному дискомфорту, психоэмоциональным нарушениям и ухудшению общего состояния организма. В Новосибирске наркологическая клиника «Возрождение» оказывает экстренную помощь при снятии ломки, обеспечивая безопасное, круглосуточное и конфиденциальное лечение под наблюдением опытных специалистов.
Получить больше информации – snyatie-lomki-novosibirsk8.ru/
tiktok ads account buy https://tiktok-ads-account-buy.org
В это время в колоннаду стремительно влетела ласточка, сделала под золотым потолком круг, снизилась, чуть не задела острым крылом лица медной статуи в нише и скрылась за капителью колонны. мфк займер кемерово адрес – Да, пожалуй, немец… – сказал он.
В стационаре работают узкопрофильные специалисты: наркологи, неврологи, психотерапевты, а также персонал, обеспечивающий круглосуточный уход. Программа включает медикаментозное лечение, психологическую коррекцию, восстановление сна, устранение депрессии, обучение саморегуляции и работу с мотивацией.
Подробнее тут – https://narkologicheskaya-pomoshch-balashiha1.ru/narkologicheskaya-pomoshch-na-domu-v-balashihe/
Ломка – это тяжелый синдром отмены, возникающий после длительного употребления алкоголя или наркотических веществ. При резком прекращении их приема нервная система и другие органы начинают страдать от недостатка необходимых веществ, что приводит к сильному дискомфорту, психоэмоциональным нарушениям и ухудшению общего состояния организма. В Новосибирске наркологическая клиника «Возрождение» оказывает экстренную помощь при снятии ломки, обеспечивая безопасное, круглосуточное и конфиденциальное лечение под наблюдением опытных специалистов.
Углубиться в тему – https://snyatie-lomki-novosibirsk8.ru/snyatie-lomki-na-domu-v-novosibirske/
Для обеспечения максимальной безопасности и эффективности лечения процесс организован в несколько этапов. При обращении пациента наши специалисты проводят первичный осмотр и диагностику, чтобы оценить степень интоксикации и выявить возможные осложнения. Далее назначается детоксикационная терапия, сопровождаемая медикаментозной поддержкой и психологическим консультированием. Основные этапы работы можно описать следующим образом:
Разобраться лучше – вывод из запоя екатеринбург
Эта информационная статья охватывает широкий спектр актуальных тем и вопросов. Мы стремимся осветить ключевые факты и события с ясностью и простотой, чтобы каждый читатель мог извлечь из нее полезные знания и полезные инсайты.
Углубиться в тему – https://culturatijucatenis.com.br/eventos/show-de-gabby-moura
Эта публикация завернет вас в вихрь увлекательного контента, сбрасывая стереотипы и открывая двери к новым идеям. Каждый абзац станет для вас открытием, полным ярких примеров и впечатляющих достижений. Подготовьтесь быть вовлеченными и удивленными каждый раз, когда продолжите читать.
Разобраться лучше – https://nordzentren.de/nordzentren-starten-mit-700-000-e-fuer-gruendungsunterstuetzung-durch-735
В этой статье-обзоре мы соберем актуальную информацию и интересные факты, которые освещают важные темы. Читатели смогут ознакомиться с различными мнениями и подходами, что позволит им расширить кругозор и глубже понять обсуждаемые вопросы.
Детальнее – https://bodinjonas.se/cropped-jonas-bodin-png
В этой статье представлен занимательный и актуальный контент, который заставит вас задуматься. Мы обсуждаем насущные вопросы и проблемы, а также освещаем истории, которые вдохновляют на действия и изменения. Узнайте, что стоит за событиями нашего времени!
Подробнее тут – https://kangaroohn.vn/co-nen-uong-nuoc-truoc-khi-di-ngu-hay-nghe-chuyen-gia-tra-loi
В этой публикации мы сосредоточимся на интересных аспектах одной из самых актуальных тем современности. Совмещая факты и мнения экспертов, мы создадим полное представление о предмете, которое будет полезно как новичкам, так и тем, кто глубоко изучает вопрос.
Выяснить больше – https://medicons.hu/fashion-picks
В этой статье-обзоре мы соберем актуальную информацию и интересные факты, которые освещают важные темы. Читатели смогут ознакомиться с различными мнениями и подходами, что позволит им расширить кругозор и глубже понять обсуждаемые вопросы.
Детальнее – https://www.dewdropdays.com/2018/12/15/christlike
Этот информативный текст отличается привлекательным содержанием и актуальными данными. Мы предлагаем читателям взглянуть на привычные вещи под новым углом, предоставляя интересный и доступный материал. Получите удовольствие от чтения и расширьте кругозор!
Детальнее – https://theoxygenplan.com/companies-combat-mental-illness-mobile-apps
Бескудников стукнул пальцем по циферблату, показал его соседу, поэту Двубратскому, сидящему на столе и от тоски болтающему ногами, обутыми в желтые туфли на резиновом ходу. как оплатить kredito24 – Как? Вы и фамилию мою забыли? – тут неизвестный улыбнулся.
Этот информативный текст выделяется своими захватывающими аспектами, которые делают сложные темы доступными и понятными. Мы стремимся предложить читателям глубину знаний вместе с разнообразием интересных фактов. Откройте новые горизонты и развивайте свои способности познавать мир!
Получить дополнительную информацию – https://www.workingcode.in/2023/06/27/use-case-ansible-integration-via-flow-designer-servicenow
В этой информационной статье вы найдете интересное содержание, которое поможет вам расширить свои знания. Мы предлагаем увлекательный подход и уникальные взгляды на обсуждаемые темы, побуждая пользователей к активному мышлению и критическому анализу!
Детальнее – https://feteops.com/startup-of-the-week-writemapper
Клиника «Возрождение» применяет комплексный подход к снятию ломки, используя современные детоксикационные методики и проверенные препараты. Приведенная ниже таблица демонстрирует основные группы медикаментов, используемых в терапии, и их назначение:
Узнать больше – ломка от наркотиков город
— Я тоже знаю, что она еще будет, — ответил Пилат, — своими словами ты меня не удивил. замена уплотнителя на окнах в зеленограде Из-за опушки выехал дравшийся охотник с лисицей в тороках и подъехал к молодому барину.
После поступления звонка врач клиники «Импульс» незамедлительно отправляется на указанный адрес для оказания срочной помощи. Вызов врача на дом включает следующие этапы:
Исследовать вопрос подробнее – вызов нарколога на дом нижегородская область
Процесс начинается с вызова врача или доставки пациента в клинику. После прибытия специалист проводит первичную диагностику: измерение давления, температуры, пульса, уровня кислорода в крови, визуальная оценка степени возбуждения или угнетения сознания. Собирается краткий анамнез: какой наркотик принимался, как долго, были ли сопутствующие заболевания.
Разобраться лучше – https://snyatie-lomki-podolsk1.ru/
Ломка — это острый синдром отмены, возникающий после длительного употребления алкоголя или наркотических веществ. При резком прекращении приема подобных веществ организм испытывает острую нехватку необходимых компонентов, что приводит к развитию тяжелых симптомов, таких как сильная тревожность, бессонница, мышечные судороги, головокружение, потливость и повышенная возбудимость. В такой критической ситуации быстрое и квалифицированное вмешательство врача-нарколога является залогом сохранения здоровья и предупреждения серьезных осложнений.
Получить дополнительную информацию – http://snyatie-lomki-nnovgorod8.ru/
Современный темп жизни нередко приводит к ситуации, когда человеку, страдающему от алкогольной или наркотической зависимости, срочно требуется профессиональная медицинская помощь. Особенно актуально это в тех случаях, когда состояние пациента резко ухудшается и поездка в клинику становится невозможной или нежелательной из-за повышенного уровня тревожности. Наркологическая клиника «Импульс» предлагает услугу вызова нарколога на дом в Нижнем Новгороде, обеспечивая круглосуточную помощь на высоком профессиональном уровне. Такое решение позволяет избежать серьезных осложнений и обеспечить комфортные условия лечения в привычной обстановке.
Получить дополнительные сведения – вызов врача нарколога на дом
Симптоматика ломки может варьироваться: от бессонницы, сильной тревожности и раздражительности до выраженных физически болезненных ощущений, таких как мышечные спазмы, судороги, потливость, головокружение и тошнота. В критических ситуациях, когда симптомы достигают остроты, своевременная медицинская помощь становится жизненно необходимой для предотвращения осложнений и стабилизации состояния пациента.
Изучить вопрос глубже – снятие ломки на дому новосибирская область
Клиника «Возрождение» применяет комплексный подход к снятию ломки, используя современные детоксикационные методики и проверенные препараты. Приведенная ниже таблица демонстрирует основные группы медикаментов, используемых в терапии, и их назначение:
Изучить вопрос глубже – снятие ломки в стационаре
Симптоматика ломки может варьироваться: от бессонницы, сильной тревожности и раздражительности до выраженных физически болезненных ощущений, таких как мышечные спазмы, судороги, потливость, головокружение и тошнота. В критических ситуациях, когда симптомы достигают остроты, своевременная медицинская помощь становится жизненно необходимой для предотвращения осложнений и стабилизации состояния пациента.
Углубиться в тему – снятие наркологической ломки на дому в новосибирске
Ломка – это тяжелый синдром отмены, возникающий после длительного употребления алкоголя или наркотических веществ. При резком прекращении их приема нервная система и другие органы начинают страдать от недостатка необходимых веществ, что приводит к сильному дискомфорту, психоэмоциональным нарушениям и ухудшению общего состояния организма. В Новосибирске наркологическая клиника «Возрождение» оказывает экстренную помощь при снятии ломки, обеспечивая безопасное, круглосуточное и конфиденциальное лечение под наблюдением опытных специалистов.
Получить дополнительную информацию – снятие ломок новосибирск
Симптоматика ломки может варьироваться: от бессонницы, сильной тревожности и раздражительности до выраженных физически болезненных ощущений, таких как мышечные спазмы, судороги, потливость, головокружение и тошнота. В критических ситуациях, когда симптомы достигают остроты, своевременная медицинская помощь становится жизненно необходимой для предотвращения осложнений и стабилизации состояния пациента.
Получить дополнительную информацию – снятие ломки в стационаре
«Нет, он не англичанин…» – подумал Берлиоз, а Бездомный подумал: «Где это он так наловчился говорить по-русски, вот что интересно!» – и опять нахмурился. замена уплотнителей окон уаз буханка Примерно так успокаивал себя Славка, но падение в никуда длилось и длилось.
Для обеспечения максимальной безопасности и эффективности лечения процесс организован в несколько этапов. При обращении пациента наши специалисты проводят первичный осмотр и диагностику, чтобы оценить степень интоксикации и выявить возможные осложнения. Далее назначается детоксикационная терапия, сопровождаемая медикаментозной поддержкой и психологическим консультированием. Основные этапы работы можно описать следующим образом:
Ознакомиться с деталями – срочный вывод из запоя
Для обеспечения максимальной безопасности и эффективности лечения процесс организован в несколько этапов. При обращении пациента наши специалисты проводят первичный осмотр и диагностику, чтобы оценить степень интоксикации и выявить возможные осложнения. Далее назначается детоксикационная терапия, сопровождаемая медикаментозной поддержкой и психологическим консультированием. Основные этапы работы можно описать следующим образом:
Разобраться лучше – https://vyvod-iz-zapoya-ekb8.ru/
Ломка — это острый синдром отмены, возникающий после длительного употребления алкоголя или наркотических веществ. При резком прекращении приема подобных веществ организм испытывает острую нехватку необходимых компонентов, что приводит к развитию тяжелых симптомов, таких как сильная тревожность, бессонница, мышечные судороги, головокружение, потливость и повышенная возбудимость. В такой критической ситуации быстрое и квалифицированное вмешательство врача-нарколога является залогом сохранения здоровья и предупреждения серьезных осложнений.
Разобраться лучше – ломка от наркотиков
Каждый из этапов направлен на обеспечение максимальной безопасности и эффективности лечения. Индивидуальный подход, основанный на тщательной диагностике, позволяет значительно снизить риск осложнений и обеспечить комфортное протекание терапии.
Углубиться в тему – снятие ломки наркозависимого екатеринбург
buy tiktok business account https://tiktok-ads-account-for-sale.org
buy tiktok ads account https://tiktok-agency-account-for-sale.org
Абстинентный синдром — одно из самых тяжёлых и опасных проявлений наркотической зависимости. Он развивается на фоне резкого отказа от приёма веществ и сопровождается сильнейшими нарушениями работы организма. Это состояние требует немедленного вмешательства. Самостоятельно справиться с ним невозможно — особенно если речь идёт о героине, метадоне, синтетических наркотиках или длительной зависимости. В клинике «НаркоПрофи» мы организовали систему снятия ломки в Подольске, работающую круглосуточно: как на дому, так и в условиях стационара.
Выяснить больше – https://snyatie-lomki-podolsk1.ru/snyatie-lomki-narkomana-v-podolske
Для обеспечения максимальной безопасности и эффективности лечения процесс организован в несколько этапов. При обращении пациента наши специалисты проводят первичный осмотр и диагностику, чтобы оценить степень интоксикации и выявить возможные осложнения. Далее назначается детоксикационная терапия, сопровождаемая медикаментозной поддержкой и психологическим консультированием. Основные этапы работы можно описать следующим образом:
Получить дополнительные сведения – вывод из запоя в стационаре
tiktok ad accounts https://buy-tiktok-ad-account.org
При наличии этих симптомов организм находится в критическом состоянии, и любой промедление с вызовом врача может привести к развитию серьезных осложнений, таких как сердечно-сосудистые нарушения, тяжелые неврологические симптомы или даже жизнеугрожающие состояния. Экстренное вмешательство позволяет не только снять острые симптомы ломки, но и предотвратить необратимые изменения в организме.
Ознакомиться с деталями – снятие ломки новосибирск.
Процесс начинается с вызова врача или доставки пациента в клинику. После прибытия специалист проводит первичную диагностику: измерение давления, температуры, пульса, уровня кислорода в крови, визуальная оценка степени возбуждения или угнетения сознания. Собирается краткий анамнез: какой наркотик принимался, как долго, были ли сопутствующие заболевания.
Подробнее – снятие ломок на дому в подольске
Именно поэтому так важно не терять время. Чем раньше пациент получает помощь, тем выше шансы избежать необратимых последствий и вернуться к нормальной жизни.
Узнать больше – снятие ломки наркомана подольск
А ты, когда вязанием занята, чуть не носом утыкаешься. цена на москитную сетку пластиковые окна Воланд в сорочке сидел на постели, и только Гелла не растирала ему ногу, а на столе, там, где раньше играли в шахматы, накрывала ужин.
Снятие ломки в клинике «Эдельвейс» – это комплекс мероприятий, направленный на быстрое облегчение симптоматики и стабилизацию внутренних процессов организма. Наш подход включает комплексную диагностику, медикаментозную терапию, поддерживающие процедуры и психологическое сопровождение, что помогает пациенту не только справиться с острой фазой ломки, но и закладывает основу для дальнейшей реабилитации и предотвращения рецидивов.
Подробнее можно узнать тут – http://snyatie-lomki-ekb8.ru/
Задача врачей — не просто облегчить симптомы, а купировать осложнения, стабилизировать жизненно важные функции, вернуть пациенту способность к дальнейшему лечению. Мы работаем быстро, анонимно и профессионально. Любой человек, оказавшийся в кризисе, может получить помощь в течение часа после обращения.
Узнать больше – https://snyatie-lomki-podolsk1.ru/
Абстинентный синдром — одно из самых тяжёлых и опасных проявлений наркотической зависимости. Он развивается на фоне резкого отказа от приёма веществ и сопровождается сильнейшими нарушениями работы организма. Это состояние требует немедленного вмешательства. Самостоятельно справиться с ним невозможно — особенно если речь идёт о героине, метадоне, синтетических наркотиках или длительной зависимости. В клинике «НаркоПрофи» мы организовали систему снятия ломки в Подольске, работающую круглосуточно: как на дому, так и в условиях стационара.
Получить дополнительные сведения – https://snyatie-lomki-podolsk1.ru/snyatie-lomki-narkolog-v-podolske/
Абстинентный синдром — одно из самых тяжёлых и опасных проявлений наркотической зависимости. Он развивается на фоне резкого отказа от приёма веществ и сопровождается сильнейшими нарушениями работы организма. Это состояние требует немедленного вмешательства. Самостоятельно справиться с ним невозможно — особенно если речь идёт о героине, метадоне, синтетических наркотиках или длительной зависимости. В клинике «НаркоПрофи» мы организовали систему снятия ломки в Подольске, работающую круглосуточно: как на дому, так и в условиях стационара.
Разобраться лучше – http://www.domen.ru
Клиника «Возрождение» применяет комплексный подход к снятию ломки, используя современные детоксикационные методики и проверенные препараты. Приведенная ниже таблица демонстрирует основные группы медикаментов, используемых в терапии, и их назначение:
Получить дополнительные сведения – снятие наркологической ломки новосибирск
Срочный вызов врача на дом необходим при появлении следующих симптомов:
Детальнее – vyzov-narkologa-na-dom nizhnij novgorod
Процесс лечения включает несколько ключевых этапов, каждый из которых имеет решающее значение для восстановления организма:
Разобраться лучше – http://snyatie-lomki-novosibirsk8.ru
Абстинентный синдром — одно из самых тяжёлых и опасных проявлений наркотической зависимости. Он развивается на фоне резкого отказа от приёма веществ и сопровождается сильнейшими нарушениями работы организма. Это состояние требует немедленного вмешательства. Самостоятельно справиться с ним невозможно — особенно если речь идёт о героине, метадоне, синтетических наркотиках или длительной зависимости. В клинике «НаркоПрофи» мы организовали систему снятия ломки в Подольске, работающую круглосуточно: как на дому, так и в условиях стационара.
Подробнее можно узнать тут – снятие ломки на дому недорого подольск
Абстинентный синдром — одно из самых тяжёлых и опасных проявлений наркотической зависимости. Он развивается на фоне резкого отказа от приёма веществ и сопровождается сильнейшими нарушениями работы организма. Это состояние требует немедленного вмешательства. Самостоятельно справиться с ним невозможно — особенно если речь идёт о героине, метадоне, синтетических наркотиках или длительной зависимости. В клинике «НаркоПрофи» мы организовали систему снятия ломки в Подольске, работающую круглосуточно: как на дому, так и в условиях стационара.
Исследовать вопрос подробнее – snyatie lomki narkozavisimogo podol’sk
Детоксикационные растворы (физиологический раствор, глюкоза, раствор Рингера)
Ознакомиться с деталями – vyvod-iz-zapoya-kruglosutochno ekaterinburg
Назначение и действие
Подробнее можно узнать тут – нарколог на дом нижний новгород.
Функция
Узнать больше – снятие наркологической ломки на дому в нижний новгороде
buy tiktok business account https://buy-tiktok-ads-accounts.org
– Здесь люди бог знает что могут подумать, – бормотал Телянин, схватывая фуражку и направляясь в небольшую пустую комнату, – надо объясниться… – Я это знаю, и я это докажу, – сказал Ростов. москитная сетка на пластиковые окна заклеить Над дверью висел фонарь.
После поступления звонка врач клиники «Импульс» незамедлительно отправляется на указанный адрес для оказания срочной помощи. Вызов врача на дом включает следующие этапы:
Ознакомиться с деталями – выезд нарколога на дом
После поступления звонка врач клиники «Импульс» незамедлительно отправляется на указанный адрес для оказания срочной помощи. Вызов врача на дом включает следующие этапы:
Разобраться лучше – нарколог на дом в нижний новгороде
Наркологическая клиника «НаркоМед Плюс» в Нижнем Новгороде оказывает экстренную помощь при снятии ломки. Наша команда высококвалифицированных специалистов готова круглосуточно выехать на дом или принять пациента в клинике, обеспечивая оперативное, безопасное и полностью конфиденциальное лечение. Мы разрабатываем индивидуальные программы терапии, учитывая историю зависимости и текущее состояние каждого пациента, что позволяет быстро стабилизировать его состояние и начать процесс полного выздоровления.
Получить дополнительные сведения – снятие наркологической ломки на дому
Симптоматика ломки может варьироваться: от бессонницы, сильной тревожности и раздражительности до выраженных физически болезненных ощущений, таких как мышечные спазмы, судороги, потливость, головокружение и тошнота. В критических ситуациях, когда симптомы достигают остроты, своевременная медицинская помощь становится жизненно необходимой для предотвращения осложнений и стабилизации состояния пациента.
Разобраться лучше – снятие ломки на дому новосибирск
Необходимо незамедлительно обращаться за медицинской помощью, если у пациента наблюдаются следующие симптомы:
Разобраться лучше – снятие ломки на дому новосибирская область
Алкогольный запой представляет собой крайне опасное состояние, когда организм переполнен токсинами, а системы внутреннего контроля практически перестают функционировать должным образом. Наркологическая клиника «Трезвая Жизнь» в Екатеринбурге оказывает экстренную помощь при выводе из запоя, используя передовые методы диагностики, детоксикации и поддерживающую терапию. Наша команда опытных врачей-наркологов готова оказать помощь в любое время суток, обеспечивая оперативное вмешательство и строгую анонимность каждого пациента.
Детальнее – http://vyvod-iz-zapoya-ekb8.ru
Процесс начинается с вызова врача или доставки пациента в клинику. После прибытия специалист проводит первичную диагностику: измерение давления, температуры, пульса, уровня кислорода в крови, визуальная оценка степени возбуждения или угнетения сознания. Собирается краткий анамнез: какой наркотик принимался, как долго, были ли сопутствующие заболевания.
Подробнее тут – снятие ломок на дому
Наши специалисты оказывают экстренную помощь по четко отработанной методике, главная задача которой – оперативное снятие симптомов острой интоксикации и абстинентного синдрома, восстановление работы внутренних органов и создание оптимальных условий для последующей реабилитации. Опытный нарколог на дому проведет тщательную диагностику, составит индивидуальный план лечения и даст необходимые рекомендации по дальнейшему выздоровлению.
Углубиться в тему – вызов нарколога на дом
Для обеспечения максимальной безопасности и эффективности лечения процесс организован в несколько этапов. При обращении пациента наши специалисты проводят первичный осмотр и диагностику, чтобы оценить степень интоксикации и выявить возможные осложнения. Далее назначается детоксикационная терапия, сопровождаемая медикаментозной поддержкой и психологическим консультированием. Основные этапы работы можно описать следующим образом:
Подробнее тут – вывод из запоя клиника в екатеринбурге
Процесс начинается с вызова врача или доставки пациента в клинику. После прибытия специалист проводит первичную диагностику: измерение давления, температуры, пульса, уровня кислорода в крови, визуальная оценка степени возбуждения или угнетения сознания. Собирается краткий анамнез: какой наркотик принимался, как долго, были ли сопутствующие заболевания.
Получить больше информации – снятие ломки на дому подольск
Ломка — это острый синдром отмены, возникающий после длительного употребления алкоголя или наркотических веществ. При резком прекращении приема подобных веществ организм испытывает острую нехватку необходимых компонентов, что приводит к развитию тяжелых симптомов, таких как сильная тревожность, бессонница, мышечные судороги, головокружение, потливость и повышенная возбудимость. В такой критической ситуации быстрое и квалифицированное вмешательство врача-нарколога является залогом сохранения здоровья и предупреждения серьезных осложнений.
Узнать больше – снятие ломки на дому в нижний новгороде
Именно поэтому так важно не терять время. Чем раньше пациент получает помощь, тем выше шансы избежать необратимых последствий и вернуться к нормальной жизни.
Ознакомиться с деталями – снятие ломки на дому московская область
Ломка — это острый синдром отмены, возникающий после длительного употребления алкоголя или наркотических веществ. При резком прекращении приема подобных веществ организм испытывает острую нехватку необходимых компонентов, что приводит к развитию тяжелых симптомов, таких как сильная тревожность, бессонница, мышечные судороги, головокружение, потливость и повышенная возбудимость. В такой критической ситуации быстрое и квалифицированное вмешательство врача-нарколога является залогом сохранения здоровья и предупреждения серьезных осложнений.
Исследовать вопрос подробнее – http://snyatie-lomki-nnovgorod8.ru/snyatie-narkoticheskoj-lomki-v-nnovgorode/https://snyatie-lomki-nnovgorod8.ru
Абстинентный синдром — одно из самых тяжёлых и опасных проявлений наркотической зависимости. Он развивается на фоне резкого отказа от приёма веществ и сопровождается сильнейшими нарушениями работы организма. Это состояние требует немедленного вмешательства. Самостоятельно справиться с ним невозможно — особенно если речь идёт о героине, метадоне, синтетических наркотиках или длительной зависимости. В клинике «НаркоПрофи» мы организовали систему снятия ломки в Подольске, работающую круглосуточно: как на дому, так и в условиях стационара.
Разобраться лучше – http://snyatie-lomki-podolsk1.ru/snyatie-lomki-narkolog-v-podolske/
Детоксикационные растворы (физиологический раствор, глюкоза, раствор Рингера)
Углубиться в тему – вывод из запоя на дому в екатеринбурге
Дисковидная посудина изнутри смотрелась кукольным домиком. пластиковые окна жалюзи москитные сетки – Шшшш! – зашикал граф и обратился к Семену.
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Детальнее – https://meadowsnurseries.com/squirrel_news/squirrels-news-september-2014
Этот интересный отчет представляет собой сборник полезных фактов, касающихся актуальных тем. Мы проанализируем данные, чтобы вы могли сделать обоснованные выводы. Читайте, чтобы узнать больше о последних трендах и значимых событиях!
Подробнее можно узнать тут – http://tomasroubal.com/domains/tomasroubal.com/ahoj-vsichni
Наркологическая клиника «Эдельвейс» в Екатеринбурге специализируется на оказании оперативной и квалифицированной помощи при снятии ломки. Наши специалисты обладают многолетним опытом работы и применяют современные методики для безопасного и эффективного лечения абстинентного синдрома. Мы работаем круглосуточно, что позволяет оказывать помощь в любое время суток, обеспечивая анонимность и конфиденциальность каждого пациента.
Разобраться лучше – http://snyatie-lomki-ekb8.ru
Этот интересный отчет представляет собой сборник полезных фактов, касающихся актуальных тем. Мы проанализируем данные, чтобы вы могли сделать обоснованные выводы. Читайте, чтобы узнать больше о последних трендах и значимых событиях!
Получить больше информации – https://silverstool.org/blog/tips-to-succeed-in-an-online-course
Эта статья сочетает в себе как полезные, так и интересные сведения, которые обогатят ваше понимание насущных тем. Мы предлагаем практические советы и рекомендации, которые легко внедрить в повседневную жизнь. Узнайте, как улучшить свои навыки и обогатить свой опыт с помощью простых, но эффективных решений.
Ознакомиться с деталями – https://alhikmaofficial.com/ju-kujtohet-bukuroshja-kandi-tek-seriali-spanjoll-ja-si-duket-ajo-sot-dhe-sa-femije-paska-foto
Эта статья предлагает живое освещение актуальной темы с множеством интересных фактов. Мы рассмотрим ключевые моменты, которые делают данную тему важной и актуальной. Подготовьтесь к насыщенному путешествию по неизвестным аспектам и узнайте больше о значимых событиях.
Ознакомиться с деталями – https://vsichkoelichno.com/product/i-like-it-here-mug-blue
Эта статья для ознакомления предлагает читателям общее представление об актуальной теме. Мы стремимся представить ключевые факты и идеи, которые помогут читателям получить представление о предмете и решить, стоит ли углубляться в изучение.
Подробнее – http://www.vinhadareia.com/2013/05/24/integer-quis-ligula-ipsum-sit-amet-scelerisque
Его – Ярослав Быстров. заказать новые москитные сетки на пластиковые окна На Сокола.
Этот информативный текст отличается привлекательным содержанием и актуальными данными. Мы предлагаем читателям взглянуть на привычные вещи под новым углом, предоставляя интересный и доступный материал. Получите удовольствие от чтения и расширьте кругозор!
Углубиться в тему – https://istitchdigitizing.com/2023/04/09/revolutionize-your-business-with-our-cutting-edge
Эта статья для ознакомления предлагает читателям общее представление об актуальной теме. Мы стремимся представить ключевые факты и идеи, которые помогут читателям получить представление о предмете и решить, стоит ли углубляться в изучение.
Исследовать вопрос подробнее – http://pesisirnasional.com/empat-unit-ruko-di-pasar-teluk-belitung-hangus-terbakar
Каждый врач клиники обладает глубокими знаниями в области фармакологии, психофармакологии и психотерапии. Они регулярно посещают профессиональные конференции, семинары и мастер-классы, чтобы быть в курсе последних достижений в лечении зависимостей. Такой подход позволяет нашим специалистам применять наиболее эффективные и научно обоснованные методы терапии.
Подробнее можно узнать тут – https://алко-лечение24.рф/vivod-iz-zapoya-cena-v-Sankt-Peterburge/
Ломка — это не временное недомогание. Это системное разрушение организма, связанное с тем, что он перестаёт получать наркотик, к которому уже привык. Нарушается обмен веществ, функции сердца, печени, почек, теряется контроль над эмоциями и болью. В состоянии абстиненции человек не может спать, есть, адекватно мыслить. Страдает и тело, и психика.
Углубиться в тему – https://snyatie-lomki-podolsk1.ru
Миссия клиники “Путь к выздоровлению” заключается в содействии восстановлению здоровья и социальной реинтеграции людей, столкнувшихся с проблемами зависимости. Мы стремимся к комплексному решению этой сложной задачи, учитывая физические, психологические и социальные аспекты зависимости. Наша цель — не только помочь пациентам избавиться от физической зависимости, но и обеспечить их психологическое восстановление и возвращение к нормальной жизни в обществе.
Узнать больше – http://нарко-фильтр.рф
Каждый врач клиники обладает глубокими знаниями в области фармакологии, психофармакологии и психотерапии. Они регулярно посещают профессиональные конференции, семинары и мастер-классы, чтобы быть в курсе последних достижений в лечении зависимостей. Такой подход позволяет нашим специалистам применять наиболее эффективные и научно обоснованные методы терапии.
Подробнее можно узнать тут – http://нарко-фильтр.рф
Постановка капельницы от запоя проводится при наличии следующих клинических симптомов, свидетельствующих о критическом состоянии организма:
Получить больше информации – http://kapelnica-ot-zapoya-novosibirsk8.ru
Процесс лечения капельничным методом от запоя организован по четко структурированной схеме, позволяющей обеспечить оперативное и безопасное восстановление организма.
Разобраться лучше – вызвать капельницу от запоя на дому
Задача врачей — не просто облегчить симптомы, а купировать осложнения, стабилизировать жизненно важные функции, вернуть пациенту способность к дальнейшему лечению. Мы работаем быстро, анонимно и профессионально. Любой человек, оказавшийся в кризисе, может получить помощь в течение часа после обращения.
Получить больше информации – http://snyatie-lomki-podolsk1.ru/snyatie-lomki-narkomana-v-podolske/
Наркологическая клиника “Путь к выздоровлению” — специализированное медицинское учреждение, предназначенное для оказания помощи лицам, страдающим от алкогольной и наркотической зависимости. Наша основная задача — предоставить эффективные методы лечения и поддержку, чтобы помочь пациентам преодолеть пагубное пристрастие и вернуть их к здоровой и полноценной жизни.
Подробнее можно узнать тут – https://нарко-фильтр.рф/vivod-iz-zapoya-v-kruglosutochno-v-rostove-na-donu
Самолечение или попытка «переждать» запой дома без врача может обернуться серьёзными осложнениями. Обращение к наркологу даёт пациенту:
Подробнее – вывод из запоя круглосуточно в санкт-петербурге
Алкогольный запой – это критическое состояние, возникающее при длительном злоупотреблении спиртными напитками, когда организм насыщается токсинами и его жизненно важные системы (сердечно-сосудистая, печёночная, нервная) начинают давать сбой. В такой ситуации необходимо незамедлительное вмешательство специалистов для предотвращения тяжелых осложнений и спасения жизни. Наркологическая клиника «Основа» в Новосибирске предоставляет экстренную помощь с помощью установки капельницы от запоя, позволяющей оперативно вывести токсины из организма, стабилизировать внутренние процессы и создать условия для последующего качественного восстановления.
Получить больше информации – https://kapelnica-ot-zapoya-novosibirsk8.ru/kapelnica-ot-zapoya-cena-v-novosibirske/
Наркологическая клиника “Путь к выздоровлению” — специализированное медицинское учреждение, предназначенное для оказания помощи лицам, страдающим от алкогольной и наркотической зависимости. Наша основная задача — предоставить эффективные методы лечения и поддержку, чтобы помочь пациентам преодолеть пагубное пристрастие и вернуть их к здоровой и полноценной жизни.
Углубиться в тему – https://нарко-фильтр.рф/vivod-iz-zapoya-anonimno-v-rostove-na-donu/
Мы верим, что каждый человек, столкнувшийся с проблемой зависимости, заслуживает шанса на новую жизнь. Наша миссия — предоставить необходимые инструменты и поддержку, чтобы помочь пациентам в их стремлении к здоровой и свободной от зависимостей жизни.
Детальнее – https://нарко-фильтр.рф/
Наркологическая клиника “Путь к выздоровлению” расположена по адресу: г. Ростов-на-Дону, ул. Петровская, д. 19. Клиника работает ежедневно с 8:00 до 20:00, без выходных. Наши специалисты готовы предоставить консультацию и ответить на все вопросы, связанные с лечением зависимостей. Мы гарантируем конфиденциальность и индивидуальный подход к каждому пациенту.
Разобраться лучше – https://нарко-фильтр.рф/
tiktok agency account for sale https://buy-tiktok-business-account.org
tiktok ads account buy https://buy-tiktok-ads.org
Мы верим, что каждый человек, столкнувшийся с проблемой зависимости, заслуживает шанса на новую жизнь. Наша миссия — предоставить необходимые инструменты и поддержку, чтобы помочь пациентам в их стремлении к здоровой и свободной от зависимостей жизни.
Подробнее тут – http://нарко-фильтр.рф/vivod-iz-zapoya-cena-v-rostove-na-donu/
Также мы учитываем потребности каждого пациента — по питанию, условиям проживания, графику процедур. Проживание возможно в стандартных и повышенных палатах, с возможностью индивидуального обслуживания.
Получить больше информации – круглосуточная наркологическая помощь в балашихе
Процесс лечения капельничным методом от запоя организован по четко структурированной схеме, позволяющей обеспечить оперативное и безопасное восстановление организма.
Подробнее – https://kapelnica-ot-zapoya-arkhangelsk0.ru/
Обращение к наркологу позволяет избежать типичных ошибок самолечения и достичь стабильного результата. Квалифицированное вмешательство:
Подробнее – https://narko-zakodirovan2.ru/vyvod-iz-zapoya-czena-novosibirsk/
Задача врачей — не просто облегчить симптомы, а купировать осложнения, стабилизировать жизненно важные функции, вернуть пациенту способность к дальнейшему лечению. Мы работаем быстро, анонимно и профессионально. Любой человек, оказавшийся в кризисе, может получить помощь в течение часа после обращения.
Углубиться в тему – снятие наркологической ломки на дому
Осложнения, к которым может привести отсутствие лечения:
Исследовать вопрос подробнее – снятие ломки на дому подольск
Лечение алкогольной зависимости на дому в Мурманске проходит по четко отлаженной схеме, которая включает несколько последовательных этапов. Каждый из них имеет решающее значение для безопасного и эффективного восстановления организма.
Изучить вопрос глубже – наркологический вывод из запоя в мурманске
Осложнения, к которым может привести отсутствие лечения:
Изучить вопрос глубже – snyatie lomki narkozavisimogo podol’sk
Ломка — это не временное недомогание. Это системное разрушение организма, связанное с тем, что он перестаёт получать наркотик, к которому уже привык. Нарушается обмен веществ, функции сердца, печени, почек, теряется контроль над эмоциями и болью. В состоянии абстиненции человек не может спать, есть, адекватно мыслить. Страдает и тело, и психика.
Получить больше информации – снятие наркологической ломки подольск
buy tiktok ads https://tiktok-ads-agency-account.org
Абстинентный синдром — одно из самых тяжёлых и опасных проявлений наркотической зависимости. Он развивается на фоне резкого отказа от приёма веществ и сопровождается сильнейшими нарушениями работы организма. Это состояние требует немедленного вмешательства. Самостоятельно справиться с ним невозможно — особенно если речь идёт о героине, метадоне, синтетических наркотиках или длительной зависимости. В клинике «НаркоПрофи» мы организовали систему снятия ломки в Подольске, работающую круглосуточно: как на дому, так и в условиях стационара.
Получить дополнительную информацию – snyatie lomki na domu podol’sk
Именно поэтому так важно не терять время. Чем раньше пациент получает помощь, тем выше шансы избежать необратимых последствий и вернуться к нормальной жизни.
Подробнее тут – https://snyatie-lomki-podolsk1.ru/snyatie-lomki-narkolog-v-podolske/
Врачебный состав клиники “Путь к выздоровлению” состоит из высококвалифицированных специалистов в области наркологии. Наши врачи-наркологи имеют обширный опыт работы с зависимыми пациентами и постоянно совершенствуют свои навыки.
Подробнее тут – https://нарко-фильтр.рф
Вывод из запоя может осуществляться в двух форматах — на дому и в стационаре. Выбор зависит от степени интоксикации, наличия осложнений и возможности обеспечить пациенту наблюдение в домашних условиях.
Ознакомиться с деталями – наркология вывод из запоя новосибирск
Процедура детоксикации может проводиться двумя способами: выездом врача на дом или госпитализацией. Окончательное решение принимает нарколог после оценки состояния пациента. На ранней стадии запоя достаточно домашней терапии, но при наличии рисков рекомендуется стационар.
Подробнее – наркологический вывод из запоя санкт-петербург
Миссия клиники “Маяк надежды” заключается в содействии восстановлению здоровья и социальной реинтеграции людей, столкнувшихся с проблемами зависимости. Мы стремимся к комплексному решению этой сложной задачи, учитывая физические, психологические и социальные аспекты зависимости. Наша задача — не только помочь пациентам избавиться от физической зависимости, но и обеспечить их психологическое восстановление и возвращение к нормальной жизни в обществе.
Исследовать вопрос подробнее – http://алко-лечение24.рф
Миссия клиники “Маяк надежды” заключается в содействии восстановлению здоровья и социальной реинтеграции людей, столкнувшихся с проблемами зависимости. Мы стремимся к комплексному решению этой сложной задачи, учитывая физические, психологические и социальные аспекты зависимости. Наша задача — не только помочь пациентам избавиться от физической зависимости, но и обеспечить их психологическое восстановление и возвращение к нормальной жизни в обществе.
Изучить вопрос глубже – http://алко-лечение24.рф/
Абстинентный синдром — одно из самых тяжёлых и опасных проявлений наркотической зависимости. Он развивается на фоне резкого отказа от приёма веществ и сопровождается сильнейшими нарушениями работы организма. Это состояние требует немедленного вмешательства. Самостоятельно справиться с ним невозможно — особенно если речь идёт о героине, метадоне, синтетических наркотиках или длительной зависимости. В клинике «НаркоПрофи» мы организовали систему снятия ломки в Подольске, работающую круглосуточно: как на дому, так и в условиях стационара.
Ознакомиться с деталями – снятие ломок на дому
Врачебный состав клиники “Маяк надежды” состоит из высококвалифицированных специалистов в области наркологии. Наши врачи-наркологи имеют обширный опыт работы с зависимыми пациентами и постоянно совершенствуют свои навыки.
Углубиться в тему – http://алко-лечение24.рф/
Именно поэтому так важно не терять время. Чем раньше пациент получает помощь, тем выше шансы избежать необратимых последствий и вернуться к нормальной жизни.
Разобраться лучше – http://snyatie-lomki-podolsk1.ru/snyatie-lomki-narkolog-v-podolske/
Метод капельничного лечения от запоя обладает рядом существенных преимуществ, благодаря которым пациенты получают качественную и оперативную помощь:
Выяснить больше – капельница от запоя анонимно архангельск
Также мы учитываем потребности каждого пациента — по питанию, условиям проживания, графику процедур. Проживание возможно в стандартных и повышенных палатах, с возможностью индивидуального обслуживания.
Ознакомиться с деталями – наркологическая помощь на дому балашиха
При тяжелой алкогольной интоксикации оперативное лечение становится жизненно необходимым для спасения здоровья. В Архангельске специалисты оказывают помощь на дому, используя метод капельничного лечения от запоя. Такой подход позволяет быстро вывести токсины, восстановить обмен веществ и стабилизировать работу внутренних органов, обеспечивая при этом высокий уровень конфиденциальности и комфорт в условиях привычного домашнего уюта.
Изучить вопрос глубже – вызвать капельницу от запоя архангельск
Задача врачей — не просто облегчить симптомы, а купировать осложнения, стабилизировать жизненно важные функции, вернуть пациенту способность к дальнейшему лечению. Мы работаем быстро, анонимно и профессионально. Любой человек, оказавшийся в кризисе, может получить помощь в течение часа после обращения.
Углубиться в тему – снятие наркотической ломки в подольске
Абстинентный синдром — одно из самых тяжёлых и опасных проявлений наркотической зависимости. Он развивается на фоне резкого отказа от приёма веществ и сопровождается сильнейшими нарушениями работы организма. Это состояние требует немедленного вмешательства. Самостоятельно справиться с ним невозможно — особенно если речь идёт о героине, метадоне, синтетических наркотиках или длительной зависимости. В клинике «НаркоПрофи» мы организовали систему снятия ломки в Подольске, работающую круглосуточно: как на дому, так и в условиях стационара.
Подробнее – https://snyatie-lomki-podolsk1.ru/snyatie-lomki-na-domu-v-podolske
В стационаре пациент получает круглосуточный контроль, расширенную диагностику и возможность подключения к аппаратуре мониторинга. Это особенно важно при тяжёлой интоксикации, нарушении сознания или судорожной активности.
Подробнее можно узнать тут – https://narko-zakodirovan.ru/vyvod-iz-zapoya-czena-spb/
Наркологическая клиника “Маяк надежды” расположена по адресу: г. Санкт-Петербург, ул. Колпинская, д. 27. Клиника работает ежедневно с 9:00 до 21:00, без выходных. Наши специалисты готовы предоставить консультацию и ответить на все вопросы, связанные с лечением зависимостей. Мы гарантируем конфиденциальность и индивидуальный подход к каждому пациенту.
Подробнее – http://алко-лечение24.рф/
Незамедлительно после вызова нарколог прибывает на дом для проведения первичного осмотра. Специалист измеряет жизненно важные показатели, такие как пульс, артериальное давление и температура, и собирает подробный анамнез. Это позволяет оценить степень интоксикации и оперативно разработать индивидуальный план лечения.
Исследовать вопрос подробнее – наркология вывод из запоя мурманск
Наши наркологи придерживаются принципов уважительного и внимательного отношения к пациентам, создавая атмосферу доверия. Они проводят детальное обследование, выявляют коренные причины зависимости и разрабатывают индивидуальные стратегии лечения. Профессионализм и компетентность врачей являются ключевыми факторами успешного восстановления пациентов.
Получить больше информации – http://
Абстинентный синдром — одно из самых тяжёлых и опасных проявлений наркотической зависимости. Он развивается на фоне резкого отказа от приёма веществ и сопровождается сильнейшими нарушениями работы организма. Это состояние требует немедленного вмешательства. Самостоятельно справиться с ним невозможно — особенно если речь идёт о героине, метадоне, синтетических наркотиках или длительной зависимости. В клинике «НаркоПрофи» мы организовали систему снятия ломки в Подольске, работающую круглосуточно: как на дому, так и в условиях стационара.
Углубиться в тему – снять ломку
Процесс лечения капельничным методом от запоя организован по четко структурированной схеме, позволяющей обеспечить оперативное и безопасное восстановление организма.
Изучить вопрос глубже – капельница от запоя цена архангельская область
Simply want to say your article is as amazing. The clarity in your post is just cool and i could assume you are an expert on this subject. Fine with your permission let me to grab your RSS feed to keep up to date with forthcoming post. Thanks a million and please continue the gratifying work.
На этом этапе специалист уточняет продолжительность запоя, тип употребляемого алкоголя и наличие сопутствующих заболеваний, что позволяет разработать персонализированный план терапии и оперативно выбрать методы детоксикации.
Изучить вопрос глубже – http://kapelnica-ot-zapoya-arkhangelsk0.ru/kapelnicza-ot-zapoya-klinika-arkhangelsk/
В стационаре пациент получает круглосуточный контроль, расширенную диагностику и возможность подключения к аппаратуре мониторинга. Это особенно важно при тяжёлой интоксикации, нарушении сознания или судорожной активности.
Подробнее – http://
Sweet blog! I found it while browsing on Yahoo News. Do you have any tips on how to get listed in Yahoo News? I’ve been trying for a while but I never seem to get there! Thank you
В этой публикации мы сосредоточимся на интересных аспектах одной из самых актуальных тем современности. Совмещая факты и мнения экспертов, мы создадим полное представление о предмете, которое будет полезно как новичкам, так и тем, кто глубоко изучает вопрос.
Узнать больше – https://obiady.3market.eu/wp/smakosfera/s7303041
В этой публикации мы сосредоточимся на интересных аспектах одной из самых актуальных тем современности. Совмещая факты и мнения экспертов, мы создадим полное представление о предмете, которое будет полезно как новичкам, так и тем, кто глубоко изучает вопрос.
Подробнее – https://star-education.net/tin-tuc-su-kien/loi-giai-chi-tiet-mon-hoa-chuyen-tuyen-sinh-10-ptnk-2020-2021
Эта информационная заметка предлагает лаконичное и четкое освещение актуальных вопросов. Здесь вы найдете ключевые факты и основную информацию по теме, которые помогут вам сформировать собственное мнение и повысить уровень осведомленности.
Получить дополнительные сведения – https://www.marcobertucci.com/regione-lazio-marco-bertucci-fdi-eletto-presidente-della-commissione-bilancio
Эта познавательная публикация погружает вас в море интересного контента, который быстро захватит ваше внимание. Мы рассмотрим важные аспекты темы и предоставим вам уникальныеInsights и полезные сведения для дальнейшего изучения.
Изучить вопрос глубже – https://marketingdetectives.info/revolutionize-your-business-with-our-cutting-edge
В этом интересном тексте собраны обширные сведения, которые помогут вам понять различные аспекты обсуждаемой темы. Мы разбираем детали и факты, делая акцент на важности каждого элемента. Не упустите возможность расширить свои знания и взглянуть на мир по-новому!
Разобраться лучше – https://ipkd.tabanankab.go.id/konsultasi-publik-ranwal-rkpd-sb-kabupaten-tabanan-2024
В этом информативном тексте представлены захватывающие события и факты, которые заставят вас задуматься. Мы обращаем внимание на важные моменты, которые часто остаются незамеченными, и предлагаем новые перспективы на привычные вещи. Подготовьтесь к тому, чтобы быть поглощенным увлекательными рассказами!
Исследовать вопрос подробнее – https://domains.tntcode.com/ip/81.90.182.215
I am not positive the place you’re getting your info, but good topic. I needs to spend a while learning more or understanding more. Thanks for excellent information I was searching for this info for my mission.
Эта статья сочетает познавательный и занимательный контент, что делает ее идеальной для любителей глубоких исследований. Мы рассмотрим увлекательные аспекты различных тем и предоставим вам новые знания, которые могут оказаться полезными в будущем.
Подробнее – https://www.grammeproducts.com/why-is-spearmint-oil-better-than-any-other-essential-oil-for-your-mental-health
Эта статья предлагает захватывающий и полезный контент, который привлечет внимание широкого круга читателей. Мы постараемся представить тебе идеи, которые вдохновят вас на изменения в жизни и предоставят практические решения для повседневных вопросов. Читайте и вдохновляйтесь!
Получить дополнительную информацию – https://www.badibangart.com/2023/06/09/diyongo
Эта статья для ознакомления предлагает читателям общее представление об актуальной теме. Мы стремимся представить ключевые факты и идеи, которые помогут читателям получить представление о предмете и решить, стоит ли углубляться в изучение.
Исследовать вопрос подробнее – http://www.blog.kedairohani.com/halkomentar-29-213.html
В этом интересном тексте собраны обширные сведения, которые помогут вам понять различные аспекты обсуждаемой темы. Мы разбираем детали и факты, делая акцент на важности каждого элемента. Не упустите возможность расширить свои знания и взглянуть на мир по-новому!
Получить больше информации – https://www.karooweavery.co.za/modern-shop-charity-event-2016
Этот информационный материал привлекает внимание множеством интересных деталей и необычных ракурсов. Мы предлагаем уникальные взгляды на привычные вещи и рассматриваем вопросы, которые волнуют общество. Будьте в курсе актуальных тем и расширяйте свои знания!
Получить дополнительную информацию – https://www.arhitectconstructii.ro/2012/04/pret-manopera-constructii-2012
В обзорной статье вы найдете собрание важных фактов и аналитики по самым разнообразным темам. Мы рассматриваем как современные исследования, так и исторические контексты, чтобы вы могли получить полное представление о предмете. Погрузитесь в мир знаний и сделайте шаг к пониманию!
Подробнее – https://www.returntolondontown.org/sponsors
Алкогольный запой требует не просто прекращения приёма спиртного, а комплексной медицинской помощи. В Санкт-Петербурге и Ленинградской области вывод из запоя осуществляется опытными наркологами с применением современных методик детоксикации. В зависимости от состояния пациента лечение может быть организовано как на дому, так и в стационарных условиях. Главная цель — безопасное очищение организма и возвращение к стабильному физическому и психоэмоциональному состоянию.
Подробнее тут – вывод из запоя на дому санкт-петербург.
Профессиональная помощь при запое необходима, если:
Получить дополнительные сведения – вывод из запоя в стационаре в санкт-петербурге
I relish, lead to I discovered just what I used to be having a look for. You have ended my four day long hunt! God Bless you man. Have a great day. Bye
Профессиональная помощь при запое необходима, если:
Детальнее – вывод из запоя клиника санкт-петербург
Самолечение или попытка «переждать» запой дома без врача может обернуться серьёзными осложнениями. Обращение к наркологу даёт пациенту:
Исследовать вопрос подробнее – вывод из запоя круглосуточно санкт-петербург
Со стороны же психики изменения в обоих произошли очень большие, как убедился бы всякий, кто мог бы подслушать разговор в подвальной квартире. И когда этот момент наступил, прокуратор выбросил вверх правую руку, и последний шум сдуло с толпы. «Оба-на! Влетел! Сдаться самому, что ли? Тогда простят ведь, – мелькнула истерическая мыслишка, но не справилась с упрямством Быстрова-младшего, угасла под напором другой.
Самолечение или попытка «переждать» запой дома без врача может обернуться серьёзными осложнениями. Обращение к наркологу даёт пациенту:
Детальнее – вывод из запоя цена санкт-петербург
Профессиональная помощь при запое необходима, если:
Детальнее – вывод из запоя недорого в санкт-петербурге
Профессиональная помощь при запое необходима, если:
Ознакомиться с деталями – http://narko-zakodirovan.ru
Состояние пациента стабилизируется за счёт коррекции давления, нормализации пульса, снятия тремора и тревожности. Для защиты печени применяются гепатопротекторы, а для восстановления функций мозга — препараты нейрометаболического действия. При необходимости назначаются витамины группы B, седативные средства, препараты для восстановления сна.
Получить дополнительные сведения – вывод из запоя круглосуточно
Мы верим, что каждый человек, столкнувшийся с проблемой зависимости, заслуживает шанса на новую жизнь. Наша миссия — предоставить необходимые инструменты и поддержку, чтобы помочь пациентам в их стремлении к здоровой и свободной от зависимостей жизни.
Исследовать вопрос подробнее – http://нарко-фильтр.рф/vivod-iz-zapoya-v-stacionare-v-rostove-na-donu/https://нарко-фильтр.рф
В столичном регионе доступны два основных формата лечения: выезд специалиста на дом и госпитализация в специализированный центр. Каждый вариант имеет свои особенности и показания, которые врач анализирует при первичном осмотре.
Подробнее можно узнать тут – http://алко-избавление.рф/vyvod-iz-zapoya-na-domu-msk/https://алко-избавление.рф
В стационаре пациент получает круглосуточный контроль, расширенную диагностику и возможность подключения к аппаратуре мониторинга. Это особенно важно при тяжёлой интоксикации, нарушении сознания или судорожной активности.
Углубиться в тему – вывод из запоя в стационаре
Когда зависимость захватывает жизнь, она разрушает не только организм, но и личность, отношения с близкими, карьерные планы и самоощущение. Алкоголь, наркотики и психотропные препараты постепенно подрывают работу внутренних органов, нарушают баланс нейромедиаторов в мозге и приводят к серьёзным психическим и физическим осложнениям. Попытки справиться с этим самостоятельно редко бывают успешными: необходим системный, профессиональный подход. В наркологической клинике «Доктор Здоровье» в Мытищах вы найдёте надёжную опору на всех этапах выздоровления — от экстренной детоксикации до длительной реабилитации.
Изучить вопрос глубже – частная наркологическая клиника мытищи
Запой — это не просто продолжительное пьянство, а острое состояние, требующее срочной медицинской помощи. Без профессионального вмешательства организм человека стремительно разрушается, возрастает риск инфаркта, инсульта, алкогольного психоза и летального исхода. Именно поэтому вывод из запоя должен проходить под контролем нарколога, с использованием проверенных медикаментов и поэтапной схемы стабилизации. В наркологической клинике «ВитаМед Плюс» организована круглосуточная помощь в Химках, включая выезд врача на дом и приём в стационаре.
Детальнее – срочный вывод из запоя химки
Самолечение или попытка «переждать» запой дома без врача может обернуться серьёзными осложнениями. Обращение к наркологу даёт пациенту:
Ознакомиться с деталями – https://narko-zakodirovan.ru/vyvod-iz-zapoya-czena-spb
Каждый день запоя увеличивает риск для жизни. Не рискуйте — специалисты «Трезвого шага» в Воронеже приедут на дом и окажут экстренную помощь. Без боли, стресса и ожидания.
Выяснить больше – вывод из запоя
Алкогольный запой требует не просто прекращения приёма спиртного, а комплексной медицинской помощи. В Санкт-Петербурге и Ленинградской области вывод из запоя осуществляется опытными наркологами с применением современных методик детоксикации. В зависимости от состояния пациента лечение может быть организовано как на дому, так и в стационарных условиях. Главная цель — безопасное очищение организма и возвращение к стабильному физическому и психоэмоциональному состоянию.
Подробнее тут – http://narko-zakodirovan.ru/vyvod-iz-zapoya-czena-spb/
Профессиональная помощь при запое необходима, если:
Подробнее – http://narko-zakodirovan.ru/vyvod-iz-zapoya-kapelnicza-spb/
При ухудшении состояния, вызванном длительным употреблением алкоголя, оперативное вмешательство может спасти жизнь. В Калининграде, Калининградская область, опытные наркологи выезжают на дом, чтобы оказать профессиональную помощь при алкогольной интоксикации. Такой формат лечения позволяет получить качественную помощь в комфортной и привычной обстановке, сохраняя полную конфиденциальность и минимизируя стресс, связанный с госпитализацией.
Узнать больше – вызов врача нарколога на дом калининград
Профессиональная помощь при запое необходима, если:
Подробнее тут – наркологический вывод из запоя
Обращение за помощью нарколога на дому в Улан-Удэ имеет ряд неоспоримых преимуществ, обеспечивающих эффективное лечение:
Подробнее можно узнать тут – вывод из запоя недорого улан-удэ
Алкогольный запой требует не просто прекращения приёма спиртного, а комплексной медицинской помощи. В Санкт-Петербурге и Ленинградской области вывод из запоя осуществляется опытными наркологами с применением современных методик детоксикации. В зависимости от состояния пациента лечение может быть организовано как на дому, так и в стационарных условиях. Главная цель — безопасное очищение организма и возвращение к стабильному физическому и психоэмоциональному состоянию.
Подробнее – вывод из запоя цена санкт-петербург
В стационаре пациент получает круглосуточный контроль, расширенную диагностику и возможность подключения к аппаратуре мониторинга. Это особенно важно при тяжёлой интоксикации, нарушении сознания или судорожной активности.
Изучить вопрос глубже – вывод из запоя круглосуточно санкт-петербург
Алкогольный запой требует не просто прекращения приёма спиртного, а комплексной медицинской помощи. В Санкт-Петербурге и Ленинградской области вывод из запоя осуществляется опытными наркологами с применением современных методик детоксикации. В зависимости от состояния пациента лечение может быть организовано как на дому, так и в стационарных условиях. Главная цель — безопасное очищение организма и возвращение к стабильному физическому и психоэмоциональному состоянию.
Углубиться в тему – vyvod-iz-zapoya sankt-peterburg
Близкий человек в запое? Не ждите ухудшения. Обратитесь в клинику «Трезвый шаг» (Воронеж) — здесь проведут профессиональный вывод из запоя с последующим восстановлением организма.
Детальнее – нарколог вывод из запоя
При сравнительно лёгкой или среднетяжёлой степени интоксикации нарколог приезжает на дом, где в знакомой обстановке проводит детоксикацию. Врач измеряет параметры жизнедеятельности — пульс, давление, насыщение кислородом — и подбирает оптимальный состав препаратов для инфузий. Такой метод подходит тем, кто испытывает стресс при мысли о стационаре и нуждается в анонимности лечения.
Исследовать вопрос подробнее – https://алко-избавление.рф/vyvod-iz-zapoya-czena-msk/
Профессиональная помощь при запое необходима, если:
Углубиться в тему – нарколог вывод из запоя санкт-петербург
Запой — это состояние, при котором человек на протяжении нескольких дней или недель регулярно употребляет алкоголь, теряя контроль над собой. При этом организм накапливает этанол и его токсичные метаболиты, печень и сердце работают на износ, нарушается сон, развивается психоэмоциональная нестабильность. Главный риск — абстинентный синдром, который может проявляться тремором, судорогами, повышением давления, паникой и даже галлюцинациями.
Детальнее – вывод из запоя в стационаре в химках
Процедура детоксикации может проводиться двумя способами: выездом врача на дом или госпитализацией. Окончательное решение принимает нарколог после оценки состояния пациента. На ранней стадии запоя достаточно домашней терапии, но при наличии рисков рекомендуется стационар.
Получить больше информации – вывод из запоя в санкт-петербурге
Запой — это не просто продолжительное пьянство, а острое состояние, требующее срочной медицинской помощи. Без профессионального вмешательства организм человека стремительно разрушается, возрастает риск инфаркта, инсульта, алкогольного психоза и летального исхода. Именно поэтому вывод из запоя должен проходить под контролем нарколога, с использованием проверенных медикаментов и поэтапной схемы стабилизации. В наркологической клинике «ВитаМед Плюс» организована круглосуточная помощь в Химках, включая выезд врача на дом и приём в стационаре.
Подробнее можно узнать тут – vyvod-iz-zapoya-czena himki
Когда зависимость захватывает жизнь, она разрушает не только организм, но и личность, отношения с близкими, карьерные планы и самоощущение. Алкоголь, наркотики и психотропные препараты постепенно подрывают работу внутренних органов, нарушают баланс нейромедиаторов в мозге и приводят к серьёзным психическим и физическим осложнениям. Попытки справиться с этим самостоятельно редко бывают успешными: необходим системный, профессиональный подход. В наркологической клинике «Доктор Здоровье» в Мытищах вы найдёте надёжную опору на всех этапах выздоровления — от экстренной детоксикации до длительной реабилитации.
Получить дополнительную информацию – наркологическая клиника нарколог
Запой — это состояние, при котором человек на протяжении нескольких дней или недель регулярно употребляет алкоголь, теряя контроль над собой. При этом организм накапливает этанол и его токсичные метаболиты, печень и сердце работают на износ, нарушается сон, развивается психоэмоциональная нестабильность. Главный риск — абстинентный синдром, который может проявляться тремором, судорогами, повышением давления, паникой и даже галлюцинациями.
Получить дополнительные сведения – вывод из запоя московская область
Миссия клиники “Путь к выздоровлению” заключается в содействии восстановлению здоровья и социальной реинтеграции людей, столкнувшихся с проблемами зависимости. Мы стремимся к комплексному решению этой сложной задачи, учитывая физические, психологические и социальные аспекты зависимости. Наша цель — не только помочь пациентам избавиться от физической зависимости, но и обеспечить их психологическое восстановление и возвращение к нормальной жизни в обществе.
Подробнее можно узнать тут – https://нарко-фильтр.рф/vivod-iz-zapoya-anonimno-v-rostove-na-donu
Запой — это состояние, при котором человек на протяжении нескольких дней или недель регулярно употребляет алкоголь, теряя контроль над собой. При этом организм накапливает этанол и его токсичные метаболиты, печень и сердце работают на износ, нарушается сон, развивается психоэмоциональная нестабильность. Главный риск — абстинентный синдром, который может проявляться тремором, судорогами, повышением давления, паникой и даже галлюцинациями.
Узнать больше – вывод из запоя капельница
На данном этапе врач уточняет, как долго продолжается запой, какой тип алкоголя употребляется и имеются ли сопутствующие заболевания. Тщательный анализ этих данных помогает разработать индивидуальный план терапии, направленный на эффективное снижение токсической нагрузки.
Ознакомиться с деталями – нарколог на дом анонимно калининград
Домашнее лечение позволяет снизить психологическое напряжение, поскольку пациент остаётся в привычной обстановке — рядом с близкими и без очередей. Экономия времени достигается за счёт оперативного выезда специалиста без необходимости госпитализации, а затраты на вызов часто оказываются ниже, чем в стационаре. При грамотном подборе медикаментов и круглосуточном контроле со стороны врача риск осложнений сводится к минимуму.
Изучить вопрос глубже – https://алко-избавление.рф/vyvod-iz-zapoya-na-domu-msk/
Профессиональная помощь при запое необходима, если:
Получить дополнительные сведения – вывод из запоя клиника санкт-петербург
В стационаре пациент получает круглосуточный контроль, расширенную диагностику и возможность подключения к аппаратуре мониторинга. Это особенно важно при тяжёлой интоксикации, нарушении сознания или судорожной активности.
Получить дополнительную информацию – vyvod-iz-zapoya-czena sankt-peterburg
Запой — это не просто продолжительное пьянство, а острое состояние, требующее срочной медицинской помощи. Без профессионального вмешательства организм человека стремительно разрушается, возрастает риск инфаркта, инсульта, алкогольного психоза и летального исхода. Именно поэтому вывод из запоя должен проходить под контролем нарколога, с использованием проверенных медикаментов и поэтапной схемы стабилизации. В наркологической клинике «ВитаМед Плюс» организована круглосуточная помощь в Химках, включая выезд врача на дом и приём в стационаре.
Получить дополнительные сведения – вывод из запоя на дому в химках
Когда алкогольный запой начинает угрожать здоровью, оперативное лечение становится жизненно необходимым. В Улан-Удэ, Республика Бурятия, высококвалифицированные наркологи оказывают помощь на дому, обеспечивая детоксикацию организма, восстановление нормальных обменных процессов и стабилизацию работы внутренних органов. Такой метод позволяет пациенту получить индивидуализированное лечение в условиях привычного домашнего уюта, что значительно снижает стресс и гарантирует полную конфиденциальность.
Ознакомиться с деталями – вывод из запоя на дому цена в улан-удэ
При сравнительно лёгкой или среднетяжёлой степени интоксикации нарколог приезжает на дом, где в знакомой обстановке проводит детоксикацию. Врач измеряет параметры жизнедеятельности — пульс, давление, насыщение кислородом — и подбирает оптимальный состав препаратов для инфузий. Такой метод подходит тем, кто испытывает стресс при мысли о стационаре и нуждается в анонимности лечения.
Углубиться в тему – https://алко-избавление.рф/vyvod-iz-zapoya-czena-msk
Применение автоматизированных систем дозирования гарантирует точное введение медикаментов, что минимизирует риск передозировки и побочных эффектов. Постоянный мониторинг жизненно важных показателей даёт врачу возможность оперативно корректировать терапевтическую схему, обеспечивая максимальную безопасность процедуры.
Изучить вопрос глубже – вывод из запоя донецкая область
Каждый день запоя увеличивает риск для жизни. Не рискуйте — специалисты «Трезвого шага» в Воронеже приедут на дом и окажут экстренную помощь. Без боли, стресса и ожидания.
Исследовать вопрос подробнее – вывод из запоя на дому
– Судорожный синдром, дыхательная недостаточность – Острые панические атаки и психозы – Инфаркт, инсульт, аритмия – Дегидратация и почечная недостаточность – Суицидальные мысли, агрессия, саморазрушение
Ознакомиться с деталями – снятие наркологической ломки
Самолечение или попытка «переждать» запой дома без врача может обернуться серьёзными осложнениями. Обращение к наркологу даёт пациенту:
Подробнее можно узнать тут – вывод из запоя анонимно в санкт-петербурге
Затяжной запой опасен для жизни. Врачи наркологической клиники «Трезвый шаг» в Воронеже проводят срочный вывод из запоя — на дому или в стационаре. Анонимно, безопасно, круглосуточно.
Ознакомиться с деталями – вывод из запоя на дому круглосуточно
В основе нашей методики — комплексный подход, сочетающий медицинскую точку зрения и психологические технологии. Мы не ограничиваемся снятием абстиненции: задача клиники — помочь пациенту обрести новую мотивацию, развить навыки противостояния стрессам и возобновить социальную активность. Работа строится на трёх ключевых принципах:
Выяснить больше – https://narkologicheskaya-klinika-mytishchi1.ru/
В стационаре пациент получает круглосуточный контроль, расширенную диагностику и возможность подключения к аппаратуре мониторинга. Это особенно важно при тяжёлой интоксикации, нарушении сознания или судорожной активности.
Получить дополнительные сведения – вывод из запоя в стационаре в санкт-петербурге
На данном этапе врач уточняет, как долго продолжается запой, какой тип алкоголя употребляется и имеются ли сопутствующие заболевания. Тщательный анализ этих данных помогает разработать индивидуальный план терапии, направленный на эффективное снижение токсической нагрузки.
Получить больше информации – https://narcolog-na-dom-kaliningrad00.ru/
Профессиональная помощь при запое необходима, если:
Подробнее тут – вывод из запоя на дому цена в санкт-петербурге
В столичном регионе доступны два основных формата лечения: выезд специалиста на дом и госпитализация в специализированный центр. Каждый вариант имеет свои особенности и показания, которые врач анализирует при первичном осмотре.
Разобраться лучше – https://алко-избавление.рф/vyvod-iz-zapoya-na-domu-msk
Затяжной запой опасен для жизни. Врачи наркологической клиники «Трезвый шаг» в Воронеже проводят срочный вывод из запоя — на дому или в стационаре. Анонимно, безопасно, круглосуточно.
Выяснить больше – нарколог вывод из запоя
Клиника оснащена всем необходимым для качественной диагностики и лечения: собственная лаборатория проводит расширенные анализы крови и мочи, биохимические панели проверяют функцию печени и почек, а специальная аппаратура (ЭКГ, пульсоксиметр, автоматические тонометры) позволяет вести непрерывный мониторинг состояния пациентов. Инфузионная терапия осуществляется на базе очищенных растворов с точно рассчитанной дозой, а компьютерные психотесты помогают выявить уровень тревоги, депрессии и когнитивных нарушений, чтобы скорректировать терапевтическую программу.
Узнать больше – narkologicheskaya-klinika-mytishchi1.ru/
Когда организм на пределе, важна срочная помощь. «Трезвый шаг» в Воронеже — это команда опытных наркологов, которые помогут быстро и мягко выйти из запоя без вреда для здоровья.
Подробнее – вывод из запоя цена
В стационаре пациент получает круглосуточный контроль, расширенную диагностику и возможность подключения к аппаратуре мониторинга. Это особенно важно при тяжёлой интоксикации, нарушении сознания или судорожной активности.
Подробнее можно узнать тут – http://narko-zakodirovan.ru
Наркологическая клиника “Путь к выздоровлению” — специализированное медицинское учреждение, предназначенное для оказания помощи лицам, страдающим от алкогольной и наркотической зависимости. Наша основная задача — предоставить эффективные методы лечения и поддержку, чтобы помочь пациентам преодолеть пагубное пристрастие и вернуть их к здоровой и полноценной жизни.
Выяснить больше – http://нарко-фильтр.рф/vivod-iz-zapoya-v-kruglosutochno-v-rostove-na-donu/
Самолечение или попытка «переждать» запой дома без врача может обернуться серьёзными осложнениями. Обращение к наркологу даёт пациенту:
Получить больше информации – вывод из запоя
Услуга вывода из запоя на дому в Улан-Удэ включает комплекс мероприятий, направленных на оперативное снижение токсической нагрузки и возвращение организма в нормальное состояние. Сразу после получения вызова специалист проводит тщательный осмотр, измеряет жизненно важные показатели и собирает подробный анамнез, что позволяет точно определить степень алкогольной интоксикации. На основе этих данных разрабатывается персональный план терапии, который может включать инфузионное введение медикаментов, коррекцию обмена веществ и оказание психологической поддержки.
Ознакомиться с деталями – https://vyvod-iz-zapoya-ulan-ude00.ru/
Задача врачей — не просто облегчить симптомы, а купировать осложнения, стабилизировать жизненно важные функции, вернуть пациенту способность к дальнейшему лечению. Мы работаем быстро, анонимно и профессионально. Любой человек, оказавшийся в кризисе, может получить помощь в течение часа после обращения.
Подробнее – снятие ломки наркозависимого в подольске
Сразу после поступления вызова специалист приезжает на дом для проведения тщательного первичного осмотра. Измеряются такие жизненно важные показатели, как пульс, артериальное давление и температура, а также проводится сбор анамнеза, что позволяет оценить степень алкогольной интоксикации.
Выяснить больше – https://narcolog-na-dom-kaliningrad00.ru/narkolog-na-dom-kruglosutochno-kaliningrad
Вывод из запоя обязателен, если:
Узнать больше – наркологический вывод из запоя в химках
Осложнения, к которым может привести отсутствие лечения:
Подробнее можно узнать тут – снятие наркотической ломки в подольске
– Судорожный синдром, дыхательная недостаточность – Острые панические атаки и психозы – Инфаркт, инсульт, аритмия – Дегидратация и почечная недостаточность – Суицидальные мысли, агрессия, саморазрушение
Выяснить больше – снятие ломок на дому в подольске
Когда организм на пределе, важна срочная помощь. «Трезвый шаг» в Воронеже — это команда опытных наркологов, которые помогут быстро и мягко выйти из запоя без вреда для здоровья.
Подробнее можно узнать тут – вывод из запоя цена
Профессиональная помощь при запое необходима, если:
Получить больше информации – вывод из запоя цена санкт-петербург
Именно поэтому так важно не терять время. Чем раньше пациент получает помощь, тем выше шансы избежать необратимых последствий и вернуться к нормальной жизни.
Изучить вопрос глубже – http://www.domen.ru
Ломка — это не временное недомогание. Это системное разрушение организма, связанное с тем, что он перестаёт получать наркотик, к которому уже привык. Нарушается обмен веществ, функции сердца, печени, почек, теряется контроль над эмоциями и болью. В состоянии абстиненции человек не может спать, есть, адекватно мыслить. Страдает и тело, и психика.
Исследовать вопрос подробнее – snyat lomku podol’sk
Миссия клиники “Путь к выздоровлению” заключается в содействии восстановлению здоровья и социальной реинтеграции людей, столкнувшихся с проблемами зависимости. Мы стремимся к комплексному решению этой сложной задачи, учитывая физические, психологические и социальные аспекты зависимости. Наша цель — не только помочь пациентам избавиться от физической зависимости, но и обеспечить их психологическое восстановление и возвращение к нормальной жизни в обществе.
Детальнее – http://нарко-фильтр.рф
После диагностики начинается активная фаза медикаментозного вмешательства. Препараты вводятся инфузионным методом, что позволяет оперативно снизить уровень токсинов в крови, восстановить обмен веществ и нормализовать работу внутренних органов, таких как печень, почки и сердце.
Углубиться в тему – вывод из запоя недорого
При сравнительно лёгкой или среднетяжёлой степени интоксикации нарколог приезжает на дом, где в знакомой обстановке проводит детоксикацию. Врач измеряет параметры жизнедеятельности — пульс, давление, насыщение кислородом — и подбирает оптимальный состав препаратов для инфузий. Такой метод подходит тем, кто испытывает стресс при мысли о стационаре и нуждается в анонимности лечения.
Выяснить больше – http://алко-избавление.рф
Запой — это не просто продолжительное пьянство, а острое состояние, требующее срочной медицинской помощи. Без профессионального вмешательства организм человека стремительно разрушается, возрастает риск инфаркта, инсульта, алкогольного психоза и летального исхода. Именно поэтому вывод из запоя должен проходить под контролем нарколога, с использованием проверенных медикаментов и поэтапной схемы стабилизации. В наркологической клинике «ВитаМед Плюс» организована круглосуточная помощь в Химках, включая выезд врача на дом и приём в стационаре.
Узнать больше – вывод из запоя химки.
Во всех этих случаях промедление может стоить слишком дорого. Наркологическая помощь должна быть оказана немедленно — либо на дому, либо в условиях клиники.
Получить дополнительную информацию – вывод из запоя в стационаре в химках
Профессиональная помощь при запое необходима, если:
Углубиться в тему – нарколог вывод из запоя
Самолечение или попытка «переждать» запой дома без врача может обернуться серьёзными осложнениями. Обращение к наркологу даёт пациенту:
Ознакомиться с деталями – http://narko-zakodirovan.ru
Запой — это длительное бесконтрольное употребление алкоголя, приводящее к серьёзным нарушениям обмена веществ, дезориентации и риску острого алкогольного психоза. В Москве и области помощь при выводе из запоя востребована как в домашних условиях, так и в стационаре. Вне зависимости от выбора методики главная цель — быстрое и безопасное восстановление здоровья, чтобы человек мог начать новую, полноценную жизнь без зависимости.
Подробнее тут – https://алко-избавление.рф/narkolog-vyvod-iz-zapoya-msk
Когда зависимость захватывает жизнь, она разрушает не только организм, но и личность, отношения с близкими, карьерные планы и самоощущение. Алкоголь, наркотики и психотропные препараты постепенно подрывают работу внутренних органов, нарушают баланс нейромедиаторов в мозге и приводят к серьёзным психическим и физическим осложнениям. Попытки справиться с этим самостоятельно редко бывают успешными: необходим системный, профессиональный подход. В наркологической клинике «Доктор Здоровье» в Мытищах вы найдёте надёжную опору на всех этапах выздоровления — от экстренной детоксикации до длительной реабилитации.
Получить дополнительную информацию – narkologicheskaya klinika mytischi
В клинике «ВитаМед Плюс» применяются проверенные методики и препараты, которые позволяют безопасно вывести пациента из запоя. Процедура начинается с внутривенного введения очищающих растворов, которые помогают ускорить выведение этанола и токсинов. Одновременно восстанавливается водно-солевой баланс, что особенно важно при обезвоживании после длительного употребления алкоголя.
Углубиться в тему – vyvod-iz-zapoya-v-himki1.ru/
Задача врачей — не просто облегчить симптомы, а купировать осложнения, стабилизировать жизненно важные функции, вернуть пациенту способность к дальнейшему лечению. Мы работаем быстро, анонимно и профессионально. Любой человек, оказавшийся в кризисе, может получить помощь в течение часа после обращения.
Узнать больше – снятие наркологической ломки в подольске
Профессиональная помощь при запое необходима, если:
Подробнее можно узнать тут – https://narko-zakodirovan.ru/vyvod-iz-zapoya-kapelnicza-spb
В клинике «ВитаМед Плюс» применяются проверенные методики и препараты, которые позволяют безопасно вывести пациента из запоя. Процедура начинается с внутривенного введения очищающих растворов, которые помогают ускорить выведение этанола и токсинов. Одновременно восстанавливается водно-солевой баланс, что особенно важно при обезвоживании после длительного употребления алкоголя.
Узнать больше – vyvod-iz-zapoya-v-himki1.ru/
В клинике «ВитаМед Плюс» применяются проверенные методики и препараты, которые позволяют безопасно вывести пациента из запоя. Процедура начинается с внутривенного введения очищающих растворов, которые помогают ускорить выведение этанола и токсинов. Одновременно восстанавливается водно-солевой баланс, что особенно важно при обезвоживании после длительного употребления алкоголя.
Исследовать вопрос подробнее – срочный вывод из запоя химки
Лечение нарколога на дому в Калининграде организовано по четко отлаженной схеме, позволяющей максимально оперативно стабилизировать состояние пациента и начать процесс детоксикации.
Подробнее можно узнать тут – https://narcolog-na-dom-kaliningrad00.ru/
Задача врачей — не просто облегчить симптомы, а купировать осложнения, стабилизировать жизненно важные функции, вернуть пациенту способность к дальнейшему лечению. Мы работаем быстро, анонимно и профессионально. Любой человек, оказавшийся в кризисе, может получить помощь в течение часа после обращения.
Выяснить больше – snyatie-lomki-podolsk1.ru/
Ломка — это не временное недомогание. Это системное разрушение организма, связанное с тем, что он перестаёт получать наркотик, к которому уже привык. Нарушается обмен веществ, функции сердца, печени, почек, теряется контроль над эмоциями и болью. В состоянии абстиненции человек не может спать, есть, адекватно мыслить. Страдает и тело, и психика.
Узнать больше – снятие ломки московская область
Во всех этих случаях промедление может стоить слишком дорого. Наркологическая помощь должна быть оказана немедленно — либо на дому, либо в условиях клиники.
Детальнее – вывод из запоя на дому цена в химках
Алкогольный запой требует не просто прекращения приёма спиртного, а комплексной медицинской помощи. В Санкт-Петербурге и Ленинградской области вывод из запоя осуществляется опытными наркологами с применением современных методик детоксикации. В зависимости от состояния пациента лечение может быть организовано как на дому, так и в стационарных условиях. Главная цель — безопасное очищение организма и возвращение к стабильному физическому и психоэмоциональному состоянию.
Получить больше информации – https://narko-zakodirovan.ru/vyvod-iz-zapoya-kapelnicza-spb
В условиях клиники пациент находится под наблюдением медицинской сестры и врача 24/7, что особенно важно при тяжёлой интоксикации и риске острых осложнений. Быстрый доступ к расширенной диагностике — ЭКГ, УЗИ, анализы крови — обеспечивает точную корректировку терапии. Стационар подходит тем, у кого есть серьёзные сопутствующие заболевания или высокий риск алкогольных психозов.
Углубиться в тему – https://алко-избавление.рф/vyvod-iz-zapoya-czena-msk/
Когда алкогольный запой начинает угрожать здоровью, оперативное лечение становится жизненно необходимым. В Улан-Удэ, Республика Бурятия, высококвалифицированные наркологи оказывают помощь на дому, обеспечивая детоксикацию организма, восстановление нормальных обменных процессов и стабилизацию работы внутренних органов. Такой метод позволяет пациенту получить индивидуализированное лечение в условиях привычного домашнего уюта, что значительно снижает стресс и гарантирует полную конфиденциальность.
Подробнее – нарколог вывод из запоя в улан-удэ
Близкий человек в запое? Не ждите ухудшения. Обратитесь в клинику «Трезвый шаг» (Воронеж) — здесь проведут профессиональный вывод из запоя с последующим восстановлением организма.
Выяснить больше – наркологический вывод из запоя
В нашей практике сочетаются несколько видов вмешательства: медико-биологическое, психологическое и социальное. Сначала проводится полная диагностика, включая лабораторные анализы и оценку работы сердца, печени, почек, а также психодиагностические тесты. После этого начинается этап детоксикации с внутривенными капельницами, которые выводят токсины, нормализуют водно-солевой баланс и восстанавливают основные функции организма. Далее мы применяем медикаментозную поддержку для стабилизации артериального давления, купирования тревожных симптомов, нормализации сна и уменьшения болевого синдрома.
Получить больше информации – наркологические клиники алкоголизм мытищи
При сравнительно лёгкой или среднетяжёлой степени интоксикации нарколог приезжает на дом, где в знакомой обстановке проводит детоксикацию. Врач измеряет параметры жизнедеятельности — пульс, давление, насыщение кислородом — и подбирает оптимальный состав препаратов для инфузий. Такой метод подходит тем, кто испытывает стресс при мысли о стационаре и нуждается в анонимности лечения.
Получить дополнительные сведения – https://алко-избавление.рф/
Абстинентный синдром — одно из самых тяжёлых и опасных проявлений наркотической зависимости. Он развивается на фоне резкого отказа от приёма веществ и сопровождается сильнейшими нарушениями работы организма. Это состояние требует немедленного вмешательства. Самостоятельно справиться с ним невозможно — особенно если речь идёт о героине, метадоне, синтетических наркотиках или длительной зависимости. В клинике «НаркоПрофи» мы организовали систему снятия ломки в Подольске, работающую круглосуточно: как на дому, так и в условиях стационара.
Изучить вопрос глубже – снятие ломки в стационаре в подольске
Процесс начинается с вызова врача или доставки пациента в клинику. После прибытия специалист проводит первичную диагностику: измерение давления, температуры, пульса, уровня кислорода в крови, визуальная оценка степени возбуждения или угнетения сознания. Собирается краткий анамнез: какой наркотик принимался, как долго, были ли сопутствующие заболевания.
Подробнее – снятие ломок подольск
В клинике «ВитаМед Плюс» применяются проверенные методики и препараты, которые позволяют безопасно вывести пациента из запоя. Процедура начинается с внутривенного введения очищающих растворов, которые помогают ускорить выведение этанола и токсинов. Одновременно восстанавливается водно-солевой баланс, что особенно важно при обезвоживании после длительного употребления алкоголя.
Подробнее можно узнать тут – вывод из запоя на дому в химках
При ухудшении состояния, вызванном длительным употреблением алкоголя, оперативное вмешательство может спасти жизнь. В Калининграде, Калининградская область, опытные наркологи выезжают на дом, чтобы оказать профессиональную помощь при алкогольной интоксикации. Такой формат лечения позволяет получить качественную помощь в комфортной и привычной обстановке, сохраняя полную конфиденциальность и минимизируя стресс, связанный с госпитализацией.
Изучить вопрос глубже – запой нарколог на дом калининград
Когда зависимость захватывает жизнь, она разрушает не только организм, но и личность, отношения с близкими, карьерные планы и самоощущение. Алкоголь, наркотики и психотропные препараты постепенно подрывают работу внутренних органов, нарушают баланс нейромедиаторов в мозге и приводят к серьёзным психическим и физическим осложнениям. Попытки справиться с этим самостоятельно редко бывают успешными: необходим системный, профессиональный подход. В наркологической клинике «Доктор Здоровье» в Мытищах вы найдёте надёжную опору на всех этапах выздоровления — от экстренной детоксикации до длительной реабилитации.
Исследовать вопрос подробнее – платная наркологическая клиника
Когда организм на пределе, важна срочная помощь. «Трезвый шаг» в Воронеже — это команда опытных наркологов, которые помогут быстро и мягко выйти из запоя без вреда для здоровья.
Разобраться лучше – narkolog-vyvod-iz-zapoya
Врач может приехать в течение 1–2 часов после обращения. В стационар возможна экстренная госпитализация в тот же день.
Подробнее можно узнать тут – https://narko-zakodirovan2.ru/vyvod-iz-zapoya-czena-novosibirsk
Вывод из запоя может осуществляться в двух форматах — на дому и в стационаре. Выбор зависит от степени интоксикации, наличия осложнений и возможности обеспечить пациенту наблюдение в домашних условиях.
Выяснить больше – вывод из запоя недорого новосибирск
Близкий человек в запое? Не ждите ухудшения. Обратитесь в клинику «Трезвый шаг» (Воронеж) — здесь проведут профессиональный вывод из запоя с последующим восстановлением организма.
Получить больше информации – вывод из запоя цена
Услуга вывода из запоя на дому в Улан-Удэ включает комплекс мероприятий, направленных на оперативное снижение токсической нагрузки и возвращение организма в нормальное состояние. Сразу после получения вызова специалист проводит тщательный осмотр, измеряет жизненно важные показатели и собирает подробный анамнез, что позволяет точно определить степень алкогольной интоксикации. На основе этих данных разрабатывается персональный план терапии, который может включать инфузионное введение медикаментов, коррекцию обмена веществ и оказание психологической поддержки.
Подробнее можно узнать тут – наркология вывод из запоя
Затяжной запой — это состояние, при котором человек в течение нескольких дней не может прекратить употребление алкоголя без медицинской помощи. Такое состояние чревато тяжёлыми нарушениями в работе внутренних органов и психики. В Новосибирске и Новосибирской области доступен профессиональный вывод из запоя как на дому, так и в условиях стационара. Подход к лечению индивидуален, и основная цель — безопасно и эффективно устранить последствия интоксикации и предотвратить рецидив.
Подробнее можно узнать тут – vyvod-iz-zapoya-na-domu novosibirsk
Лечение нарколога на дому в Калининграде организовано по четко отлаженной схеме, позволяющей максимально оперативно стабилизировать состояние пациента и начать процесс детоксикации.
Ознакомиться с деталями – http://narcolog-na-dom-kaliningrad00.ru
В клинике «ВитаМед Плюс» применяются проверенные методики и препараты, которые позволяют безопасно вывести пациента из запоя. Процедура начинается с внутривенного введения очищающих растворов, которые помогают ускорить выведение этанола и токсинов. Одновременно восстанавливается водно-солевой баланс, что особенно важно при обезвоживании после длительного употребления алкоголя.
Подробнее – вывод из запоя
Запой — это длительное бесконтрольное употребление алкоголя, приводящее к серьёзным нарушениям обмена веществ, дезориентации и риску острого алкогольного психоза. В Москве и области помощь при выводе из запоя востребована как в домашних условиях, так и в стационаре. Вне зависимости от выбора методики главная цель — быстрое и безопасное восстановление здоровья, чтобы человек мог начать новую, полноценную жизнь без зависимости.
Исследовать вопрос подробнее – https://алко-избавление.рф/vyvod-iz-zapoya-na-domu-msk
Вывод из запоя может осуществляться в двух форматах — на дому и в стационаре. Выбор зависит от степени интоксикации, наличия осложнений и возможности обеспечить пациенту наблюдение в домашних условиях.
Получить больше информации – вывод из запоя анонимно
Решение обратиться к врачу должно быть принято, если:
Подробнее можно узнать тут – https://narko-zakodirovan2.ru/vyvod-iz-zapoya-kruglosutochno-novosibirsk
Наши наркологи придерживаются принципов уважительного и внимательного отношения к пациентам, создавая атмосферу доверия. Они проводят детальное обследование, выявляют коренные причины зависимости и разрабатывают индивидуальные стратегии лечения. Профессионализм и компетентность врачей являются ключевыми факторами успешного восстановления пациентов.
Изучить вопрос глубже – http://нарко-фильтр.рф/vivod-iz-zapoya-v-kruglosutochno-v-rostove-na-donu/
Тимур замахнулся, целясь в толстое дерево, но друг перехватил руку: – Ты что? Оно живое, ему больно. Однако удачи не было. Рядом с Боруном возникли Сокол и Грум.
Вывод из запоя может осуществляться в двух форматах — на дому и в стационаре. Выбор зависит от степени интоксикации, наличия осложнений и возможности обеспечить пациенту наблюдение в домашних условиях.
Ознакомиться с деталями – http://narko-zakodirovan2.ru
Недостаточно снять физическую зависимость — важно помочь человеку вернуться в сообщество. В «Доктор Здоровье» разработана система сопровождения, включающая мотивационные беседы, групповые занятия и социальную реабилитацию. Психотерапевты владеют методами когнитивно-поведенческой терапии и мотивационного интервью, консультанты помогают восстановить профессиональные навыки и адаптироваться к повседневной жизни, а встречи в группе взаимопомощи и психодраматические сессии способствуют укреплению чувства поддержки и навыков эффективного общения. Для родственников доступны семейные консультации, на которых объясняют природу зависимости и обучают стратегиям поддержки без критики и давления.
Получить дополнительные сведения – narkologicheskie kliniki alkogolizm mytischi
Когда алкогольный запой начинает угрожать здоровью, оперативное лечение становится жизненно необходимым. В Улан-Удэ, Республика Бурятия, высококвалифицированные наркологи оказывают помощь на дому, обеспечивая детоксикацию организма, восстановление нормальных обменных процессов и стабилизацию работы внутренних органов. Такой метод позволяет пациенту получить индивидуализированное лечение в условиях привычного домашнего уюта, что значительно снижает стресс и гарантирует полную конфиденциальность.
Углубиться в тему – http://www.domen.ru
Каждый день запоя увеличивает риск для жизни. Не рискуйте — специалисты «Трезвого шага» в Воронеже приедут на дом и окажут экстренную помощь. Без боли, стресса и ожидания.
Выяснить больше – наркология вывод из запоя
Обращение к наркологу позволяет избежать типичных ошибок самолечения и достичь стабильного результата. Квалифицированное вмешательство:
Разобраться лучше – вывод из запоя клиника в новосибирске
Без толку, конечно. – Погоди про дым. А Маргарита в это время уже поднималась стремительно вверх по лестнице, повторяя в каком-то упоении: — Латунский — восемьдесят четыре! Латунский — восемьдесят четыре… Вот налево — 82, направо — 83, еще выше, налево — 84.
Близкий человек в запое? Не ждите ухудшения. Обратитесь в клинику «Трезвый шаг» (Воронеж) — здесь проведут профессиональный вывод из запоя с последующим восстановлением организма.
Подробнее можно узнать тут – vyvod-iz-zapoya-czena
Врачебный состав клиники “Путь к выздоровлению” состоит из высококвалифицированных специалистов в области наркологии. Наши врачи-наркологи имеют обширный опыт работы с зависимыми пациентами и постоянно совершенствуют свои навыки.
Ознакомиться с деталями – https://нарко-фильтр.рф/vivod-iz-zapoya-v-stacionare-v-rostove-na-donu
Я нашел у него! Наставник покачал головой: – Опять оговор. Думал он долго и наконец сказал: — Сдаюсь. Он прошел в дом по какому-то делу к моему застройщику, потом сошел в садик и как-то очень быстро свел со мной знакомство.
Затяжной запой опасен для жизни. Врачи наркологической клиники «Трезвый шаг» в Воронеже проводят срочный вывод из запоя — на дому или в стационаре. Анонимно, безопасно, круглосуточно.
Ознакомиться с деталями – вывод из запоя на дому цена
Затяжной запой — это состояние, при котором человек в течение нескольких дней не может прекратить употребление алкоголя без медицинской помощи. Такое состояние чревато тяжёлыми нарушениями в работе внутренних органов и психики. В Новосибирске и Новосибирской области доступен профессиональный вывод из запоя как на дому, так и в условиях стационара. Подход к лечению индивидуален, и основная цель — безопасно и эффективно устранить последствия интоксикации и предотвратить рецидив.
Подробнее – http://narko-zakodirovan2.ru/vyvod-iz-zapoya-czena-novosibirsk/
WONDERFUL Post.thanks for share..extra wait .. ?
В нашей практике сочетаются несколько видов вмешательства: медико-биологическое, психологическое и социальное. Сначала проводится полная диагностика, включая лабораторные анализы и оценку работы сердца, печени, почек, а также психодиагностические тесты. После этого начинается этап детоксикации с внутривенными капельницами, которые выводят токсины, нормализуют водно-солевой баланс и восстанавливают основные функции организма. Далее мы применяем медикаментозную поддержку для стабилизации артериального давления, купирования тревожных симптомов, нормализации сна и уменьшения болевого синдрома.
Углубиться в тему – наркологические клиники алкоголизм
Обращение за помощью нарколога на дому в Калининграде имеет ряд значимых преимуществ:
Получить дополнительные сведения – нарколог на дом калининградская область
Great site. A lot of useful info here. I?m sending it to some friends ans also sharing in delicious. And certainly, thanks for your sweat!
В столичном регионе доступны два основных формата лечения: выезд специалиста на дом и госпитализация в специализированный центр. Каждый вариант имеет свои особенности и показания, которые врач анализирует при первичном осмотре.
Выяснить больше – https://алко-избавление.рф/
При сравнительно лёгкой или среднетяжёлой степени интоксикации нарколог приезжает на дом, где в знакомой обстановке проводит детоксикацию. Врач измеряет параметры жизнедеятельности — пульс, давление, насыщение кислородом — и подбирает оптимальный состав препаратов для инфузий. Такой метод подходит тем, кто испытывает стресс при мысли о стационаре и нуждается в анонимности лечения.
Изучить вопрос глубже – http://
кайт школа египет
Запой — это длительное бесконтрольное употребление алкоголя, приводящее к серьёзным нарушениям обмена веществ, дезориентации и риску острого алкогольного психоза. В Москве и области помощь при выводе из запоя востребована как в домашних условиях, так и в стационаре. Вне зависимости от выбора методики главная цель — быстрое и безопасное восстановление здоровья, чтобы человек мог начать новую, полноценную жизнь без зависимости.
Углубиться в тему – http://
Удивительно, но одна лоза тотчас нашлась. Имейте в виду, что на это существует седьмое доказательство, и уж самое надежное! И вам оно сейчас будет предъявлено. — Думайте что хотите, но мне будет скучно, когда вы уедете.
Врач может приехать в течение 1–2 часов после обращения. В стационар возможна экстренная госпитализация в тот же день.
Подробнее можно узнать тут – наркологический вывод из запоя новосибирск
В условиях клиники пациент находится под наблюдением медицинской сестры и врача 24/7, что особенно важно при тяжёлой интоксикации и риске острых осложнений. Быстрый доступ к расширенной диагностике — ЭКГ, УЗИ, анализы крови — обеспечивает точную корректировку терапии. Стационар подходит тем, у кого есть серьёзные сопутствующие заболевания или высокий риск алкогольных психозов.
Изучить вопрос глубже – http://алко-избавление.рф
Запой — это состояние, при котором человек на протяжении нескольких дней или недель регулярно употребляет алкоголь, теряя контроль над собой. При этом организм накапливает этанол и его токсичные метаболиты, печень и сердце работают на износ, нарушается сон, развивается психоэмоциональная нестабильность. Главный риск — абстинентный синдром, который может проявляться тремором, судорогами, повышением давления, паникой и даже галлюцинациями.
Подробнее можно узнать тут – вывод из запоя на дому в химках
Услуга вывода из запоя на дому в Улан-Удэ включает комплекс мероприятий, направленных на оперативное снижение токсической нагрузки и возвращение организма в нормальное состояние. Сразу после получения вызова специалист проводит тщательный осмотр, измеряет жизненно важные показатели и собирает подробный анамнез, что позволяет точно определить степень алкогольной интоксикации. На основе этих данных разрабатывается персональный план терапии, который может включать инфузионное введение медикаментов, коррекцию обмена веществ и оказание психологической поддержки.
Узнать больше – вывод из запоя на дому республика бурятия
Сразу после поступления вызова специалист приезжает на дом для проведения тщательного первичного осмотра. Измеряются такие жизненно важные показатели, как пульс, артериальное давление и температура, а также проводится сбор анамнеза, что позволяет оценить степень алкогольной интоксикации.
Углубиться в тему – http://narcolog-na-dom-kaliningrad00.ru/narkolog-na-dom-kruglosutochno-kaliningrad/
Запой — это длительное бесконтрольное употребление алкоголя, приводящее к серьёзным нарушениям обмена веществ, дезориентации и риску острого алкогольного психоза. В Москве и области помощь при выводе из запоя востребована как в домашних условиях, так и в стационаре. Вне зависимости от выбора методики главная цель — быстрое и безопасное восстановление здоровья, чтобы человек мог начать новую, полноценную жизнь без зависимости.
Изучить вопрос глубже – https://алко-избавление.рф/
Пусть не любимые записи, но лучше, чем ничего. Арина Власьевна не замечала Аркадия, не потчевала его; подперши кулачком свое круглое лицо, которому одутловатые, вишневого цвета губки и родинки на щеках и над бровями придавали выражение очень добродушное, она не сводила глаз с сына и все вздыхала; ей смертельно хотелось узнать, на сколько времени он приехал, но спросить его она боялась. Славка не помнил, когда они расцепили руки, но то, что она провалилась первой – несомненно! Почему же он падает впереди? Додумать не удалось.
В условиях клиники пациент находится под наблюдением медицинской сестры и врача 24/7, что особенно важно при тяжёлой интоксикации и риске острых осложнений. Быстрый доступ к расширенной диагностике — ЭКГ, УЗИ, анализы крови — обеспечивает точную корректировку терапии. Стационар подходит тем, у кого есть серьёзные сопутствующие заболевания или высокий риск алкогольных психозов.
Разобраться лучше – https://алко-избавление.рф/narkolog-vyvod-iz-zapoya-msk
В условиях клиники пациент находится под наблюдением медицинской сестры и врача 24/7, что особенно важно при тяжёлой интоксикации и риске острых осложнений. Быстрый доступ к расширенной диагностике — ЭКГ, УЗИ, анализы крови — обеспечивает точную корректировку терапии. Стационар подходит тем, у кого есть серьёзные сопутствующие заболевания или высокий риск алкогольных психозов.
Получить дополнительные сведения – https://алко-избавление.рф/
Затяжной запой — это состояние, при котором человек в течение нескольких дней не может прекратить употребление алкоголя без медицинской помощи. Такое состояние чревато тяжёлыми нарушениями в работе внутренних органов и психики. В Новосибирске и Новосибирской области доступен профессиональный вывод из запоя как на дому, так и в условиях стационара. Подход к лечению индивидуален, и основная цель — безопасно и эффективно устранить последствия интоксикации и предотвратить рецидив.
Получить дополнительные сведения – вывод из запоя цена в новосибирске
Обращение к наркологу позволяет избежать типичных ошибок самолечения и достичь стабильного результата. Квалифицированное вмешательство:
Выяснить больше – срочный вывод из запоя новосибирск
Мне хочется тебе это сказать, чтобы ты знал, что крови еще будет. Один раз Наташа стала расспрашивать про его сына. Наконец вошла Танюша и доложила, что обед готов.
Наркологическая клиника “Путь к выздоровлению” расположена по адресу: г. Ростов-на-Дону, ул. Петровская, д. 19. Клиника работает ежедневно с 8:00 до 20:00, без выходных. Наши специалисты готовы предоставить консультацию и ответить на все вопросы, связанные с лечением зависимостей. Мы гарантируем конфиденциальность и индивидуальный подход к каждому пациенту.
Выяснить больше – https://нарко-фильтр.рф/vivod-iz-zapoya-anonimno-v-rostove-na-donu/
Врач может приехать в течение 1–2 часов после обращения. В стационар возможна экстренная госпитализация в тот же день.
Подробнее – https://narko-zakodirovan2.ru/vyvod-iz-zapoya-na-domu-novosibirsk/
Когда алкогольный запой начинает угрожать здоровью, оперативное лечение становится жизненно необходимым. В Улан-Удэ, Республика Бурятия, высококвалифицированные наркологи оказывают помощь на дому, обеспечивая детоксикацию организма, восстановление нормальных обменных процессов и стабилизацию работы внутренних органов. Такой метод позволяет пациенту получить индивидуализированное лечение в условиях привычного домашнего уюта, что значительно снижает стресс и гарантирует полную конфиденциальность.
Исследовать вопрос подробнее – https://vyvod-iz-zapoya-ulan-ude00.ru/vyvod-iz-zapoya-kapelnicza-ulan-ude
Затяжной запой — это состояние, при котором человек в течение нескольких дней не может прекратить употребление алкоголя без медицинской помощи. Такое состояние чревато тяжёлыми нарушениями в работе внутренних органов и психики. В Новосибирске и Новосибирской области доступен профессиональный вывод из запоя как на дому, так и в условиях стационара. Подход к лечению индивидуален, и основная цель — безопасно и эффективно устранить последствия интоксикации и предотвратить рецидив.
Ознакомиться с деталями – наркологический вывод из запоя
Через неделю будет заседание… Супруга побежала в переднюю, а Никанор Иванович разливательной ложкой поволок из огнедышащего озера — ее, кость, треснувшую вдоль. Всё объясню. Поспешно распустив хвостики, принялась расчесывать волосы массажной щеткой.
Каждый день запоя увеличивает риск для жизни. Не рискуйте — специалисты «Трезвого шага» в Воронеже приедут на дом и окажут экстренную помощь. Без боли, стресса и ожидания.
Детальнее – вывод из запоя на дому
Когда зависимость захватывает жизнь, она разрушает не только организм, но и личность, отношения с близкими, карьерные планы и самоощущение. Алкоголь, наркотики и психотропные препараты постепенно подрывают работу внутренних органов, нарушают баланс нейромедиаторов в мозге и приводят к серьёзным психическим и физическим осложнениям. Попытки справиться с этим самостоятельно редко бывают успешными: необходим системный, профессиональный подход. В наркологической клинике «Доктор Здоровье» в Мытищах вы найдёте надёжную опору на всех этапах выздоровления — от экстренной детоксикации до длительной реабилитации.
Детальнее – narkologicheskaya-klinika-mytishchi1.ru/
Скрутила в тройную спираль. Коса ее развилась и темной змеей упала к ней на плечо. Усердие в молитве скажется, и к сезону ты сможешь заняться посевом… – Благодарю тебя, о маханта! Благодарю, – посетительница попыталась снова упасть на колени перед невысокой седой старушкой.
Этот информационный материал привлекает внимание множеством интересных деталей и необычных ракурсов. Мы предлагаем уникальные взгляды на привычные вещи и рассматриваем вопросы, которые волнуют общество. Будьте в курсе актуальных тем и расширяйте свои знания!
Разобраться лучше – https://geneticsmr.com/2024/03/11/relationship-of-the-accessory-regulator-gene-agr-with-multi-resistance-in-staphylococcus-aureus-strains-isolated-from-hospitals-and-dental-offices
Эта познавательная публикация погружает вас в море интересного контента, который быстро захватит ваше внимание. Мы рассмотрим важные аспекты темы и предоставим вам уникальныеInsights и полезные сведения для дальнейшего изучения.
Получить дополнительные сведения – https://anambd.com/faq-items/do-you-have-oeko-tex-standard-certificate
Эта статья предлагает уникальную подборку занимательных фактов и необычных историй, которые вы, возможно, не знали. Мы постараемся вдохновить ваше воображение и разнообразить ваш кругозор, погружая вас в мир, полный интересных открытий. Читайте и открывайте для себя новое!
Исследовать вопрос подробнее – http://fgsstore.us/product/chuckit-ultra-ball-dog-toy
Эта статья предлагает уникальную подборку занимательных фактов и необычных историй, которые вы, возможно, не знали. Мы постараемся вдохновить ваше воображение и разнообразить ваш кругозор, погружая вас в мир, полный интересных открытий. Читайте и открывайте для себя новое!
Узнать больше – http://korenagakazuo.com/2015/01/10/%E6%AC%B2%E6%9C%9B%E3%81%8C%E6%B8%9B%E8%A1%B0%E3%81%97%E3%81%A6%E3%81%84%E3%81%8F%E6%99%82%E4%BB%A3%E3%80%81%E4%B8%BB%E4%BD%93%E7%9A%84%E8%87%AA%E5%BE%8B%E3%82%92%E4%BF%83%E3%81%9B
— Ванна, сто семнадцатую отдельную и пост к нему, — распорядился врач, надевая очки. Ну, коли уж сошлись, делать нечего, – он сделал отстраняющее движение ладонью. Срочно! Глава 21 Что вылечит Русану? Доложив Соколу, куда отлучается, Славка бросился в школу.
Этот обзорный материал предоставляет информационно насыщенные данные, касающиеся актуальных тем. Мы стремимся сделать информацию доступной и структурированной, чтобы читатели могли легко ориентироваться в наших выводах. Познайте новое с нашим обзором!
Подробнее тут – http://www.gabyramireztv.com/status-post
В этой информационной статье вы найдете интересное содержание, которое поможет вам расширить свои знания. Мы предлагаем увлекательный подход и уникальные взгляды на обсуждаемые темы, побуждая пользователей к активному мышлению и критическому анализу!
Углубиться в тему – https://mathgiri.com/%E0%A4%AD%E0%A4%BE%E0%A4%B0%E0%A4%A4%E0%A5%80%E0%A4%AF-%E0%A4%85%E0%A4%B0%E0%A5%8D%E0%A4%A5%E0%A4%B5%E0%A5%8D%E0%A4%AF%E0%A4%B5%E0%A4%B8%E0%A5%8D%E0%A4%A5%E0%A4%BE-%E0%A4%85%E0%A4%AC-3-75-trillion
В этой статье представлен занимательный и актуальный контент, который заставит вас задуматься. Мы обсуждаем насущные вопросы и проблемы, а также освещаем истории, которые вдохновляют на действия и изменения. Узнайте, что стоит за событиями нашего времени!
Получить больше информации – https://outletcomvc.com/ola-mundo
В этом обзорном материале представлены увлекательные детали, которые находят отражение в различных аспектах жизни. Мы исследуем непонятные и интересные моменты, позволяя читателю увидеть картину целиком. Погрузитесь в мир знаний и удивительных открытий!
Разобраться лучше – https://fruitthemes.com/demo/advent-wordpress-theme/liber-dolorum/blog-1_6
Лечение алкогольной зависимости на дому в Мурманске проходит по четко отлаженной схеме, которая включает несколько последовательных этапов. Каждый из них имеет решающее значение для безопасного и эффективного восстановления организма.
Разобраться лучше – http://vyvod-iz-zapoya-murmansk0.ru/vyvod-iz-zapoya-na-domu-murmansk//
Запой — это не просто продолжительное пьянство, а острое состояние, требующее срочной медицинской помощи. Без профессионального вмешательства организм человека стремительно разрушается, возрастает риск инфаркта, инсульта, алкогольного психоза и летального исхода. Именно поэтому вывод из запоя должен проходить под контролем нарколога, с использованием проверенных медикаментов и поэтапной схемы стабилизации. В наркологической клинике «ВитаМед Плюс» организована круглосуточная помощь в Химках, включая выезд врача на дом и приём в стационаре.
Углубиться в тему – наркология вывод из запоя
Клиника «Возрождение» гарантирует:
Подробнее тут – http://narkologicheskaya-klinika-ufa9.ru
Каждому пациенту назначается персональный план терапии, составленный на основе результатов медицинского и психологического обследования. Мы не используем шаблонные схемы — только индивидуальный подход, адаптированный к возрасту, опыту зависимости, состоянию здоровья и личной мотивации.
Подробнее можно узнать тут – chastnaya narkologicheskaya klinika volgograd
Во всех этих случаях промедление может стоить слишком дорого. Наркологическая помощь должна быть оказана немедленно — либо на дому, либо в условиях клиники.
Углубиться в тему – http://vyvod-iz-zapoya-v-himki1.ru
Параллельно с медицинской терапией начинается работа психотерапевта. В индивидуальных и семейных сессиях пациенты учатся распознавать механизмы зависимости, вырабатывать новые стратегии поведения и справляться со стрессовыми ситуациями без употребления. Последний этап — реабилитация и ресоциализация — включает трудотерапию, арт- и групповую терапию, помощь в восстановлении профессиональных навыков и возвращении к социально-активной жизни.
Подробнее можно узнать тут – частная наркологическая клиника
На данном этапе врач уточняет, сколько времени продолжается запой, какой тип алкоголя употребляется и имеются ли сопутствующие заболевания. Тщательный анализ этих данных позволяет подобрать оптимальные методы детоксикации и снизить риск осложнений.
Исследовать вопрос подробнее – вызов врача нарколога на дом
Возможность получить помощь в любой час снижает риск осложнений и ускоряет стабилизацию состояния. Среди главных преимуществ:
Получить больше информации – https://narkologicheskaya-pomoshh-ufa9.ru/narkologicheskaya-pomoshh-na-domu-ufa/
Для безопасного и эффективного лечения дома необходимо:
Подробнее – срочная наркологическая помощь
Наш стационар оснащён всем необходимым для безопасного и комфортного лечения. Здесь вы получите круглосуточный мониторинг, современное оборудование и услуги психологов, социальных педагогов и физиотерапевтов.
Подробнее – наркологическая клиника уфа
Услуга вывода из запоя на дому в Мурманске предполагает комплексное лечение алкогольной интоксикации, направленное на оперативное снижение уровня токсинов в организме. Сразу после поступления вызова специалист проводит детальный осмотр, собирает анамнез и определяет степень интоксикации. На основании собранной информации разрабатывается индивидуальный план терапии, который может включать капельничное введение медикаментов, контроль жизненно важных показателей и психологическую поддержку. Такой комплекс мер позволяет стабилизировать состояние пациента и начать процесс выздоровления без необходимости посещения стационара.
Углубиться в тему – https://vyvod-iz-zapoya-murmansk0.ru/vyvod-iz-zapoya-kruglosutochno-murmansk
Запой — это не просто продолжительное пьянство, а острое состояние, требующее срочной медицинской помощи. Без профессионального вмешательства организм человека стремительно разрушается, возрастает риск инфаркта, инсульта, алкогольного психоза и летального исхода. Именно поэтому вывод из запоя должен проходить под контролем нарколога, с использованием проверенных медикаментов и поэтапной схемы стабилизации. В наркологической клинике «ВитаМед Плюс» организована круглосуточная помощь в Химках, включая выезд врача на дом и приём в стационаре.
Подробнее тут – нарколог вывод из запоя
Вывод из запоя обязателен, если:
Углубиться в тему – вывод из запоя недорого
Помощь нарколога на дому в Мурманске обладает рядом неоспоримых преимуществ, которые делают данный метод лечения особенно актуальным:
Ознакомиться с деталями – вывод из запоя мурманская область
Когда запой становится угрозой для жизни и здоровья, своевременная помощь профессионала может стать решающим фактором для скорейшего восстановления. В Мурманске, где суровые климатические условия добавляют стресса и осложнений, квалифицированные наркологи оказывают помощь на дому, обеспечивая оперативную детоксикацию и индивидуальную терапию в привычной обстановке. Такой подход позволяет пациентам избежать лишних перемещений и получить поддержку в комфортной атмосфере.
Получить дополнительную информацию – вывод из запоя в стационаре мурманск
Если вы видите, что близкий не может выйти из запоя самостоятельно, или если после нескольких дней употребления появились тревожные симптомы — не ждите. Помощь нужна уже сейчас.
Выяснить больше – вывод из запоя анонимно химки
В нашей практике сочетаются несколько видов вмешательства: медико-биологическое, психологическое и социальное. Сначала проводится полная диагностика, включая лабораторные анализы и оценку работы сердца, печени, почек, а также психодиагностические тесты. После этого начинается этап детоксикации с внутривенными капельницами, которые выводят токсины, нормализуют водно-солевой баланс и восстанавливают основные функции организма. Далее мы применяем медикаментозную поддержку для стабилизации артериального давления, купирования тревожных симптомов, нормализации сна и уменьшения болевого синдрома.
Детальнее – наркологическая клиника мытищи.
Вывод из запоя обязателен, если:
Подробнее – наркология вывод из запоя химки
Незамедлительно после вызова нарколог прибывает на дом для проведения первичного осмотра. Специалист измеряет жизненно важные показатели, такие как пульс, артериальное давление и температура, и собирает подробный анамнез. Это позволяет оценить степень интоксикации и оперативно разработать индивидуальный план лечения.
Изучить вопрос глубже – вывод из запоя цена
Обращение за помощью к наркологу на дому имеет ряд преимуществ, особенно в экстренных ситуациях:
Детальнее – запой нарколог на дом
Незамедлительно после вызова нарколог прибывает на дом для проведения первичного осмотра. Специалист измеряет жизненно важные показатели, такие как пульс, артериальное давление и температура, и собирает подробный анамнез. Это позволяет оценить степень интоксикации и оперативно разработать индивидуальный план лечения.
Разобраться лучше – http://vyvod-iz-zapoya-murmansk0.ru
Запой — это не просто продолжительное пьянство, а острое состояние, требующее срочной медицинской помощи. Без профессионального вмешательства организм человека стремительно разрушается, возрастает риск инфаркта, инсульта, алкогольного психоза и летального исхода. Именно поэтому вывод из запоя должен проходить под контролем нарколога, с использованием проверенных медикаментов и поэтапной схемы стабилизации. В наркологической клинике «ВитаМед Плюс» организована круглосуточная помощь в Химках, включая выезд врача на дом и приём в стационаре.
Выяснить больше – срочный вывод из запоя
Для комплексного восстановления мы предлагаем ряд вспомогательных процедур, которые улучшают самочувствие и ускоряют реабилитацию.
Изучить вопрос глубже – наркологическая клиника республика башкортостан
Клиника «Возрождение» гарантирует:
Изучить вопрос глубже – http://narkologicheskaya-klinika-ufa9.ru/
кайт сафари
Эта статья полна интересного контента, который побудит вас исследовать новые горизонты. Мы собрали полезные факты и удивительные истории, которые обогащают ваше понимание темы. Читайте, погружайтесь в детали и наслаждайтесь процессом изучения!
Ознакомиться с деталями – https://www.karooweavery.co.za/modern-shop-charity-event-2016
В этой статье-обзоре мы соберем актуальную информацию и интересные факты, которые освещают важные темы. Читатели смогут ознакомиться с различными мнениями и подходами, что позволит им расширить кругозор и глубже понять обсуждаемые вопросы.
Подробнее можно узнать тут – http://blessedandgrumpy.com/index.php/2023/11/12/rules/comments
Этот обзорный материал предоставляет информационно насыщенные данные, касающиеся актуальных тем. Мы стремимся сделать информацию доступной и структурированной, чтобы читатели могли легко ориентироваться в наших выводах. Познайте новое с нашим обзором!
Получить дополнительную информацию – https://cuckoo-beauty.de/created-lights-whose-days
В этой статье вы найдете познавательную и занимательную информацию, которая поможет вам лучше понять мир вокруг. Мы собрали интересные данные, которые вдохновляют на размышления и побуждают к действиям. Открывайте новую информацию и получайте удовольствие от чтения!
Ознакомиться с деталями – http://keyopsfoundation.org/icon15
В этой публикации мы сосредоточимся на интересных аспектах одной из самых актуальных тем современности. Совмещая факты и мнения экспертов, мы создадим полное представление о предмете, которое будет полезно как новичкам, так и тем, кто глубоко изучает вопрос.
Получить дополнительную информацию – https://tregh.com/index.php/2016/09/10/interiorismo-experimental
Эта статья сочетает познавательный и занимательный контент, что делает ее идеальной для любителей глубоких исследований. Мы рассмотрим увлекательные аспекты различных тем и предоставим вам новые знания, которые могут оказаться полезными в будущем.
Получить больше информации – https://shearenvyvt.com/cultural-dynamics-and-conjugal-romance-high-quality-in-mexican-origin-homes-pmc
В обзорной статье вы найдете собрание важных фактов и аналитики по самым разнообразным темам. Мы рассматриваем как современные исследования, так и исторические контексты, чтобы вы могли получить полное представление о предмете. Погрузитесь в мир знаний и сделайте шаг к пониманию!
Получить дополнительные сведения – https://tabeyou.org/products/other/yybbs/yybbs.cgi?pg=7000
Зависимость — это хроническое заболевание, которое разрушает не только физическое, но и психическое здоровье человека. Она подчиняет волю, искажает восприятие, разрушает семьи и судьбы. Алкоголизм, наркомания, игровая зависимость — лишь разные проявления одной проблемы, требующей профессионального и комплексного подхода.
Изучить вопрос глубже – vyvod-iz-zapoya-klinika ufa
Вывод из запоя обязателен, если:
Подробнее – вывод из запоя круглосуточно в химках
«Рентвил» предлагает аренду автомобилей в Краснодаре без залога и ограничений по пробегу по Краснодарскому краю и Адыгее. Требуется стаж от 3 лет и возраст от 23 лет. Оформление за 5 минут онлайн: нужны только фото паспорта и прав. Подача авто на жд вокзал и аэропорт Краснодар Мин-воды Сочи . Компания работает 10 лет , автомобили проходят своевременное ТО. Доступны детские кресла. Бронируйте через сайт Краснодар аренда автомобиля
http://pravo-med.ru/articles/18547/
температура воды в хургаде в феврале
Незамедлительно после вызова нарколог приезжает на дом для проведения первичного осмотра. Врач измеряет жизненно важные показатели, такие как пульс, артериальное давление и температура, и собирает краткий анамнез для оценки степени алкогольной интоксикации. Этот этап является фундаментом для составления персонализированного плана лечения.
Получить дополнительные сведения – вывод из запоя клиника донецк
Запой — это не просто продолжительное пьянство, а острое состояние, требующее срочной медицинской помощи. Без профессионального вмешательства организм человека стремительно разрушается, возрастает риск инфаркта, инсульта, алкогольного психоза и летального исхода. Именно поэтому вывод из запоя должен проходить под контролем нарколога, с использованием проверенных медикаментов и поэтапной схемы стабилизации. В наркологической клинике «ВитаМед Плюс» организована круглосуточная помощь в Химках, включая выезд врача на дом и приём в стационаре.
Узнать больше – вывод из запоя в стационаре химки
Наш стационар оснащён всем необходимым для безопасного и комфортного лечения. Здесь вы получите круглосуточный мониторинг, современное оборудование и услуги психологов, социальных педагогов и физиотерапевтов.
Узнать больше – наркологические клиники алкоголизм
Преимущества вывода из запоя от опытных специалистов в условиях Донецка ДНР многочисленны. Такой формат лечения позволяет:
Разобраться лучше – вывод из запоя круглосуточно
Лечение алкоголизма в Воронеже — помощь на всех стадиях зависимости особенно важно на этапе, когда у человека ещё сохраняется мотивация к изменениям. Но даже при тяжёлых формах зависимости шанс на выздоровление сохраняется — при условии комплексного подхода.
Узнать больше – лечение алкоголизма воронеж.
Запой — это не просто продолжительное пьянство, а острое состояние, требующее срочной медицинской помощи. Без профессионального вмешательства организм человека стремительно разрушается, возрастает риск инфаркта, инсульта, алкогольного психоза и летального исхода. Именно поэтому вывод из запоя должен проходить под контролем нарколога, с использованием проверенных медикаментов и поэтапной схемы стабилизации. В наркологической клинике «ВитаМед Плюс» организована круглосуточная помощь в Химках, включая выезд врача на дом и приём в стационаре.
Детальнее – нарколог вывод из запоя в химках
Процесс лечения капельничным методом от запоя организован по четко структурированной схеме, позволяющей обеспечить оперативное и безопасное восстановление организма.
Выяснить больше – https://kapelnica-ot-zapoya-arkhangelsk0.ru/kapelnicza-ot-zapoya-klinika-arkhangelsk/
Мы не делаем «массовых решений»: каждый пациент для нас — уникальная история, и мы строим терапию, исходя из его состояния, целей и личных возможностей. Наша задача — не просто временно облегчить симптомы, а дать человеку реальные инструменты для жизни без зависимости.
Углубиться в тему – http://
Возможность получить помощь в любой час снижает риск осложнений и ускоряет стабилизацию состояния. Среди главных преимуществ:
Подробнее можно узнать тут – skoraya narkologicheskaya pomoshch ufa
https://oboronspecsplav.ru/
букет цветов с доставкой доставка цветов на дом
Мы используем новейшие образцы медицинской техники, что повышает безопасность процедур и скорость детоксикации.
Исследовать вопрос подробнее – платная наркологическая помощь в уфе
Мы понимаем, насколько важна приватность для пациентов и их близких. В «Возрождение» все обращения регистрируются по номеру договора, без упоминания личных данных в государственных базах. Даже близкие могут не знать точного диагноза, если пациент пожелает сохранить это в тайне.
Узнать больше – http://narkologicheskaya-klinika-ufa9.ru
доставка цветов на дом спб купить цветы в спб дешево
Запой — это состояние, при котором человек на протяжении нескольких дней или недель регулярно употребляет алкоголь, теряя контроль над собой. При этом организм накапливает этанол и его токсичные метаболиты, печень и сердце работают на износ, нарушается сон, развивается психоэмоциональная нестабильность. Главный риск — абстинентный синдром, который может проявляться тремором, судорогами, повышением давления, паникой и даже галлюцинациями.
Исследовать вопрос подробнее – наркологический вывод из запоя
Пассажирские перевозки Томск – Астана Развитая сеть пассажирских перевозок играет ключевую роль в обеспечении мобильности населения и укреплении экономических связей между регионами. Наша компания специализируется на организации регулярных и безопасных поездок между городами Сибири и Казахстана, предлагая комфортные условия и доступные цены.
Профессиональный вывод из запоя – это комплексная медицинская услуга, направленная на безопасное и оперативное лечение пациентов, столкнувшихся с алкогольной интоксикацией. В Донецке ДНР высококвалифицированные наркологи оказывают помощь на дому, что позволяет начать детоксикацию организма в комфортной и привычной обстановке. Такой подход обеспечивает индивидуальную терапию, всестороннюю поддержку и полную конфиденциальность, что особенно важно для тех, кто предпочитает получать лечение вне стационаров.
Изучить вопрос глубже – срочный вывод из запоя в донецке
Запой — это не просто продолжительное пьянство, а острое состояние, требующее срочной медицинской помощи. Без профессионального вмешательства организм человека стремительно разрушается, возрастает риск инфаркта, инсульта, алкогольного психоза и летального исхода. Именно поэтому вывод из запоя должен проходить под контролем нарколога, с использованием проверенных медикаментов и поэтапной схемы стабилизации. В наркологической клинике «ВитаМед Плюс» организована круглосуточная помощь в Химках, включая выезд врача на дом и приём в стационаре.
Выяснить больше – вывод из запоя капельница в химках
Во всех этих случаях промедление может стоить слишком дорого. Наркологическая помощь должна быть оказана немедленно — либо на дому, либо в условиях клиники.
Углубиться в тему – наркология вывод из запоя
Применение автоматизированных систем дозирования гарантирует точное введение медикаментов, что минимизирует риск передозировки и побочных эффектов. Постоянный мониторинг жизненно важных показателей даёт врачу возможность оперативно корректировать терапевтическую схему, обеспечивая максимальную безопасность процедуры.
Получить дополнительные сведения – нарколог вывод из запоя
Вывод из запоя обязателен, если:
Детальнее – наркологический вывод из запоя химки
Запой — это не просто продолжительное пьянство, а острое состояние, требующее срочной медицинской помощи. Без профессионального вмешательства организм человека стремительно разрушается, возрастает риск инфаркта, инсульта, алкогольного психоза и летального исхода. Именно поэтому вывод из запоя должен проходить под контролем нарколога, с использованием проверенных медикаментов и поэтапной схемы стабилизации. В наркологической клинике «ВитаМед Плюс» организована круглосуточная помощь в Химках, включая выезд врача на дом и приём в стационаре.
Ознакомиться с деталями – https://vyvod-iz-zapoya-v-himki1.ru/vyvod-iz-zapoya-cena-v-himkah
Состояние пациента стабилизируется за счёт коррекции давления, нормализации пульса, снятия тремора и тревожности. Для защиты печени применяются гепатопротекторы, а для восстановления функций мозга — препараты нейрометаболического действия. При необходимости назначаются витамины группы B, седативные средства, препараты для восстановления сна.
Подробнее тут – вывод из запоя цена
Если вы видите, что близкий не может выйти из запоя самостоятельно, или если после нескольких дней употребления появились тревожные симптомы — не ждите. Помощь нужна уже сейчас.
Детальнее – vyvod-iz-zapoya-kruglosutochno himki
Мы не делаем «массовых решений»: каждый пациент для нас — уникальная история, и мы строим терапию, исходя из его состояния, целей и личных возможностей. Наша задача — не просто временно облегчить симптомы, а дать человеку реальные инструменты для жизни без зависимости.
Подробнее – https://narkologicheskaya-klinika-mytishchi1.ru/chastnaya-narkologicheskaya-klinika-v-mytishchah
Преимущества вывода из запоя от опытных специалистов в условиях Донецка ДНР многочисленны. Такой формат лечения позволяет:
Детальнее – https://vyvod-iz-zapoya-donetsk-dnr00.ru/vyvod-iz-zapoya-kruglosutochno-doneczk-dnr
Процесс лечения строится из нескольких ключевых этапов, каждый из которых направлен на оперативное восстановление состояния пациента:
Ознакомиться с деталями – вывод из запоя недорого донецк
При тяжелой алкогольной интоксикации оперативное лечение становится жизненно необходимым для спасения здоровья. В Архангельске специалисты оказывают помощь на дому, используя метод капельничного лечения от запоя. Такой подход позволяет быстро вывести токсины, восстановить обмен веществ и стабилизировать работу внутренних органов, обеспечивая при этом высокий уровень конфиденциальности и комфорт в условиях привычного домашнего уюта.
Подробнее можно узнать тут – капельница от запоя архангельская область
Состояние пациента стабилизируется за счёт коррекции давления, нормализации пульса, снятия тремора и тревожности. Для защиты печени применяются гепатопротекторы, а для восстановления функций мозга — препараты нейрометаболического действия. При необходимости назначаются витамины группы B, седативные средства, препараты для восстановления сна.
Изучить вопрос глубже – вывод из запоя в стационаре
Наркологическая клиника «Возрождение» в Уфе предоставляет полный спектр услуг по лечению зависимости от психоактивных веществ и алкоголя. Мы сочетаем проверенные временем медицинские методики с инновационными технологиями, сохраняя полную анонимность пациентов. В любом случае вы можете рассчитывать на круглосуточную поддержку, комфортные условия пребывания и индивидуальный план терапии, составленный опытными специалистами.
Исследовать вопрос подробнее – наркологическая клиника республика башкортостан
Запой — это состояние, при котором человек на протяжении нескольких дней или недель регулярно употребляет алкоголь, теряя контроль над собой. При этом организм накапливает этанол и его токсичные метаболиты, печень и сердце работают на износ, нарушается сон, развивается психоэмоциональная нестабильность. Главный риск — абстинентный синдром, который может проявляться тремором, судорогами, повышением давления, паникой и даже галлюцинациями.
Изучить вопрос глубже – срочный вывод из запоя
Если вы видите, что близкий не может выйти из запоя самостоятельно, или если после нескольких дней употребления появились тревожные симптомы — не ждите. Помощь нужна уже сейчас.
Исследовать вопрос подробнее – http://vyvod-iz-zapoya-v-himki1.ru
После первичной диагностики начинается активная фаза медикаментозного вмешательства. Современные препараты вводятся капельничным методом, что позволяет быстро снизить уровень токсинов в крови, восстановить нормальный обмен веществ и стабилизировать работу внутренних органов. Этот этап играет решающую роль в безопасном выводе из запоя.
Исследовать вопрос подробнее – https://vyvod-iz-zapoya-donetsk-dnr00.ru
Каждый пациент проходит три основные стадии терапии, начиная с момента первого обращения.
Исследовать вопрос подробнее – частная наркологическая клиника республика башкортостан
Эта статья полна интересного контента, который побудит вас исследовать новые горизонты. Мы собрали полезные факты и удивительные истории, которые обогащают ваше понимание темы. Читайте, погружайтесь в детали и наслаждайтесь процессом изучения!
Выяснить больше – https://techheralds.com/uncategorized/review-post-percent
Your point of view caught my eye and was very interesting. Thanks. I have a question for you.
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Выяснить больше – https://www.zetaecorp.com/etibarl-mostbet-cari-mobil-proqram-2
Эта статья сочетает познавательный и занимательный контент, что делает ее идеальной для любителей глубоких исследований. Мы рассмотрим увлекательные аспекты различных тем и предоставим вам новые знания, которые могут оказаться полезными в будущем.
Изучить вопрос глубже – http://www.abram.cc/index.php?showimage=164
Эта познавательная публикация погружает вас в море интересного контента, который быстро захватит ваше внимание. Мы рассмотрим важные аспекты темы и предоставим вам уникальныеInsights и полезные сведения для дальнейшего изучения.
Исследовать вопрос подробнее – https://epiczo.com/?p=256
В данной обзорной статье представлены интригующие факты, которые не оставят вас равнодушными. Мы критикуем и анализируем события, которые изменили наше восприятие мира. Узнайте, что стоит за новыми открытиями и как они могут изменить ваше восприятие реальности.
Подробнее можно узнать тут – https://springpaddocksequine.co.uk/buying-a-horse
Этот интересный отчет представляет собой сборник полезных фактов, касающихся актуальных тем. Мы проанализируем данные, чтобы вы могли сделать обоснованные выводы. Читайте, чтобы узнать больше о последних трендах и значимых событиях!
Подробнее – https://www.ignifugospina.es/2022/08/22/facebook-paypal-and-you-will-tractor-likewise-have
Этот увлекательный информационный материал подарит вам массу новых знаний и ярких эмоций. Мы собрали для вас интересные факты и сведения, которые обогатят ваш опыт. Откройте для себя увлекательный мир информации и насладитесь процессом изучения!
Подробнее тут – https://keozenit.com/gallery/donec-acex
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Изучить вопрос глубже – https://www.washingtonsqderm.com/the-15-very-best-cystic-acne-treatments
Эта обзорная заметка содержит ключевые моменты и факты по актуальным вопросам. Она поможет читателям быстро ориентироваться в теме и узнать о самых важных аспектах сегодня. Получите краткий курс по современной информации и оставайтесь в курсе событий!
Подробнее – https://www.nuloinnovations.com/hot-stamping
«Рентвил» предлагает аренду автомобилей в Краснодаре без залога и ограничений по пробегу по Краснодарскому краю и Адыгее. Требуется стаж от 3 лет и возраст от 23 лет. Оформление за 5 минут онлайн: нужны только фото паспорта и прав. Подача авто на жд вокзал и аэропорт Краснодар Мин-воды Сочи . Компания работает 10 лет , автомобили проходят своевременное ТО. Доступны детские кресла. Бронируйте через сайт машина в аренду краснодар
Услуга вывода из запоя на дому в Мурманске предполагает комплексное лечение алкогольной интоксикации, направленное на оперативное снижение уровня токсинов в организме. Сразу после поступления вызова специалист проводит детальный осмотр, собирает анамнез и определяет степень интоксикации. На основании собранной информации разрабатывается индивидуальный план терапии, который может включать капельничное введение медикаментов, контроль жизненно важных показателей и психологическую поддержку. Такой комплекс мер позволяет стабилизировать состояние пациента и начать процесс выздоровления без необходимости посещения стационара.
Разобраться лучше – вывод из запоя недорого в мурманске
Токарные патроны Bison Токарные патроны Bison Запчасти для станков Bison Bial В мире металлообработки, где точность и надежность играют ключевую роль, токарные патроны Bison занимают особое место. Эти инструменты, производимые известной польской компанией Bison Bial, зарекомендовали себя как высококачественные и долговечные компоненты для токарных станков. Они обеспечивают надежный зажим заготовок, что напрямую влияет на качество и скорость обработки.
Если вы видите, что близкий не может выйти из запоя самостоятельно, или если после нескольких дней употребления появились тревожные симптомы — не ждите. Помощь нужна уже сейчас.
Узнать больше – вывод из запоя цена химки.
Возможность получить помощь в любой час снижает риск осложнений и ускоряет стабилизацию состояния. Среди главных преимуществ:
Получить больше информации – https://narkologicheskaya-pomoshh-ufa9.ru/skoraya-narkologicheskaya-pomoshh-ufa
После первичной диагностики начинается активная фаза медикаментозного вмешательства. Препараты вводятся капельничным методом для быстрого снижения уровня токсинов в крови, нормализации обменных процессов и стабилизации работы внутренних органов, таких как печень, почки и сердце.
Подробнее можно узнать тут – http://narcolog-na-dom-mariupol00.ru/
Они приближались, становились отчетливыми, видимыми до последнего деревца. Примеры Нотариального Перевода Паспорта Анисья Федоровна охотно пошла своей легкой поступью исполнить поручение своего господина и принесла гитару.
Затяжной запой и острая алкогольная интоксикация требуют немедленного вмешательства специалистов. Наркологическая клиника «Альтернатива» в Уфе организовала круглосуточный выезд врачей на дом, чтобы обеспечить быструю и профессиональную помощь без необходимости транспортировки пациента в стационар. Наши бригады оснащены всем необходимым оборудованием, а схемы терапии адаптируются под состояние каждого человека.
Ознакомиться с деталями – https://narkologicheskaya-pomoshh-ufa9.ru/narkologicheskaya-pomoshh-na-domu-ufa/
Когда состояние алкогольной интоксикации достигает критических уровней, своевременное вмешательство становится жизненно необходимым. В Мариуполе, Донецкая область, высококвалифицированные наркологи оказывают срочную помощь на дому, позволяя оперативно начать детоксикацию и стабилизировать состояние пациента. Такой формат лечения обеспечивает быстрый выход из кризиса в условиях комфорта и конфиденциальности, что особенно важно для тех, кто не может позволить себе задержки в стационарном лечении.
Получить больше информации – нарколог на дом вывод в мариуполе
В Сочи решение есть — наркологическая клиника. Здесь помогают людям выйти из запоя без страха и осуждения. Всё анонимно, грамотно и с заботой о каждом пациенте.
Ознакомиться с деталями – вывод из запоя в стационаре
Если вы видите, что близкий не может выйти из запоя самостоятельно, или если после нескольких дней употребления появились тревожные симптомы — не ждите. Помощь нужна уже сейчас.
Подробнее – http://vyvod-iz-zapoya-v-himki1.ru
Ростов взял в руки кошелек и посмотрел и на него, и на деньги, которые были в нем, и на Телянина. Нотариальный Перевод Документов Украина Гера пропустила Русану вперед, сама задержалась, отдавая Арчане распоряжения: – Вернусь дней через двадцать, не раньше.
Вывод из запоя обязателен, если:
Детальнее – https://vyvod-iz-zapoya-v-himki1.ru/narkolog-vyvod-iz-zapoya-v-himkah
Недостаточно снять физическую зависимость — важно помочь человеку вернуться в сообщество. В «Доктор Здоровье» разработана система сопровождения, включающая мотивационные беседы, групповые занятия и социальную реабилитацию. Психотерапевты владеют методами когнитивно-поведенческой терапии и мотивационного интервью, консультанты помогают восстановить профессиональные навыки и адаптироваться к повседневной жизни, а встречи в группе взаимопомощи и психодраматические сессии способствуют укреплению чувства поддержки и навыков эффективного общения. Для родственников доступны семейные консультации, на которых объясняют природу зависимости и обучают стратегиям поддержки без критики и давления.
Изучить вопрос глубже – https://narkologicheskaya-klinika-mytishchi1.ru/narkologicheskaya-klinika-narkolog-v-mytishchah
Мы используем новейшие образцы медицинской техники, что повышает безопасность процедур и скорость детоксикации.
Изучить вопрос глубже – скорая наркологическая помощь уфа.
Он смотрел мутными глазами на арестованного и некоторое время молчал, мучительно вспоминая, зачем на утреннем безжалостном ершалаимском солнцепеке стоит перед ним арестант с обезображенным побоями лицом и какие еще никому не нужные вопросы ему придется задавать. Займ Денег В Геленджике Казалось, они жили собственной жизнью, отдельно от хозяйки.
Для безопасного и эффективного лечения дома необходимо:
Разобраться лучше – http://narkologicheskaya-pomoshh-ufa9.ru
Выкуп с 1688 В эпоху глобализации и стремительного развития мировой экономики, Китай занимает ключевую позицию в качестве крупнейшего производственного центра. Организация эффективных и надежных поставок товаров из Китая становится стратегически важной задачей для предприятий, стремящихся к оптимизации затрат и расширению ассортимента. Наша компания предлагает комплексные решения для вашего бизнеса, обеспечивая бесперебойные и выгодные поставки товаров напрямую из Китая.
Затяжной запой и острая алкогольная интоксикация требуют немедленного вмешательства специалистов. Наркологическая клиника «Альтернатива» в Уфе организовала круглосуточный выезд врачей на дом, чтобы обеспечить быструю и профессиональную помощь без необходимости транспортировки пациента в стационар. Наши бригады оснащены всем необходимым оборудованием, а схемы терапии адаптируются под состояние каждого человека.
Узнать больше – skoraya narkologicheskaya pomoshch ufa
Возможность получить помощь в любой час снижает риск осложнений и ускоряет стабилизацию состояния. Среди главных преимуществ:
Ознакомиться с деталями – круглосуточная наркологическая помощь
Вот и всё, – он тяжело опустился на лавку, сложил руки на груди, вперекрест. Пудож Центрофинанс Льняная одежда слишком светлая, а не надо, чтобы его заметили.
Клиника «Возрождение» гарантирует:
Исследовать вопрос подробнее – наркологические клиники алкоголизм
На данном этапе врач уточняет, как долго продолжается запой, какой тип алкоголя употребляется и имеются ли сопутствующие заболевания. Детальный анализ клинических данных помогает подобрать оптимальные методы детоксикации и минимизировать риск осложнений.
Получить дополнительную информацию – вывод из запоя капельница
Мы используем новейшие образцы медицинской техники, что повышает безопасность процедур и скорость детоксикации.
Подробнее – narkologicheskaya pomoshch na domu ufa
Врач уточняет, как долго продолжается запой, какой алкоголь употребляется и имеются ли сопутствующие заболевания. Тщательный анализ этих данных позволяет подобрать оптимальные методы детоксикации и снизить риск осложнений.
Исследовать вопрос подробнее – вызов нарколога на дом
Когда запой становится угрозой для жизни и здоровья, своевременная помощь профессионала может стать решающим фактором для скорейшего восстановления. В Мурманске, где суровые климатические условия добавляют стресса и осложнений, квалифицированные наркологи оказывают помощь на дому, обеспечивая оперативную детоксикацию и индивидуальную терапию в привычной обстановке. Такой подход позволяет пациентам избежать лишних перемещений и получить поддержку в комфортной атмосфере.
Узнать больше – наркология вывод из запоя в мурманске
После диагностики начинается активная фаза медикаментозного вмешательства. Современные препараты вводятся капельничным методом, что позволяет быстро снизить уровень токсинов в крови, восстановить нормальные обменные процессы и стабилизировать работу жизненно важных органов, таких как печень, почки и сердце.
Получить больше информации – вывод из запоя капельница в мурманске
Дара обжала мышцу – остаток крови вытек из раны, чистая тряпица отерла её. Секс Знакомства Тверская Область Амулет, который пропитан нашим временем.
One thing I want to say is always that car insurance termination is a feared experience and if you are doing the correct things being a driver you won’t get one. A number of people do obtain notice that they are officially dropped by their own insurance company they then have to fight to get additional insurance after a cancellation. Low-priced auto insurance rates are generally hard to get from a cancellation. Having the main reasons for auto insurance cancellations can help owners prevent burning off one of the most significant privileges accessible. Thanks for the concepts shared through your blog.
После первичной диагностики начинается активная фаза медикаментозного вмешательства. Препараты вводятся капельничным методом для быстрого снижения уровня токсинов в крови, нормализации обменных процессов и стабилизации работы внутренних органов, таких как печень, почки и сердце.
Ознакомиться с деталями – вызов врача нарколога на дом в мариуполе
I will immediately grasp your rss feed as I can’t find your e-mail subscription link or newsletter service. Do you’ve any? Please let me understand so that I could subscribe. Thanks.
Во всех этих случаях промедление может стоить слишком дорого. Наркологическая помощь должна быть оказана немедленно — либо на дому, либо в условиях клиники.
Ознакомиться с деталями – vyvod-iz-zapoya-v-himki1.ru/
Услуга вывода из запоя на дому в Мурманске предполагает комплексное лечение алкогольной интоксикации, направленное на оперативное снижение уровня токсинов в организме. Сразу после поступления вызова специалист проводит детальный осмотр, собирает анамнез и определяет степень интоксикации. На основании собранной информации разрабатывается индивидуальный план терапии, который может включать капельничное введение медикаментов, контроль жизненно важных показателей и психологическую поддержку. Такой комплекс мер позволяет стабилизировать состояние пациента и начать процесс выздоровления без необходимости посещения стационара.
Исследовать вопрос подробнее – вывод из запоя на дому круглосуточно мурманск
Помощь нарколога на дому в Мурманске обладает рядом неоспоримых преимуществ, которые делают данный метод лечения особенно актуальным:
Детальнее – https://vyvod-iz-zapoya-murmansk0.ru/vyvod-iz-zapoya-kruglosutochno-murmansk/
Но вместо того, чтобы пролететь насквозь, камни звучно шлёпнули и отскочили. Нотариальный Перевод Документов Зеленоград – Ты зря это, – покачал головой тот, застеснявшись в очередной раз, – мама не любит, когда её вещами пользуются… – Так не говори, она и не узнает.
Вывод из запоя обязателен, если:
Получить дополнительные сведения – вывод из запоя в стационаре в химках
После первичной диагностики начинается активная фаза медикаментозного вмешательства. Препараты вводятся капельничным методом для быстрого снижения уровня токсинов в крови, нормализации обменных процессов и стабилизации работы внутренних органов, таких как печень, почки и сердце.
Ознакомиться с деталями – vrach-narkolog-na-dom mariupol’
Услуга “Нарколог на дом” в Мариуполе, Донецкая область, предусматривает оперативное оказание медицинской помощи при запое. После получения вызова специалист незамедлительно выезжает к пациенту, проводит детальный осмотр, измеряет жизненно важные показатели и собирает анамнез. На основе полученных данных разрабатывается индивидуальный план терапии, включающий медикаментозную детоксикацию, инфузионную терапию и психологическую поддержку. Такой комплексный подход позволяет эффективно вывести токсины из организма и предотвратить развитие осложнений.
Исследовать вопрос подробнее – нарколог на дом
– Бедная девочка. Договор Займа Денег В Республике Казахстан Глава 30 Похищение? – Осторожно, не задушите! Мальчишки брыкались, пытаясь вырваться, выпутаться.
Этот информативный текст отличается привлекательным содержанием и актуальными данными. Мы предлагаем читателям взглянуть на привычные вещи под новым углом, предоставляя интересный и доступный материал. Получите удовольствие от чтения и расширьте кругозор!
Ознакомиться с деталями – https://tlcooljc.org/home_02
Эта статья предлагает захватывающий и полезный контент, который привлечет внимание широкого круга читателей. Мы постараемся представить тебе идеи, которые вдохновят вас на изменения в жизни и предоставят практические решения для повседневных вопросов. Читайте и вдохновляйтесь!
Изучить вопрос глубже – http://aocassia.com/blog/2324.html
Эта статья сочетает в себе как полезные, так и интересные сведения, которые обогатят ваше понимание насущных тем. Мы предлагаем практические советы и рекомендации, которые легко внедрить в повседневную жизнь. Узнайте, как улучшить свои навыки и обогатить свой опыт с помощью простых, но эффективных решений.
Выяснить больше – https://havilot-nofesh.co.il/portfolio-masonry
– Недолго подумав, указал Семёну небольшую бухту. Секс Онлайн Видео Знакомства Бесплатно – Не понимаем.
В этой статье вы найдете познавательную и занимательную информацию, которая поможет вам лучше понять мир вокруг. Мы собрали интересные данные, которые вдохновляют на размышления и побуждают к действиям. Открывайте новую информацию и получайте удовольствие от чтения!
Изучить вопрос глубже – https://bandhit.srru.ac.th/2023/07/09/background
Баллисту уже напрягли, даже заряжали камень. Стоимость Перевод Паспорта С Нотариальным Заверением — Так вы сделаете это? — тихо спросила Маргарита.
Эта обзорная заметка содержит ключевые моменты и факты по актуальным вопросам. Она поможет читателям быстро ориентироваться в теме и узнать о самых важных аспектах сегодня. Получите краткий курс по современной информации и оставайтесь в курсе событий!
Выяснить больше – https://kalyankesari.com/?p=18836
Когда организм на пределе, важна срочная помощь в Сочи — это команда опытных наркологов, которые помогут быстро и мягко выйти из запоя без вреда для здоровья.
Углубиться в тему – вывод из запоя цена
Медикаментозное лечение: Мы применяем современные препараты, которые помогают облегчить симптомы абстиненции и улучшить состояние пациентов в первые дни лечения. Индивидуальный подбор лекарственных схем позволяет минимизировать побочные эффекты и достичь наилучших результатов.
Выяснить больше – https://srochnyj-vyvod-iz-zapoya.ru/
Обращение за помощью к профессионалам в условиях домашнего лечения имеет ряд важных преимуществ:
Разобраться лучше – http://vyvod-iz-zapoya-donetsk-dnr0.ru/vyvod-iz-zapoya-na-domu-doneczk-dnr/https://vyvod-iz-zapoya-donetsk-dnr0.ru
Шкаф Кухня – сердце дома, место, где рождаются кулинарные шедевры и собирается вся семья. Именно поэтому выбор мебели для кухни – задача ответственная и требующая особого подхода. Мебель на заказ в Краснодаре – это возможность создать уникальное пространство, идеально отвечающее вашим потребностям и предпочтениям.
Алкогольная зависимость разрушает здоровье, семью, карьеру и личность. Чем раньше будет оказана профессиональная помощь, тем выше шансы на восстановление и возвращение к полноценной жизни. Лечение алкоголизма в Воронеже — помощь на всех стадиях зависимости позволяет справляться не только с физической тягой, но и с глубинными причинами, которые провоцируют патологическое употребление.
Получить дополнительную информацию – центр лечения алкоголизма воронеж
Клиническая практика показывает: только системная работа с пациентом даёт устойчивый результат. Программа включает медицинское, психологическое и социальное сопровождение.
Выяснить больше – https://lechenie-alkogolizma-voronezh9.ru/czentr-lecheniya-alkogolizma-voronezh/
Свежие актуальные свежие новости спорта со всего мира. Результаты матчей, интервью, аналитика, расписание игр и обзоры соревнований. Будьте в курсе главных событий каждый день!
Во всех этих случаях промедление может стоить слишком дорого. Наркологическая помощь должна быть оказана немедленно — либо на дому, либо в условиях клиники.
Подробнее – вывод из запоя анонимно химки
На этом этапе проводится полное обследование: анализы, ЭКГ, оценка состояния печени, сердца и нервной системы. Врач-нарколог формирует индивидуальный план терапии с учётом стажа употребления и общего состояния пациента.
Ознакомиться с деталями – http://lechenie-alkogolizma-voronezh9.ru
Клиническая практика показывает: только системная работа с пациентом даёт устойчивый результат. Программа включает медицинское, психологическое и социальное сопровождение.
Подробнее можно узнать тут – https://lechenie-alkogolizma-voronezh9.ru/lechenie-narkomanii-i-alkogolizma-voronezh
Запой — это не просто продолжительное пьянство, а острое состояние, требующее срочной медицинской помощи. Без профессионального вмешательства организм человека стремительно разрушается, возрастает риск инфаркта, инсульта, алкогольного психоза и летального исхода. Именно поэтому вывод из запоя должен проходить под контролем нарколога, с использованием проверенных медикаментов и поэтапной схемы стабилизации. В наркологической клинике «ВитаМед Плюс» организована круглосуточная помощь в Химках, включая выезд врача на дом и приём в стационаре.
Узнать больше – вывод из запоя на дому круглосуточно в химках
Недостаточно снять физическую зависимость — важно помочь человеку вернуться в сообщество. В «Доктор Здоровье» разработана система сопровождения, включающая мотивационные беседы, групповые занятия и социальную реабилитацию. Психотерапевты владеют методами когнитивно-поведенческой терапии и мотивационного интервью, консультанты помогают восстановить профессиональные навыки и адаптироваться к повседневной жизни, а встречи в группе взаимопомощи и психодраматические сессии способствуют укреплению чувства поддержки и навыков эффективного общения. Для родственников доступны семейные консультации, на которых объясняют природу зависимости и обучают стратегиям поддержки без критики и давления.
Детальнее – https://narkologicheskaya-klinika-mytishchi1.ru/chastnaya-narkologicheskaya-klinika-v-mytishchah/
Близкий человек в запое? Не ждите ухудшения. Обратитесь в клинику Сочи — здесь проведут профессиональный вывод из запоя с последующим восстановлением организма.
Детальнее – вывод из запоя
После снятия острых симптомов пациент продолжает получать медикаментозную поддержку. Назначаются витамины, гепатопротекторы, успокоительные препараты. Проводится психологическая диагностика для подготовки к следующему этапу — реабилитации.
Получить дополнительную информацию – клиника лечения алкоголизма воронеж.
На этом этапе проводится полное обследование: анализы, ЭКГ, оценка состояния печени, сердца и нервной системы. Врач-нарколог формирует индивидуальный план терапии с учётом стажа употребления и общего состояния пациента.
Выяснить больше – наркология лечение алкоголизма
После стабилизации состояния назначаются препараты, укрепляющие печень, сердце и нервную систему. Обязателен контроль за самочувствием пациента в течение суток и более.
Ознакомиться с деталями – narkologicheskaya klinika voronezh
После снятия острых симптомов пациент продолжает получать медикаментозную поддержку. Назначаются витамины, гепатопротекторы, успокоительные препараты. Проводится психологическая диагностика для подготовки к следующему этапу — реабилитации.
Подробнее тут – лечение алкоголизма воронеж
Самостоятельно выйти из запоя — почти невозможно. В Сочи врачи клиники проводят медикаментозный вывод из запоя с круглосуточным выездом. Доверяйте профессионалам.
Изучить вопрос глубже – вывод из запоя цена
В современном обществе проблемы наркомании и алкоголизма приобрели особую актуальность, затрагивая не только отдельных людей, но и их близких, и сообщества. Эти зависимости оказывают негативное влияние не только на физическое здоровье, но и на психоэмоциональное состояние, нарушают социальные связи и ухудшают качество жизни. Наркологическая клиника “Здоровое Настоящее” предлагает комплексный и научно обоснованный подход к лечению зависимостей. Мы используем современные методы диагностики и терапии, чтобы помочь пациентам вернуть здоровье и полноценную жизнь.
Разобраться лучше – наркология вывод из запоя в казани
При поступлении вызова нарколог незамедлительно прибывает на дом для проведения детального первичного осмотра. Врач измеряет жизненно важные показатели, такие как пульс, артериальное давление и температура, а также собирает краткий анамнез, чтобы определить степень алкогольной интоксикации и сформировать индивидуальный план терапии.
Получить дополнительные сведения – vyvod-iz-zapoya-kruglosutochno donetsk
Затяжной запой опасен для жизни. Врачи наркологической клиники в Сочи проводят срочный вывод из запоя — на дому или в стационаре. Анонимно, безопасно, круглосуточно.
Детальнее – вывод из запоя
Психологическая реабилитация: Психологическая поддержка – один из главных аспектов нашего подхода. Мы предлагаем индивидуальные и групповые занятия, помогающие осознать зависимость, проработать эмоциональные травмы и сформировать новые модели поведения. Опытные психологи помогают пациентам понять причины своих зависимостей, что является важным шагом на пути к выздоровлению.
Получить больше информации – вывод из запоя
На этом этапе специалист уточняет, сколько времени продолжается запой, какой вид алкоголя употребляется и имеются ли сопутствующие заболевания. Тщательный анализ собранной информации позволяет оперативно подобрать оптимальные методы детоксикации и минимизировать риск осложнений.
Разобраться лучше – narkolog-vyvod-iz-zapoya donetsk
Создание безопасной среды: Мы понимаем, насколько важна поддержка в сложные моменты. Наш центр предоставляет пространство, где пациенты могут открыто говорить о своих переживаниях без страха быть осужденными, что способствует доверию и успешному лечению.
Выяснить больше – http://srochnyj-vyvod-iz-zapoya.ru
Применение автоматизированных систем дозирования обеспечивает точное введение лекарственных средств, минимизируя риск передозировки и побочных эффектов. Постоянный мониторинг жизненно важных показателей позволяет врачу корректировать терапевтическую схему в режиме реального времени для обеспечения максимальной безопасности.
Получить дополнительную информацию – http://vyvod-iz-zapoya-donetsk-dnr0.ru/vyvod-iz-zapoya-na-domu-doneczk-dnr/
Самостоятельно выйти из запоя — почти невозможно. В Сочи врачи клиники проводят медикаментозный вывод из запоя с круглосуточным выездом. Доверяйте профессионалам.
Подробнее можно узнать тут – вывод из запоя в стационаре
Incredible! This blog looks just like my old one! It’s on a completely different subject but it has pretty much the same layout and design. Outstanding choice of colors!
Hey there! This post could not be written any better! Reading through this post reminds me of my good old room mate! He always kept chatting about this. I will forward this article to him. Fairly certain he will have a good read. Many thanks for sharing!
Если вы видите, что близкий не может выйти из запоя самостоятельно, или если после нескольких дней употребления появились тревожные симптомы — не ждите. Помощь нужна уже сейчас.
Выяснить больше – вывод из запоя на дому
Образовательные программы: Мы уверены, что знания о зависимости и её последствиях играют важную роль в реабилитации. Мы информируем пациентов о механизмах действия наркотиков и алкоголя на организм, что способствует изменению их отношения к терапии и жизни без зависимостей.
Ознакомиться с деталями – http://srochnyj-vyvod-iz-zapoya.ru
На этом этапе специалист уточняет, сколько времени продолжается запой, какой вид алкоголя употребляется и имеются ли сопутствующие заболевания. Тщательный анализ собранной информации позволяет оперативно подобрать оптимальные методы детоксикации и минимизировать риск осложнений.
Детальнее – вывод из запоя на дому круглосуточно донецк
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me.
Во всех этих случаях промедление может стоить слишком дорого. Наркологическая помощь должна быть оказана немедленно — либо на дому, либо в условиях клиники.
Детальнее – http://vyvod-iz-zapoya-v-himki1.ru/
В этом интересном тексте собраны обширные сведения, которые помогут вам понять различные аспекты обсуждаемой темы. Мы разбираем детали и факты, делая акцент на важности каждого элемента. Не упустите возможность расширить свои знания и взглянуть на мир по-новому!
Разобраться лучше – https://www.karolina-jankowska.eu/zalacznik_nr_3_strona_instytutu_politologii_03-04-2013_ogloszenie_wynikow_konkursu-2
Эта статья для ознакомления предлагает читателям общее представление об актуальной теме. Мы стремимся представить ключевые факты и идеи, которые помогут читателям получить представление о предмете и решить, стоит ли углубляться в изучение.
Подробнее тут – https://www.riferimenti.org/shinjyukuku/ochiaiminaminagasaki
Эта обзорная заметка содержит ключевые моменты и факты по актуальным вопросам. Она поможет читателям быстро ориентироваться в теме и узнать о самых важных аспектах сегодня. Получите краткий курс по современной информации и оставайтесь в курсе событий!
Выяснить больше – https://fiona-limar.de/der-zehnte-schwedenthriller-und-ein-gewinnspiel
В этой статье-обзоре мы соберем актуальную информацию и интересные факты, которые освещают важные темы. Читатели смогут ознакомиться с различными мнениями и подходами, что позволит им расширить кругозор и глубже понять обсуждаемые вопросы.
Выяснить больше – https://www.nswr.it/prime-day-2021
Эта статья для ознакомления предлагает читателям общее представление об актуальной теме. Мы стремимся представить ключевые факты и идеи, которые помогут читателям получить представление о предмете и решить, стоит ли углубляться в изучение.
Выяснить больше – https://vcelynastrechach.cz/evropa-v-datech
Микрозаймы онлайн https://kskredit.ru на карту — быстрое оформление, без справок и поручителей. Получите деньги за 5 минут, круглосуточно и без отказа. Доступны займы с любой кредитной историей.
Хочешь больше денег https://mfokapital.ru Изучай инвестиции, учись зарабатывать, управляй финансами, торгуй на Форекс и используй магию денег. Рабочие схемы, ритуалы, лайфхаки и инструкции — путь к финансовой независимости начинается здесь!
Этот увлекательный информационный материал подарит вам массу новых знаний и ярких эмоций. Мы собрали для вас интересные факты и сведения, которые обогатят ваш опыт. Откройте для себя увлекательный мир информации и насладитесь процессом изучения!
Разобраться лучше – https://misfitsdigital.com/brand-identity-why-branding-is-more-than-just-a-logo
Эта разъяснительная статья содержит простые и доступные разъяснения по актуальным вопросам. Мы стремимся сделать информацию понятной для широкой аудитории, чтобы каждый смог разобраться в предмете и извлечь из него максимум пользы.
Детальнее – https://ksausalegal.com/business-05
Быстрые микрозаймы https://clover-finance.ru без отказа — деньги онлайн за 5 минут. Минимум документов, максимум удобства. Получите займ с любой кредитной историей.
В этом информативном обзоре собраны самые интересные статистические данные и факты, которые помогут лучше понять текущие тренды. Мы представим вам цифры и графики, которые иллюстрируют, как развиваются различные сферы жизни. Эта информация станет отличной основой для глубокого анализа и принятия обоснованных решений.
Исследовать вопрос подробнее – https://brainstimtms.com/how-tms-helps-depression-among-va-in-2020-brainstim-usa
Предлагаем вашему вниманию интересную справочную статью, в которой собраны ключевые моменты и нюансы по актуальным вопросам. Эта информация будет полезна как для профессионалов, так и для тех, кто только начинает изучать тему. Узнайте ответы на важные вопросы и расширьте свои знания!
Узнать больше – https://aneja.org/brochure-aneja-2019
Сделай сам как сделать ремонт в старом Ремонт квартиры и дома своими руками: стены, пол, потолок, сантехника, электрика и отделка. Всё, что нужно — в одном месте: от выбора материалов до финального штриха. Экономьте с умом!
Специалист уточняет продолжительность запоя, тип употребляемого алкоголя и наличие сопутствующих заболеваний. Такой подробный анализ позволяет подобрать оптимальные методы детоксикации и снизить риск осложнений.
Исследовать вопрос подробнее – kapelnica-ot-zapoya-lugansk-lnr0.ru/
В этой информационной статье вы найдете интересное содержание, которое поможет вам расширить свои знания. Мы предлагаем увлекательный подход и уникальные взгляды на обсуждаемые темы, побуждая пользователей к активному мышлению и критическому анализу!
Подробнее тут – https://ristein-frisuren.de/fade-masterclass-behind-the-scenes-of-precision-styling
I have learned many important things through your post. I might also like to express that there is a situation that you will make application for a loan and don’t need a cosigner such as a National Student Support Loan. But when you are getting that loan through a common loan service then you need to be able to have a cosigner ready to assist you to. The lenders are going to base their decision on the few issues but the biggest will be your credit ratings. There are some financial institutions that will additionally look at your work history and make a decision based on this but in many instances it will be based on on your scores.
КПК «Доверие» https://bankingsmp.ru надежный кредитно-потребительский кооператив. Выгодные сбережения и доступные займы для пайщиков. Прозрачные условия, высокая доходность, финансовая стабильность и юридическая безопасность.
Thanks for enabling me to obtain new concepts about computer systems. I also hold the belief that one of the best ways to help keep your notebook in best condition is to use a hard plastic-type case, as well as shell, which fits over the top of the computer. A lot of these protective gear will be model unique since they are manufactured to fit perfectly in the natural casing. You can buy all of them directly from the owner, or through third party places if they are designed for your notebook computer, however only a few laptop can have a shell on the market. All over again, thanks for your guidelines.
Ваш финансовый гид https://kreditandbanks.ru — подбираем лучшие предложения по кредитам, займам и банковским продуктам. Рейтинг МФО, советы по улучшению КИ, юридическая информация и онлайн-сервисы.
На этом этапе специалист уточняет продолжительность запоя, тип употребляемого алкоголя и наличие сопутствующих заболеваний, что позволяет разработать персонализированный план терапии и оперативно выбрать методы детоксикации.
Подробнее – kapelnicza-ot-zapoya arhangel’sk
Образовательные программы: Мы уверены, что знания о зависимости и её последствиях играют важную роль в реабилитации. Мы информируем пациентов о механизмах действия наркотиков и алкоголя на организм, что способствует изменению их отношения к терапии и жизни без зависимостей.
Получить дополнительную информацию – вывод из запоя недорого в казани
При поступлении вызова нарколог незамедлительно приезжает на дом для проведения тщательного осмотра. Врач измеряет жизненно важные показатели, такие как пульс, артериальное давление и температура, а также собирает анамнез, чтобы определить степень алкогольной интоксикации.
Разобраться лучше – капельница от запоя цена архангельск
Капельница от запоя необходима, если у пациента наблюдаются следующие симптомы:
Получить дополнительную информацию – капельница от запоя
Наркологическая клиника «Новый шанс» — это специализированное учреждение, которое предоставляет профессиональную помощь людям, страдающим от алкогольной и наркотической зависимости. Наша цель — предложить эффективные методы лечения и всестороннюю поддержку, чтобы помочь пациентам преодолеть зависимость и вернуть контроль над своей жизнью.
Узнать больше – вывод из запоя клиника ростов-на-дону
Займы под залог https://srochnyye-zaymy.ru недвижимости — быстрые деньги на любые цели. Оформление от 1 дня, без справок и поручителей. Одобрение до 90%, выгодные условия, честные проценты. Квартира или дом остаются в вашей собственности.
Самостоятельно выйти из запоя — почти невозможно. В Сочи врачи клиники проводят медикаментозный вывод из запоя с круглосуточным выездом. Доверяйте профессионалам.
Углубиться в тему – вывод из запоя капельница
На месте врач проводит первичный осмотр, измеряет давление, пульс, сатурацию, оценивает уровень интоксикации и абстиненции. Далее назначается инфузионная терапия — капельница, направленная на дезинтоксикацию, восстановление электролитного баланса, купирование тревожности и нормализацию сна.
Исследовать вопрос подробнее – vyzov vracha narkologa na dom
Перед началом процедуры врач проводит осмотр: измеряет давление, пульс, уровень кислорода в крови, оценивает тяжесть абстинентного синдрома. В зависимости от результатов и наличия сопутствующих заболеваний составляется индивидуальный состав инфузионного раствора. Он может включать:
Подробнее тут – [url=https://kapelnica-ot-zapoya-msk55.ru/]vrach na dom kapelnitsa ot zapoia odintsovo[/url]
I have realized that of all types of insurance, medical insurance is the most controversial because of the turmoil between the insurance coverage company’s need to remain afloat and the customer’s need to have insurance policy. Insurance companies’ revenue on health plans are certainly low, consequently some companies struggle to earn profits. Thanks for the tips you talk about through your blog.
I?ll immediately grab your rss as I can’t find your email subscription link or e-newsletter service. Do you have any? Kindly let me know so that I could subscribe. Thanks.
Кроме того, клиника «Новый шанс» уделяет особое внимание профилактике рецидивов. Мы обучаем пациентов навыкам управления стрессом, эмоциональной регуляции и прививаем навыки здорового образа жизни. Наша цель — обеспечить долгосрочное восстановление и снизить риск возврата к зависимости.
Подробнее тут – http://www.domen.ru
В современном обществе проблемы наркомании и алкоголизма приобрели особую актуальность, затрагивая не только отдельных людей, но и их близких, и сообщества. Эти зависимости оказывают негативное влияние не только на физическое здоровье, но и на психоэмоциональное состояние, нарушают социальные связи и ухудшают качество жизни. Наркологическая клиника “Здоровое Настоящее” предлагает комплексный и научно обоснованный подход к лечению зависимостей. Мы используем современные методы диагностики и терапии, чтобы помочь пациентам вернуть здоровье и полноценную жизнь.
Углубиться в тему – вывод из запоя на дому цена казань
Специалист уточняет продолжительность запоя, тип употребляемого алкоголя и наличие сопутствующих заболеваний. Такой подробный анализ позволяет подобрать оптимальные методы детоксикации и снизить риск осложнений.
Подробнее – вызвать капельницу от запоя в луганске
При поступлении вызова нарколог незамедлительно приезжает на дом для проведения тщательного осмотра. Врач измеряет жизненно важные показатели, такие как пульс, артериальное давление и температура, а также собирает анамнез, чтобы определить степень алкогольной интоксикации.
Углубиться в тему – http://kapelnica-ot-zapoya-arkhangelsk0.ru
Профессиональный вывод из запоя на дому в Луганске ЛНР организован по отлаженной схеме, которая включает несколько этапов, позволяющих обеспечить максимально безопасное и эффективное лечение.
Узнать больше – капельница от запоя на дому цена в луганске
Обращение за капельничной терапией от запоя в домашних условиях имеет множество преимуществ, среди которых:
Разобраться лучше – врач на дом капельница от запоя в луганске
При поступлении вызова нарколог незамедлительно приезжает на дом для проведения тщательного осмотра. Врач измеряет жизненно важные показатели, такие как пульс, артериальное давление и температура, а также собирает анамнез, чтобы определить степень алкогольной интоксикации.
Разобраться лучше – https://kapelnica-ot-zapoya-arkhangelsk0.ru/kapelnicza-ot-zapoya-klinika-arkhangelsk/
Запой — это не просто следствие чрезмерного употребления алкоголя, а серьёзное патологическое состояние, которое требует срочной медицинской помощи. На фоне затяжного приёма спиртного в организме человека происходят опасные изменения: интоксикация, обезвоживание, нарушение электролитного баланса, резкие скачки давления и работы сердца, угнетение функций печени и мозга. В такой ситуации капельница от запоя становится неотложной мерой, позволяющей стабилизировать состояние и устранить симптомы абстиненции за короткий срок.
Ознакомиться с деталями – капельница от запоя на дому одинцово
Специалист уточняет продолжительность запоя, тип употребляемого алкоголя и наличие сопутствующих заболеваний. Такой подробный анализ позволяет подобрать оптимальные методы детоксикации и снизить риск осложнений.
Получить больше информации – https://kapelnica-ot-zapoya-lugansk-lnr0.ru/kapelnicza-ot-zapoya-na-domu-lugansk-lnr
Обращение за капельничной терапией от запоя в домашних условиях имеет множество преимуществ, среди которых:
Выяснить больше – вызвать капельницу от запоя на дому
Перед началом процедуры врач проводит осмотр: измеряет давление, пульс, уровень кислорода в крови, оценивает тяжесть абстинентного синдрома. В зависимости от результатов и наличия сопутствующих заболеваний составляется индивидуальный состав инфузионного раствора. Он может включать:
Детальнее – вызвать капельницу от запоя
Услуга капельничного лечения от запоя на дому в Архангельске предусматривает комплексный подход, направленный на оперативное восстановление организма. Сразу после вызова нарколог прибывает на дом, проводит детальный осмотр, собирает анамнез и измеряет жизненно важные показатели. На основе этих данных разрабатывается персональный план терапии, который включает введение современных медикаментов с использованием автоматизированных систем дозирования, а также психологическую поддержку для создания условий долгосрочной ремиссии.
Подробнее – https://kapelnica-ot-zapoya-arkhangelsk0.ru/kapelnicza-ot-zapoya-na-domu-arkhangelsk/
После оформления заявки на сайте narcolog-na-dom-v-moskve55.ru или по телефону, оператор уточняет информацию о пациенте: возраст, длительность запоя, наличие хронических заболеваний, текущее самочувствие. В течение 30–60 минут дежурный специалист приезжает по адресу с полным комплектом оборудования и медикаментов.
Исследовать вопрос подробнее – narkolog na dom nedorogo
На этом этапе специалист уточняет продолжительность запоя, тип употребляемого алкоголя и наличие сопутствующих заболеваний, что позволяет разработать персонализированный план терапии и оперативно выбрать методы детоксикации.
Получить дополнительную информацию – [url=https://kapelnica-ot-zapoya-arkhangelsk0.ru/]капельница от запоя вызов город[/url]
Таким образом, наш подход направлен на создание комплексной системы поддержки, которая помогает каждому пациенту справиться с зависимостью и вернуться к полноценной жизни.
Подробнее можно узнать тут – вывод из запоя цена республика татарстан
Возможность назначить визит специалиста в наиболее удобное время. Это позволяет эффективно совмещать лечение с работой и повседневными делами. Такая гибкость помогает пациентам своевременно начать терапию, не откладывая ее из-за занятости. При необходимости врач может приехать в вечернее время или выходные дни.
Подробнее можно узнать тут – http://narcolog-na-dom-msk55.ru/
Лечебные мероприятия и рекомендации формируются исходя из индивидуального состояния каждого пациента. Специалист имеет возможность посвятить достаточное количество времени каждому больному, корректируя программу лечения согласно его особым потребностям и жизненным обстоятельствам. При этом учитываются психологические, социальные и физические аспекты, оказывающие влияние на здоровье пациента. Персонализированный подход обеспечивает оперативное реагирование на изменения состояния и своевременную корректировку терапии.
Углубиться в тему – http://
Перед началом процедуры врач проводит осмотр: измеряет давление, пульс, уровень кислорода в крови, оценивает тяжесть абстинентного синдрома. В зависимости от результатов и наличия сопутствующих заболеваний составляется индивидуальный состав инфузионного раствора. Он может включать:
Выяснить больше – вызвать капельницу от запоя одинцово
Дополнительно усиливаются сердечно-сосудистые риски: густая кровь, дефицит калия и магния провоцируют тахикардию, скачки давления и повышают вероятность инфаркта или инсульта. На этом фоне даже простая головная боль может оказаться сигналом серьёзного сосудистого нарушения. Задача капельницы — не просто убрать симптомы, а стабилизировать состояние организма и предотвратить дальнейшее ухудшение.
Изучить вопрос глубже – врача капельницу от запоя
Процесс лечения капельничным методом от запоя организован по четко структурированной схеме, позволяющей обеспечить оперативное и безопасное восстановление организма.
Выяснить больше – http://kapelnica-ot-zapoya-arkhangelsk0.ru/kapelnicza-ot-zapoya-czena-arkhangelsk/
Создание безопасной среды: Мы понимаем, насколько важна поддержка в сложные моменты. Наш центр предоставляет пространство, где пациенты могут открыто говорить о своих переживаниях без страха быть осужденными, что способствует доверию и успешному лечению.
Углубиться в тему – наркология вывод из запоя в казани
Когда организм на пределе, важна срочная помощь в Сочи — это команда опытных наркологов, которые помогут быстро и мягко выйти из запоя без вреда для здоровья.
Подробнее тут – вывод из запоя на дому
Отсутствие визитов в клинику гарантирует полную конфиденциальность. Это особенно важно для пациентов, беспокоящихся о своей репутации или возможном влиянии на профессиональную деятельность. Вызов врача на дом полностью исключает нежелательные встречи в медицинском центре.
Углубиться в тему – narcolog-na-dom-msk55.ru/
Инфузия проводится под постоянным контролем медицинского персонала. Длительность процедуры составляет от одного до трёх часов. Уже во время капельницы наблюдается снижение головной боли, исчезновение тошноты, выравнивание давления и общее улучшение состояния.
Выяснить больше – vyzvat kapelnitsu ot zapoia odintsovo
Наркологическая клиника «Новый шанс» — это специализированное учреждение, которое предоставляет профессиональную помощь людям, страдающим от алкогольной и наркотической зависимости. Наша цель — предложить эффективные методы лечения и всестороннюю поддержку, чтобы помочь пациентам преодолеть зависимость и вернуть контроль над своей жизнью.
Изучить вопрос глубже – вывод из запоя на дому круглосуточно ростов-на-дону
Команда клиники «Новый шанс» состоит из опытных специалистов-наркологов, которые имеют многолетнюю практику работы с пациентами, находящимися в зависимости, и регулярно совершенствуют свои знания.
Детальнее – вывод из запоя анонимно в ростове-на-дону
Препараты подбираются строго индивидуально и могут включать:
Получить дополнительные сведения – http://www.domen.ru
whoah this blog is magnificent i like reading your articles. Keep up the great work! You know, a lot of persons are hunting round for this information, you can aid them greatly.
Your blog doesn’t display appropriately on my iphone4 – you might wanna try and repair that
Таким образом, наш подход направлен на создание комплексной системы поддержки, которая помогает каждому пациенту справиться с зависимостью и вернуться к полноценной жизни.
Подробнее тут – вывод из запоя на дому круглосуточно
Наши врачи оперативно приезжают к пациенту, проводят осмотр, купируют симптомы абстиненции и приступают к восстановлению жизненно важных функций. Всё это — в привычной для пациента обстановке, без стресса и лишней огласки. Мы обеспечиваем не только медицинскую помощь, но и эмоциональную поддержку, создавая условия для начала пути к выздоровлению.
Разобраться лучше – narkolog na dom
Наши наркологи придерживаются принципов уважительного и чуткого отношения, что создаёт атмосферу доверия. Специалисты проводят детальную диагностику, выявляют причины зависимости и разрабатывают персональные стратегии лечения. Компетентность и профессионализм врачей — залог успешного восстановления пациентов.
Выяснить больше – [url=https://tajno-vyvod-iz-zapoya.ru/vyvod-iz-zapoya-na-domu-v-rostove-na-donu.ru/]вывод из запоя недорого ростов-на-дону[/url]
Миссия клиники — способствовать восстановлению здоровья и социальной адаптации людей, столкнувшихся с зависимостью. Мы подходим к проблеме комплексно, учитывая не только физические, но и психологические и социальные аспекты зависимости. Наша задача — не только помочь избавиться от пагубного влечения, но и обеспечить успешное возвращение пациентов к полноценной жизни в обществе.
Детальнее – narkolog-vyvod-iz-zapoya rostov-na-donu
Hello there! This is kind of off topic but I need some help from an established blog. Is it difficult to set up your own blog? I’m not very techincal but I can figure things out pretty fast. I’m thinking about creating my own but I’m not sure where to start. Do you have any ideas or suggestions? Appreciate it
После диагностики начинается активная фаза медикаментозного вмешательства. Современные препараты вводятся капельничным методом для быстрого снижения уровня токсинов в крови, восстановления обменных процессов и нормализации работы внутренних органов, таких как печень, почки и сердце.
Подробнее – после капельницы от запоя архангельск
I have seen that currently, more and more people are being attracted to camcorders and the area of picture taking. However, to be a photographer, you should first devote so much time frame deciding which model of dslr camera to buy along with moving out of store to store just so you could potentially buy the most economical camera of the brand you have decided to select. But it does not end generally there. You also have to contemplate whether you should purchase a digital digicam extended warranty. Thanks a lot for the good ideas I acquired from your blog.
Профессиональный вывод из запоя на дому в Луганске ЛНР организован по отлаженной схеме, которая включает несколько этапов, позволяющих обеспечить максимально безопасное и эффективное лечение.
Углубиться в тему – капельница от запоя на дому цена луганск
Самостоятельно выйти из запоя — почти невозможно. В Сочи врачи клиники проводят медикаментозный вывод из запоя с круглосуточным выездом. Доверяйте профессионалам.
Изучить вопрос глубже – вывод из запоя на дому
Запой — это не просто следствие чрезмерного употребления алкоголя, а серьёзное патологическое состояние, которое требует срочной медицинской помощи. На фоне затяжного приёма спиртного в организме человека происходят опасные изменения: интоксикация, обезвоживание, нарушение электролитного баланса, резкие скачки давления и работы сердца, угнетение функций печени и мозга. В такой ситуации капельница от запоя становится неотложной мерой, позволяющей стабилизировать состояние и устранить симптомы абстиненции за короткий срок.
Подробнее тут – вызвать капельницу от запоя одинцово
Лечебные мероприятия и рекомендации формируются исходя из индивидуального состояния каждого пациента. Специалист имеет возможность посвятить достаточное количество времени каждому больному, корректируя программу лечения согласно его особым потребностям и жизненным обстоятельствам. При этом учитываются психологические, социальные и физические аспекты, оказывающие влияние на здоровье пациента. Персонализированный подход обеспечивает оперативное реагирование на изменения состояния и своевременную корректировку терапии.
Получить дополнительную информацию – https://narcolog-na-dom-msk55.ru/
Ключевым направлением работы является индивидуальный подход к лечению. Мы понимаем уникальность каждого пациента и начинаем с тщательной диагностики, изучая медицинскую историю, психологические особенности и социальные факторы. На основе этих данных разрабатываются персонализированные планы лечения, включающие медикаментозную терапию, психотерапевтические программы и социальные инициативы.
Разобраться лучше – vyvod-iz-zapoya rostov-na-donu
Медикаментозное лечение: Мы применяем современные препараты, которые помогают облегчить симптомы абстиненции и улучшить состояние пациентов в первые дни лечения. Индивидуальный подбор лекарственных схем позволяет минимизировать побочные эффекты и достичь наилучших результатов.
Получить дополнительные сведения – нарколог вывод из запоя
I don’t think the title of your article matches the content lol. Just kidding, mainly because I had some doubts after reading the article.
На этом этапе специалист уточняет продолжительность запоя, тип употребляемого алкоголя и наличие сопутствующих заболеваний, что позволяет разработать персонализированный план терапии и оперативно выбрать методы детоксикации.
Узнать больше – http://kapelnica-ot-zapoya-arkhangelsk0.ru
Каждый день запоя увеличивает риск для жизни. Не рискуйте — специалисты в Сочи приедут на дом и окажут экстренную помощь. Без боли, стресса и ожидания.
Изучить вопрос глубже – нарколог вывод из запоя
При поступлении вызова нарколог незамедлительно приезжает на дом для проведения тщательного осмотра. Врач измеряет жизненно важные показатели, такие как пульс, артериальное давление и температура, а также собирает анамнез, чтобы определить степень алкогольной интоксикации.
Ознакомиться с деталями – капельница от запоя клиника в архангельске
congratulations balloons dubai deliver balloons dubai
resume backend engineer resume data engineer google
Перед началом процедуры врач проводит осмотр: измеряет давление, пульс, уровень кислорода в крови, оценивает тяжесть абстинентного синдрома. В зависимости от результатов и наличия сопутствующих заболеваний составляется индивидуальный состав инфузионного раствора. Он может включать:
Получить дополнительную информацию – kapelnitsa ot zapoia
Ритм жизни в мегаполисе и постоянный стресс часто становятся причиной развития зависимостей у жителей города. В такой ситуации необходима профессиональная консультация врача. Оптимальное решение – вызов нарколога на дом в Москве. Это обеспечивает не только получение медицинской помощи в привычной обстановке, но и полную конфиденциальность.
Ознакомиться с деталями – http://narcolog-na-dom-msk55.ru
Таким образом, наш подход направлен на создание комплексной системы поддержки, которая помогает каждому пациенту справиться с зависимостью и вернуться к полноценной жизни.
Детальнее – вывод из запоя цена казань
В динамичном мире Санкт-Петербурга, где каждый день кипит жизнь и совершаются тысячи сделок, актуальная и удобная доска объявлений становится незаменимым инструментом как для частных лиц, так и для предпринимателей. Наша платформа – это ваш надежный партнер в поиске и предложении товаров и услуг в Северной столице. Сайт бесплатных объявлений
Обращение за капельничной терапией от запоя в домашних условиях имеет множество преимуществ, среди которых:
Исследовать вопрос подробнее – kapelnica-ot-zapoya-lugansk-lnr0.ru/
Инфузия проводится под постоянным контролем медицинского персонала. Длительность процедуры составляет от одного до трёх часов. Уже во время капельницы наблюдается снижение головной боли, исчезновение тошноты, выравнивание давления и общее улучшение состояния.
Исследовать вопрос подробнее – vrach na dom kapelnitsa ot zapoia odintsovo
Услуга капельничного лечения от запоя на дому в Архангельске предусматривает комплексный подход, направленный на оперативное восстановление организма. Сразу после вызова нарколог прибывает на дом, проводит детальный осмотр, собирает анамнез и измеряет жизненно важные показатели. На основе этих данных разрабатывается персональный план терапии, который включает введение современных медикаментов с использованием автоматизированных систем дозирования, а также психологическую поддержку для создания условий долгосрочной ремиссии.
Получить дополнительную информацию – врач на дом капельница от запоя в архангельске
акк варфейс В мире онлайн-шутеров Warface занимает особое место, привлекая миллионы игроков своей динамикой, разнообразием режимов и возможностью совершенствования персонажа. Однако, не каждый готов потратить месяцы на прокачку аккаунта, чтобы получить желаемое оружие и экипировку. В этом случае, покупка аккаунта Warface становится привлекательным решением, открывающим двери к новым возможностям и впечатлениям.
Лечебные мероприятия и рекомендации формируются исходя из индивидуального состояния каждого пациента. Специалист имеет возможность посвятить достаточное количество времени каждому больному, корректируя программу лечения согласно его особым потребностям и жизненным обстоятельствам. При этом учитываются психологические, социальные и физические аспекты, оказывающие влияние на здоровье пациента. Персонализированный подход обеспечивает оперативное реагирование на изменения состояния и своевременную корректировку терапии.
Подробнее тут – narcolog-na-dom-msk55.ru/
Профессиональный вывод из запоя на дому в Луганске ЛНР организован по отлаженной схеме, которая включает несколько этапов, позволяющих обеспечить максимально безопасное и эффективное лечение.
Исследовать вопрос подробнее – врач на дом капельница от запоя луганск
На месте врач проводит первичный осмотр, измеряет давление, пульс, сатурацию, оценивает уровень интоксикации и абстиненции. Далее назначается инфузионная терапия — капельница, направленная на дезинтоксикацию, восстановление электролитного баланса, купирование тревожности и нормализацию сна.
Выяснить больше – врач нарколог на дом красногорск
Алкогольная интоксикация разрушает организм изнутри. В первую очередь страдает центральная нервная система: снижается уровень витаминов группы B, нарушаются когнитивные функции, появляются раздражительность, бессонница, панические атаки. Следом — страдает печень, главный орган метаболической детоксикации. Под действием этанола её функции подавляются, а токсины накапливаются в крови. Это вызывает системное отравление и разрушает внутренние органы.
Исследовать вопрос подробнее – [url=https://kapelnica-ot-zapoya-msk55.ru/]капельница от запоя[/url]
Отсутствие визитов в клинику гарантирует полную конфиденциальность. Это особенно важно для пациентов, беспокоящихся о своей репутации или возможном влиянии на профессиональную деятельность. Вызов врача на дом полностью исключает нежелательные встречи в медицинском центре.
Получить дополнительные сведения – нарколог на дом круглосуточно
Метод капельничного лечения от запоя обладает рядом существенных преимуществ, благодаря которым пациенты получают качественную и оперативную помощь:
Ознакомиться с деталями – kapelnica-ot-zapoya-arkhangelsk0.ru/
Дополнительно усиливаются сердечно-сосудистые риски: густая кровь, дефицит калия и магния провоцируют тахикардию, скачки давления и повышают вероятность инфаркта или инсульта. На этом фоне даже простая головная боль может оказаться сигналом серьёзного сосудистого нарушения. Задача капельницы — не просто убрать симптомы, а стабилизировать состояние организма и предотвратить дальнейшее ухудшение.
Подробнее тут – выезд на дом капельница от запоя
При поступлении вызова нарколог незамедлительно приезжает на дом для проведения тщательного осмотра. Врач измеряет жизненно важные показатели, такие как пульс, артериальное давление и температура, а также собирает анамнез, чтобы определить степень алкогольной интоксикации.
Получить дополнительную информацию – вызвать капельницу от запоя на дому в архангельске
Инфузия проводится под постоянным контролем медицинского персонала. Длительность процедуры составляет от одного до трёх часов. Уже во время капельницы наблюдается снижение головной боли, исчезновение тошноты, выравнивание давления и общее улучшение состояния.
Узнать больше – http://www.domen.ru
На этом этапе специалист уточняет продолжительность запоя, тип употребляемого алкоголя и наличие сопутствующих заболеваний, что позволяет разработать персонализированный план терапии и оперативно выбрать методы детоксикации.
Получить дополнительные сведения – после капельницы от запоя
Ритм жизни в мегаполисе и постоянный стресс часто становятся причиной развития зависимостей у жителей города. В такой ситуации необходима профессиональная консультация врача. Оптимальное решение – вызов нарколога на дом в Москве. Это обеспечивает не только получение медицинской помощи в привычной обстановке, но и полную конфиденциальность.
Изучить вопрос глубже – narkolog na dom anonimno
Перед началом процедуры врач проводит осмотр: измеряет давление, пульс, уровень кислорода в крови, оценивает тяжесть абстинентного синдрома. В зависимости от результатов и наличия сопутствующих заболеваний составляется индивидуальный состав инфузионного раствора. Он может включать:
Изучить вопрос глубже – vyezd na dom kapelnitsa ot zapoia
Миссия нашего центра – оказание всесторонней помощи людям с зависимостями. Основные цели нашей работы:
Получить дополнительную информацию – вывод из запоя на дому республика татарстан
Лечебные мероприятия и рекомендации формируются исходя из индивидуального состояния каждого пациента. Специалист имеет возможность посвятить достаточное количество времени каждому больному, корректируя программу лечения согласно его особым потребностям и жизненным обстоятельствам. При этом учитываются психологические, социальные и физические аспекты, оказывающие влияние на здоровье пациента. Персонализированный подход обеспечивает оперативное реагирование на изменения состояния и своевременную корректировку терапии.
Изучить вопрос глубже – вызвать нарколога на дом
Лечебные мероприятия и рекомендации формируются исходя из индивидуального состояния каждого пациента. Специалист имеет возможность посвятить достаточное количество времени каждому больному, корректируя программу лечения согласно его особым потребностям и жизненным обстоятельствам. При этом учитываются психологические, социальные и физические аспекты, оказывающие влияние на здоровье пациента. Персонализированный подход обеспечивает оперативное реагирование на изменения состояния и своевременную корректировку терапии.
Разобраться лучше – нарколог на дом недорого
Таким образом, наш подход направлен на создание комплексной системы поддержки, которая помогает каждому пациенту справиться с зависимостью и вернуться к полноценной жизни.
Исследовать вопрос подробнее – наркология вывод из запоя в казани
Наши врачи оперативно приезжают к пациенту, проводят осмотр, купируют симптомы абстиненции и приступают к восстановлению жизненно важных функций. Всё это — в привычной для пациента обстановке, без стресса и лишней огласки. Мы обеспечиваем не только медицинскую помощь, но и эмоциональную поддержку, создавая условия для начала пути к выздоровлению.
Получить дополнительную информацию – vyzov narkologa na dom krasnogorsk
Близкий человек в запое? Не ждите ухудшения. Обратитесь в клинику Сочи — здесь проведут профессиональный вывод из запоя с последующим восстановлением организма.
Подробнее тут – [url=https://vyvod-iz-zapoya-sochi17.ru/]vyvod-iz-zapoya[/url]
В Сочи решение есть — наркологическая клиника. Здесь помогают людям выйти из запоя без страха и осуждения. Всё анонимно, грамотно и с заботой о каждом пациенте.
Узнать больше – срочный вывод из запоя
Наркологическая клиника «Новый шанс» — это специализированное учреждение, которое предоставляет профессиональную помощь людям, страдающим от алкогольной и наркотической зависимости. Наша цель — предложить эффективные методы лечения и всестороннюю поддержку, чтобы помочь пациентам преодолеть зависимость и вернуть контроль над своей жизнью.
Получить больше информации – вывод из запоя недорого в ростове-на-дону
Перед началом процедуры врач проводит осмотр: измеряет давление, пульс, уровень кислорода в крови, оценивает тяжесть абстинентного синдрома. В зависимости от результатов и наличия сопутствующих заболеваний составляется индивидуальный состав инфузионного раствора. Он может включать:
Получить дополнительные сведения – vyezd na dom kapelnitsa ot zapoia
Препараты подбираются строго индивидуально и могут включать:
Детальнее – https://narcolog-na-dom-v-moskve55.ru/vyzov-narkologa-na-dom-v-krasnogorske/
При поступлении вызова нарколог незамедлительно приезжает на дом для проведения тщательного осмотра. Врач измеряет жизненно важные показатели, такие как пульс, артериальное давление и температура, а также собирает анамнез, чтобы определить степень алкогольной интоксикации.
Подробнее тут – http://kapelnica-ot-zapoya-arkhangelsk0.ru/kapelnicza-ot-zapoya-na-domu-arkhangelsk/https://kapelnica-ot-zapoya-arkhangelsk0.ru
Капельничное лечение от запоя – это современный метод детоксикации, который позволяет быстро и безопасно вывести токсины из организма. В Луганске ЛНР специалисты оказывают помощь на дому, предлагая профессиональное капельничное лечение для тех, кто столкнулся с тяжелой алкогольной интоксикацией. Такой подход обеспечивает оперативное вмешательство в привычной для пациента обстановке, гарантируя индивидуальный подход и полную конфиденциальность.
Разобраться лучше – капельница от запоя
Профессиональный вывод из запоя на дому в Луганске ЛНР организован по отлаженной схеме, которая включает несколько этапов, позволяющих обеспечить максимально безопасное и эффективное лечение.
Исследовать вопрос подробнее – капельница от запоя наркология
Проведение лечения в домашней обстановке значительно снижает уровень стресса и тревожности. Пациенту не нужно тратить силы на поездки в медицинские учреждения, что особенно важно при ограниченной мобильности. Домашняя атмосфера создает идеальные условия для открытого диалога с врачом, что существенно повышает эффективность терапии и шансы на успешное выздоровление.
Углубиться в тему – https://narcolog-na-dom-msk55.ru/
Команда клиники «Новый шанс» состоит из опытных специалистов-наркологов, которые имеют многолетнюю практику работы с пациентами, находящимися в зависимости, и регулярно совершенствуют свои знания.
Получить дополнительные сведения – вывод из запоя на дому
Образовательные программы: Мы уверены, что знания о зависимости и её последствиях играют важную роль в реабилитации. Мы информируем пациентов о механизмах действия наркотиков и алкоголя на организм, что способствует изменению их отношения к терапии и жизни без зависимостей.
Подробнее можно узнать тут – вывод из запоя в стационаре
В Сочи решение есть — наркологическая клиника. Здесь помогают людям выйти из запоя без страха и осуждения. Всё анонимно, грамотно и с заботой о каждом пациенте.
Углубиться в тему – вывод из запоя на дому круглосуточно
музыкальные новинки Роп – Русский роп – это больше, чем просто музыка. Это зеркало современной российской души, отражающее её надежды, страхи и мечты. В 2025 году жанр переживает новый виток развития, впитывая в себя элементы других стилей и направлений, становясь всё более разнообразным и эклектичным. Популярная музыка сейчас – это калейдоскоп звуков и образов. Хиты месяца мгновенно взлетают на вершины чартов, но так же быстро и забываются, уступая место новым музыкальным новинкам. 2025 год дарит нам множество талантливых российских исполнителей, каждый из которых вносит свой неповторимый вклад в развитие жанра.
Капельница от запоя необходима, если у пациента наблюдаются следующие симптомы:
Углубиться в тему – kapelnitsa ot zapoia
Миссия нашего центра – оказание всесторонней помощи людям с зависимостями. Основные цели нашей работы:
Изучить вопрос глубже – srochnyj-vyvod-iz-zapoya.ru/
Кроме того, клиника «Новый шанс» уделяет особое внимание профилактике рецидивов. Мы обучаем пациентов навыкам управления стрессом, эмоциональной регуляции и прививаем навыки здорового образа жизни. Наша цель — обеспечить долгосрочное восстановление и снизить риск возврата к зависимости.
Получить дополнительную информацию – наркологический вывод из запоя ростов-на-дону
A person essentially help to make seriously posts I’d state. That is the very first time I frequented your web page and to this point? I surprised with the research you made to make this particular post extraordinary. Great job!
obviously like your website but you need to check the spelling on quite a few of your posts. Many of them are rife with spelling issues and I find it very bothersome to tell the truth nevertheless I?ll certainly come back again.
Метод капельничного лечения от запоя обладает рядом существенных преимуществ, благодаря которым пациенты получают качественную и оперативную помощь:
Подробнее – http://www.domen.ru
Затяжной запой опасен для жизни. Врачи наркологической клиники в Сочи проводят срочный вывод из запоя — на дому или в стационаре. Анонимно, безопасно, круглосуточно.
Исследовать вопрос подробнее – вывод из запоя круглосуточно
Наши врачи оперативно приезжают к пациенту, проводят осмотр, купируют симптомы абстиненции и приступают к восстановлению жизненно важных функций. Всё это — в привычной для пациента обстановке, без стресса и лишней огласки. Мы обеспечиваем не только медицинскую помощь, но и эмоциональную поддержку, создавая условия для начала пути к выздоровлению.
Разобраться лучше – https://narcolog-na-dom-v-moskve55.ru/narkolog-na-dom-anonimno-v-krasnogorske
Наркологическая клиника «Новый шанс» — это специализированное учреждение, которое предоставляет профессиональную помощь людям, страдающим от алкогольной и наркотической зависимости. Наша цель — предложить эффективные методы лечения и всестороннюю поддержку, чтобы помочь пациентам преодолеть зависимость и вернуть контроль над своей жизнью.
Углубиться в тему – [url=https://tajno-vyvod-iz-zapoya.ru/vyvod-iz-zapoya-na-domu-v-rostove-na-donu.ru/]вывод из запоя капельница[/url]
температура воды в хургаде в апреле
Данный комплекс мер обеспечивает восстановление здоровья пациента и создает основу для полного выздоровления.
Выяснить больше – narkolog na dom moskva
Команда клиники «Новый шанс» состоит из опытных специалистов-наркологов, которые имеют многолетнюю практику работы с пациентами, находящимися в зависимости, и регулярно совершенствуют свои знания.
Изучить вопрос глубже – вывод из запоя анонимно
Когда организм на пределе, важна срочная помощь в Сочи — это команда опытных наркологов, которые помогут быстро и мягко выйти из запоя без вреда для здоровья.
Углубиться в тему – вывод из запоя на дому цена
Психологическая реабилитация: Психологическая поддержка – один из главных аспектов нашего подхода. Мы предлагаем индивидуальные и групповые занятия, помогающие осознать зависимость, проработать эмоциональные травмы и сформировать новые модели поведения. Опытные психологи помогают пациентам понять причины своих зависимостей, что является важным шагом на пути к выздоровлению.
Получить дополнительные сведения – наркология вывод из запоя
Вызов нарколога на дом в таких условиях позволяет не терять драгоценное время, избежать госпитализации и предотвратить критическое развитие событий. Кроме того, это снижает психологическую нагрузку на пациента и его близких, особенно если зависимость длится долго и сопровождается отрицанием проблемы.
Изучить вопрос глубже – вызвать нарколога на дом красногорск
Миссия нашего центра – оказание всесторонней помощи людям с зависимостями. Основные цели нашей работы:
Разобраться лучше – [url=https://srochnyj-vyvod-iz-zapoya.ru/vyvod-iz-zapoya-v-kruglosutochno-v-kazani.ru/]www.domen.ru[/url]
Команда клиники «Новый шанс» состоит из опытных специалистов-наркологов, которые имеют многолетнюю практику работы с пациентами, находящимися в зависимости, и регулярно совершенствуют свои знания.
Подробнее – вывод из запоя на дому круглосуточно
Образовательные программы: Мы уверены, что знания о зависимости и её последствиях играют важную роль в реабилитации. Мы информируем пациентов о механизмах действия наркотиков и алкоголя на организм, что способствует изменению их отношения к терапии и жизни без зависимостей.
Исследовать вопрос подробнее – вывод из запоя капельница в казани
Наркологическая клиника «Новый шанс» — это специализированное учреждение, которое предоставляет профессиональную помощь людям, страдающим от алкогольной и наркотической зависимости. Наша цель — предложить эффективные методы лечения и всестороннюю поддержку, чтобы помочь пациентам преодолеть зависимость и вернуть контроль над своей жизнью.
Изучить вопрос глубже – вывод из запоя ростовская область
В современном обществе проблемы наркомании и алкоголизма приобрели особую актуальность, затрагивая не только отдельных людей, но и их близких, и сообщества. Эти зависимости оказывают негативное влияние не только на физическое здоровье, но и на психоэмоциональное состояние, нарушают социальные связи и ухудшают качество жизни. Наркологическая клиника “Здоровое Настоящее” предлагает комплексный и научно обоснованный подход к лечению зависимостей. Мы используем современные методы диагностики и терапии, чтобы помочь пациентам вернуть здоровье и полноценную жизнь.
Подробнее тут – вывод из запоя казань.
В наркологической клинике «Прозрение» в Одинцово процедура проводится с соблюдением всех стандартов безопасности, под контролем опытных врачей. Мы применяем комплексный подход, направленный не только на детоксикацию, но и на поддержку всех систем организма. Уже после одного сеанса пациенты отмечают улучшение самочувствия, снижение тревожности, исчезновение головной боли и тошноты.
Углубиться в тему – поставить капельницу от запоя
Образовательные программы: Мы уверены, что знания о зависимости и её последствиях играют важную роль в реабилитации. Мы информируем пациентов о механизмах действия наркотиков и алкоголя на организм, что способствует изменению их отношения к терапии и жизни без зависимостей.
Узнать больше – вывод из запоя анонимно
В современном обществе проблемы наркомании и алкоголизма приобрели особую актуальность, затрагивая не только отдельных людей, но и их близких, и сообщества. Эти зависимости оказывают негативное влияние не только на физическое здоровье, но и на психоэмоциональное состояние, нарушают социальные связи и ухудшают качество жизни. Наркологическая клиника “Здоровое Настоящее” предлагает комплексный и научно обоснованный подход к лечению зависимостей. Мы используем современные методы диагностики и терапии, чтобы помочь пациентам вернуть здоровье и полноценную жизнь.
Детальнее – наркологический вывод из запоя
Каждый день запоя увеличивает риск для жизни. Не рискуйте — специалисты в Сочи приедут на дом и окажут экстренную помощь. Без боли, стресса и ожидания.
Получить дополнительную информацию – вывод из запоя на дому
Миссия нашего центра – оказание всесторонней помощи людям с зависимостями. Основные цели нашей работы:
Изучить вопрос глубже – вывод из запоя на дому круглосуточно казань
На этом этапе специалист уточняет продолжительность запоя, тип употребляемого алкоголя и наличие сопутствующих заболеваний, что позволяет разработать персонализированный план терапии и оперативно выбрать методы детоксикации.
Ознакомиться с деталями – https://kapelnica-ot-zapoya-arkhangelsk0.ru/
I do agree with all of the ideas you have presented in your post. They are very convincing and will definitely work. Still, the posts are too short for starters. Could you please extend them a little from next time? Thanks for the post.
Pretty section of content. I just stumbled upon your website and in accession capital to assert that I acquire actually enjoyed account your blog posts. Anyway I?ll be subscribing to your feeds and even I achievement you access consistently fast.
Услуги массажа Ивантеевка — здоровье, отдых и красота. Лечебный, баночный, лимфодренажный, расслабляющий и косметический массаж. Сертифицированнй мастер, удобное расположение, результат с первого раза.
Этот увлекательный информационный материал подарит вам массу новых знаний и ярких эмоций. Мы собрали для вас интересные факты и сведения, которые обогатят ваш опыт. Откройте для себя увлекательный мир информации и насладитесь процессом изучения!
Получить больше информации – https://cryptomarketbee.com/2023/08/21/connecting-with-natures-tranquil-essence
В данной обзорной статье представлены интригующие факты, которые не оставят вас равнодушными. Мы критикуем и анализируем события, которые изменили наше восприятие мира. Узнайте, что стоит за новыми открытиями и как они могут изменить ваше восприятие реальности.
Разобраться лучше – https://yxz.pl/2023/02/06/dzisiaj-zalatwilem-sprawy
Эта публикация погружает вас в мир увлекательных фактов и удивительных открытий. Мы расскажем о ключевых событиях, которые изменили ход истории, и приоткроем завесу над научными достижениями, которые вдохновили миллионы. Узнайте, чему может научить нас прошлое и как применить эти знания в будущем.
Исследовать вопрос подробнее – https://nutritionnode.com/quest-vanilla-latte-popsicles-quest-blog
Эта познавательная публикация погружает вас в море интересного контента, который быстро захватит ваше внимание. Мы рассмотрим важные аспекты темы и предоставим вам уникальныеInsights и полезные сведения для дальнейшего изучения.
Подробнее – https://doktorpendidikan.fkip.unib.ac.id/melakukan-audiensi-dengan-atdikbud-kedutaan-indonesia-di-kuala-lumpur-untuk-dukungan-kerjasama-penelitian-dan-pengabdian
В этом информативном обзоре собраны самые интересные статистические данные и факты, которые помогут лучше понять текущие тренды. Мы представим вам цифры и графики, которые иллюстрируют, как развиваются различные сферы жизни. Эта информация станет отличной основой для глубокого анализа и принятия обоснованных решений.
Выяснить больше – https://truenet.com.br/2024/10/23/mae-dela-mavi-e-luma-descobrem-quem-mercia-e-na-verdade-em-mania-de-voce-e-se-unem
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Углубиться в тему – http://consulam.com/2024/07/23/pacanele-egt-jocuri-online-gratuit-demo
Когда состояние алкогольной интоксикации достигает критических уровней, своевременное вмешательство становится жизненно необходимым. В Мариуполе, Донецкая область, высококвалифицированные наркологи оказывают срочную помощь на дому, позволяя оперативно начать детоксикацию и стабилизировать состояние пациента. Такой формат лечения обеспечивает быстрый выход из кризиса в условиях комфорта и конфиденциальности, что особенно важно для тех, кто не может позволить себе задержки в стационарном лечении.
Выяснить больше – https://narcolog-na-dom-mariupol00.ru/narkolog-na-dom-kruglosutochno-mariupol/
Под контролем специалистов проводится выведение токсинов из организма. Используются капельницы с растворами, препараты для поддержки сердца, печени и снятия психоэмоционального напряжения. Лечение алкоголизма в Воронеже — помощь на всех стадиях зависимости предполагает безопасный и контролируемый процесс детоксикации с минимизацией рисков осложнений.
Разобраться лучше – анонимное лечение алкоголизма в воронеже
Your article helped me a lot, is there any more related content? Thanks!
Незамедлительно после вызова нарколог прибывает на дом для проведения первичного осмотра. Специалист измеряет жизненно важные показатели, такие как пульс, артериальное давление и температура, а также собирает анамнез, чтобы определить степень алкогольной интоксикации. Эта информация позволяет оперативно разработать персонализированный план лечения.
Ознакомиться с деталями – врач нарколог на дом в мариуполе
Таким образом, наш подход направлен на создание комплексной системы поддержки, которая помогает каждому пациенту справиться с зависимостью и вернуться к полноценной жизни.
Подробнее тут – вывод из запоя капельница казань
Наши наркологи придерживаются принципов уважительного и чуткого отношения, что создаёт атмосферу доверия. Специалисты проводят детальную диагностику, выявляют причины зависимости и разрабатывают персональные стратегии лечения. Компетентность и профессионализм врачей — залог успешного восстановления пациентов.
Подробнее можно узнать тут – вывод из запоя в ростове-на-дону
Процесс оказания срочной помощи нарколога на дому в Мариуполе построен по отлаженной схеме, которая включает несколько ключевых этапов, направленных на быстрое и безопасное восстановление здоровья пациента.
Изучить вопрос глубже – нарколог на дом срочно в мариуполе
Алкогольная зависимость — это хроническое заболевание, при котором устойчивое влечение к спиртному приводит к тяжёлым медицинским, социальным и психологическим последствиям. Когда пациент осознаёт, что самостоятельно справиться с этой проблемой не получается, наиболее эффективным методом становится кодирование от алкоголизма. В клинике «Ясное Будущее» в Одинцово мы используем сочетание проверенных методик кодирования и комплексной психологической поддержки, что позволяет достичь стойкой ремиссии и вернуть человеку контроль над собственной жизнью.
Углубиться в тему – кодирование от алкоголизма гипнозом
«Рентвил» предлагает аренду автомобилей в Краснодаре без залога и ограничений по пробегу по Краснодарскому краю и Адыгее. Требуется стаж от 3 лет и возраст от 23 лет. Оформление за 5 минут онлайн: нужны только фото паспорта и прав. Подача авто на жд вокзал и аэропорт Краснодар Мин-воды Сочи . Компания работает 10 лет , автомобили проходят своевременное ТО. Доступны детские кресла. Бронируйте через машина в аренду краснодар
As I website possessor I believe the content matter here is rattling great , appreciate it for your efforts. You should keep it up forever! Best of luck.
I believe that avoiding highly processed foods is a first step so that you can lose weight. They will often taste very good, but highly processed foods contain very little nutritional value, making you eat more simply to have enough energy to get over the day. If you are constantly having these foods, transitioning to grain and other complex carbohydrates will assist you to have more electricity while feeding on less. Great blog post.
Ниже приведены ключевые сигналы, при появлении которых требуется немедленное реагирование:
Изучить вопрос глубже – https://vyvod-iz-zapoya-krasnogorsk2.ru/vyvod-iz-zapoya-anonimno/
Показанием к стационарному лечению служат случаи, при которых домашняя терапия становится небезопасной или недостаточно эффективной. Рекомендуем госпитализацию при:
Получить больше информации – наркологическая клиника в уфе
Незамедлительно после вызова нарколог прибывает на дом для проведения первичного осмотра. Специалист измеряет жизненно важные показатели, такие как пульс, артериальное давление и температура, а также собирает анамнез, чтобы определить степень алкогольной интоксикации. Эта информация позволяет оперативно разработать персонализированный план лечения.
Получить дополнительную информацию – нарколог на дом вывод
Услуга “Нарколог на дом” в Мариуполе, Донецкая область, предусматривает оперативное оказание медицинской помощи при запое. После получения вызова специалист незамедлительно выезжает к пациенту, проводит детальный осмотр, измеряет жизненно важные показатели и собирает анамнез. На основе полученных данных разрабатывается индивидуальный план терапии, включающий медикаментозную детоксикацию, инфузионную терапию и психологическую поддержку. Такой комплексный подход позволяет эффективно вывести токсины из организма и предотвратить развитие осложнений.
Подробнее – вызов врача нарколога на дом в мариуполе
roobet promotional code WEB3 В мире онлайн-казино инновации не стоят на месте, и Roobet находится в авангарде этих перемен. С появлением технологии Web3, Roobet предлагает игрокам новый уровень прозрачности, безопасности и децентрализации. Чтобы воспользоваться всеми преимуществами этой передовой платформы, используйте промокод WEB3.
Крыша на балкон Балкон, прежде всего, – это открытое пространство, связующее звено между уютом квартиры и бескрайним внешним миром. Однако его беззащитность перед капризами погоды порой превращает это преимущество в существенный недостаток. Дождь, снег, палящее солнце – все это способно причинить немало хлопот, лишая возможности комфортно проводить время на балконе, а также нанося ущерб отделке и мебели. Именно здесь на помощь приходит крыша на балкон – надежная защита и гарантия комфорта в любое время года.
В нашей клинике применяются различные техники кодирования, которые подбираются с учётом медицинских показаний, психологического состояния и пожеланий пациента.
Получить дополнительные сведения – http://kodirovanie-ot-alkogolizma-odintsovo2.ru
Rainbet referral code ILBET В мире онлайн-гемблинга Rainbet сияет как яркая звезда, привлекая игроков своими щедрыми предложениями и захватывающими играми. Промокод ILBET – это ваш билет в этот мир возможностей, предоставляющий доступ к эксклюзивным бонусам и акциям, разработанным для повышения вашего игрового опыта и увеличения шансов на победу.
Незамедлительно после вызова нарколог прибывает на дом для проведения первичного осмотра. Специалист измеряет жизненно важные показатели, такие как пульс, артериальное давление и температура, а также собирает анамнез, чтобы определить степень алкогольной интоксикации. Эта информация позволяет оперативно разработать персонализированный план лечения.
Подробнее можно узнать тут – нарколог на дом клиника
Незамедлительно после вызова нарколог прибывает на дом для проведения первичного осмотра. Специалист измеряет жизненно важные показатели, такие как пульс, артериальное давление и температура, а также собирает анамнез, чтобы определить степень алкогольной интоксикации. Эта информация позволяет оперативно разработать персонализированный план лечения.
Подробнее тут – нарколог на дом недорого в мариуполе
chicken road login app Chicken Road: Взлеты и Падения на Пути к Успеху Chicken Road – это не просто развлечение, это обширный мир возможностей и тактики, где каждое решение может привести к невероятному взлету или полному краху. Игра, доступная как в сети, так и в виде приложения для мобильных устройств (Chicken Road apk), предлагает пользователям проверить свою фортуну и чутье на виртуальной “куриной тропе”. Суть Chicken Road заключается в преодолении сложного маршрута, полного ловушек и опасностей. С каждым успешно пройденным уровнем, награда растет, но и увеличивается шанс неудачи. Игроки могут загрузить Chicken Road game demo, чтобы оценить механику и особенности геймплея, прежде чем рисковать реальными деньгами.
Когда состояние алкогольной интоксикации достигает критических уровней, своевременное вмешательство становится жизненно необходимым. В Мариуполе, Донецкая область, высококвалифицированные наркологи оказывают срочную помощь на дому, позволяя оперативно начать детоксикацию и стабилизировать состояние пациента. Такой формат лечения обеспечивает быстрый выход из кризиса в условиях комфорта и конфиденциальности, что особенно важно для тех, кто не может позволить себе задержки в стационарном лечении.
Углубиться в тему – нарколог на дом мариуполь
Generate custom ai hentai maker. Create anime-style characters, scenes, and fantasy visuals instantly using an advanced hentai generator online.
Под контролем специалистов проводится выведение токсинов из организма. Используются капельницы с растворами, препараты для поддержки сердца, печени и снятия психоэмоционального напряжения. Лечение алкоголизма в Воронеже — помощь на всех стадиях зависимости предполагает безопасный и контролируемый процесс детоксикации с минимизацией рисков осложнений.
Получить дополнительные сведения – клиника лечения алкоголизма воронеж
Алкогольная зависимость разрушает здоровье, семью, карьеру и личность. Чем раньше будет оказана профессиональная помощь, тем выше шансы на восстановление и возвращение к полноценной жизни. Лечение алкоголизма в Воронеже — помощь на всех стадиях зависимости позволяет справляться не только с физической тягой, но и с глубинными причинами, которые провоцируют патологическое употребление.
Детальнее – http://lechenie-alkogolizma-voronezh9.ru/
После снятия острых симптомов пациент продолжает получать медикаментозную поддержку. Назначаются витамины, гепатопротекторы, успокоительные препараты. Проводится психологическая диагностика для подготовки к следующему этапу — реабилитации.
Подробнее тут – http://lechenie-alkogolizma-voronezh9.ru
В клинике «Горизонт Жизни» в Красногорске разработаны протоколы экстренного вывода из запоя, которые выполняются 24 часа в сутки, семь дней в неделю. Благодаря выезду бригады врачей-наркологов и оснащённости современным оборудованием мы оказываем помощь в кратчайшие сроки, обеспечивая максимальную безопасность и комфорт пациенту.
Выяснить больше – http://vyvod-iz-zapoya-krasnogorsk2.ru/
Аппаратные методы кодирования включают лазерную терапию и электростимуляцию биологически активных точек, влияющих на центры зависимости в головном мозге. Эти методики способствуют быстрому формированию устойчивого отвращения к спиртному и хорошо переносятся пациентами.
Подробнее тут – https://kodirovanie-ot-alkogolizma-odintsovo2.ru/kodirovanie-ot-alkogolizma-cena
На этом этапе проводится полное обследование: анализы, ЭКГ, оценка состояния печени, сердца и нервной системы. Врач-нарколог формирует индивидуальный план терапии с учётом стажа употребления и общего состояния пациента.
Углубиться в тему – центр лечения алкоголизма воронежская область
Клиническая практика показывает: только системная работа с пациентом даёт устойчивый результат. Программа включает медицинское, психологическое и социальное сопровождение.
Получить дополнительные сведения – анонимное лечение алкоголизма
Аппаратные методы кодирования включают лазерную терапию и электростимуляцию биологически активных точек, влияющих на центры зависимости в головном мозге. Эти методики способствуют быстрому формированию устойчивого отвращения к спиртному и хорошо переносятся пациентами.
Ознакомиться с деталями – http://kodirovanie-ot-alkogolizma-odintsovo2.ru/kodirovanie-ot-alkogolizma-na-domu/
Когда состояние алкогольной интоксикации достигает критических уровней, своевременное вмешательство становится жизненно необходимым. В Мариуполе, Донецкая область, высококвалифицированные наркологи оказывают срочную помощь на дому, позволяя оперативно начать детоксикацию и стабилизировать состояние пациента. Такой формат лечения обеспечивает быстрый выход из кризиса в условиях комфорта и конфиденциальности, что особенно важно для тех, кто не может позволить себе задержки в стационарном лечении.
Узнать больше – https://narcolog-na-dom-mariupol00.ru/
Клиника «Возрождение» гарантирует:
Получить дополнительную информацию – https://narkologicheskaya-klinika-ufa9.ru/narkologicheskie-kliniki-alkogolizm-ufa/
Всё о городе городской портал города Ханты-Мансийск: свежие новости, события, справочник, расписания, культура, спорт, вакансии и объявления на одном городском портале.
«Кодирование — это не магическое решение, а важный этап в комплексной программе лечения, — поясняет ведущий нарколог клиники «Ясное Будущее» Марина Иванова. — Главное — сочетание фармакологического воздействия и последующей работы с психологом для формирования устойчивой мотивации к трезвости».
Подробнее можно узнать тут – kodirovanie-ot-alkogolizma-odintsovo2.ru/
Кодирование создаёт стойкое отвращение к этилированному спирту за счёт фармакологического или психотерапевтического воздействия, а дальнейшая работа с психологом помогает сформировать новую модель поведения и мотивацию к сохранению трезвости. Современные технологии в сочетании с индивидуальным подходом делают процедуру безопасной и максимально комфортной для пациента.
Получить дополнительную информацию – kodirovanie ot alkogolizma odincovo
Команда клиники «Новый шанс» состоит из опытных специалистов-наркологов, которые имеют многолетнюю практику работы с пациентами, находящимися в зависимости, и регулярно совершенствуют свои знания.
Детальнее – вывод из запоя клиника в ростове-на-дону
После первичной диагностики начинается активная фаза медикаментозного вмешательства. Препараты вводятся капельничным методом для быстрого снижения уровня токсинов в крови, нормализации обменных процессов и стабилизации работы внутренних органов, таких как печень, почки и сердце.
Изучить вопрос глубже – http://narcolog-na-dom-mariupol00.ru/
Незамедлительно после вызова нарколог прибывает на дом для проведения первичного осмотра. Специалист измеряет жизненно важные показатели, такие как пульс, артериальное давление и температура, а также собирает анамнез, чтобы определить степень алкогольной интоксикации. Эта информация позволяет оперативно разработать персонализированный план лечения.
Подробнее можно узнать тут – vrach-narkolog-na-dom mariupol’
Медикаментозное кодирование проводится с помощью препаратов, блокирующих ферменты, ответственные за расщепление этанола, что вызывает выраженное неприятие алкоголя при попытке его употребления. Препараты вводятся внутримышечно или с помощью подкожных имплантов и действуют в течение нескольких месяцев, обеспечивая длительный эффект.
Подробнее тут – https://kodirovanie-ot-alkogolizma-odintsovo2.ru/
В этом информативном обзоре собраны самые интересные статистические данные и факты, которые помогут лучше понять текущие тренды. Мы представим вам цифры и графики, которые иллюстрируют, как развиваются различные сферы жизни. Эта информация станет отличной основой для глубокого анализа и принятия обоснованных решений.
Подробнее можно узнать тут – https://thescinewsreporter.com/the-best-anti-dandruff-shampoo-for-oily-hair
В этой информационной статье вы найдете интересное содержание, которое поможет вам расширить свои знания. Мы предлагаем увлекательный подход и уникальные взгляды на обсуждаемые темы, побуждая пользователей к активному мышлению и критическому анализу!
Получить дополнительную информацию – https://jyan.fr/bonjour-tout-le-monde
Эта статья предлагает уникальную подборку занимательных фактов и необычных историй, которые вы, возможно, не знали. Мы постараемся вдохновить ваше воображение и разнообразить ваш кругозор, погружая вас в мир, полный интересных открытий. Читайте и открывайте для себя новое!
Выяснить больше – https://scenterprisesgroup.com/this-is-the-way-you-sort-out-your-cracked-top-get-together-dating-sites
В этом интересном тексте собраны обширные сведения, которые помогут вам понять различные аспекты обсуждаемой темы. Мы разбираем детали и факты, делая акцент на важности каждого элемента. Не упустите возможность расширить свои знания и взглянуть на мир по-новому!
Разобраться лучше – https://visionuttarakhand.com/after-the-brahmkamal-cap-the-pahari-gamcha-will-also-become-the-identity-of-the-state
Эта публикация погружает вас в мир увлекательных фактов и удивительных открытий. Мы расскажем о ключевых событиях, которые изменили ход истории, и приоткроем завесу над научными достижениями, которые вдохновили миллионы. Узнайте, чему может научить нас прошлое и как применить эти знания в будущем.
Подробнее – https://barizaoman.com/experience-review-crowne-plaza-muscat
Эта познавательная публикация погружает вас в море интересного контента, который быстро захватит ваше внимание. Мы рассмотрим важные аспекты темы и предоставим вам уникальныеInsights и полезные сведения для дальнейшего изучения.
Узнать больше – http://mary-classy.ru/product-category/ukhod-za-litsom/sistemy-po-ukhodu-za-litsom/timewise-25
В данной обзорной статье представлены интригующие факты, которые не оставят вас равнодушными. Мы критикуем и анализируем события, которые изменили наше восприятие мира. Узнайте, что стоит за новыми открытиями и как они могут изменить ваше восприятие реальности.
Исследовать вопрос подробнее – https://press.et/oromifa/2020/02/29/ispoortiin-kubbaa-kachoo-yaaddoo-keessa-jira
Выезд врача-нарколога из клиники «ТрезвоПрофи» на дом происходит в любое время суток, включая выходные и праздники. Перед началом детоксикации врач проводит осмотр, измеряет давление, частоту пульса, уровень кислорода в крови и подбирает индивидуальную схему лечения. Сама процедура обычно занимает от 1 до 2 часов и проводится под строгим контролем врача.
Получить дополнительные сведения – капельница от запоя наркология в сочи
pin-co casino Pinco, Pinco AZ, Pinco Casino, Pinco Kazino, Pinco Casino AZ, Pinco Casino Azerbaijan, Pinco Azerbaycan, Pinco Gazino Casino, Pinco Pinco Promo Code, Pinco Cazino, Pinco Bet, Pinco Yukl?, Pinco Az?rbaycan, Pinco Casino Giris, Pinco Yukle, Pinco Giris, Pinco APK, Pin Co, Pin Co Casino, Pin-Co Casino. Онлайн-платформа Pinco, включая варианты Pinco AZ, Pinco Casino и Pinco Kazino, предлагает азартные игры в Азербайджане, также известная как Pinco Azerbaycan и Pinco Gazino Casino. Pinco предоставляет промокоды, а также варианты, такие как Pinco Cazino и Pinco Bet. Пользователи могут загрузить приложение Pinco (Pinco Yukl?, Pinco Yukle) для доступа к Pinco Az?rbaycan и Pinco Casino Giris. Pinco Giris доступен через Pinco APK. Pin Co и Pin-Co Casino — это связанные термины.
Профессиональный вывод из запоя – это комплексная медицинская услуга, направленная на безопасное и оперативное лечение пациентов, столкнувшихся с алкогольной интоксикацией. В Донецке ДНР высококвалифицированные наркологи оказывают помощь на дому, что позволяет начать детоксикацию организма в комфортной и привычной обстановке. Такой подход обеспечивает индивидуальную терапию, всестороннюю поддержку и полную конфиденциальность, что особенно важно для тех, кто предпочитает получать лечение вне стационаров.
Исследовать вопрос подробнее – вывод из запоя анонимно донецк
Greetings from Los angeles! I’m bored to tears at work so I decided to check out your website on my iphone during lunch break. I love the info you provide here and can’t wait to take a look when I get home. I’m surprised at how fast your blog loaded on my phone .. I’m not even using WIFI, just 3G .. Anyhow, excellent blog!
I don’t think the title of your article matches the content lol. Just kidding, mainly because I had some doubts after reading the article.
What?s Happening i’m new to this, I stumbled upon this I have found It positively helpful and it has helped me out loads. I hope to contribute & assist other users like its aided me. Good job.
«НОВЫЙ НАРКОЛОГ» — наркологическая клиника в СПб с полным спектром услуг: детоксикация, лечение зависимостей, реабилитация, психологическая поддержка. Доверие пациентов и высокая эффективность подтверждаются отзывами и результатами работы.
Изучить вопрос глубже – https://new-narkolog.ru/stati/alkogolnyy-tremor/
Бизнес-стратегия Разработка стратегии: создайте уникальный путь к успеху. Без четкой стратегии ваш бизнес рискует потеряться в конкурентной среде. Подлинный успех достигается благодаря хорошо продуманной и гибкой стратегии, учитывающей все риски и возможности. Ментор поможет вам определить сильные стороны, сформулировать уникальное предложение и разработать план действий. Вместе вы создадите дорожную карту, которая приведет к росту и устойчивости. Не позволяйте неопределенности тормозить развитие — инвестируйте в профессиональную поддержку и создайте эффективную стратегию. Закажите консультацию, начните свой путь к успеху.
Мир полон тайн https://phenoma.ru читайте статьи о малоизученных феноменах, которые ставят науку в тупик. Аномальные явления, редкие болезни, загадки космоса и сознания. Доступно, интересно, с научным подходом.
engineer resumes resume design engineer
Читайте о необычном http://phenoma.ru научно-популярные статьи о феноменах, которые до сих пор не имеют однозначных объяснений. Психология, физика, биология, космос — самые интересные загадки в одном разделе.
Запой представляет собой непрерывное бесконтрольное употребление алкоголя в течение нескольких дней и более, при котором человек теряет способность остановиться самостоятельно. Это состояние сопровождается не только абстинентным синдромом, но и риском развития:
Разобраться лучше – вывод из запоя на дому круглосуточно в санкт-петербруге
«Стоп Алко» — экстренная помощь при передозировке и отравлении. Устраняем последствия интоксикации, восстанавливаем жизненные функции, обеспечиваем медицинское сопровождение. Оперативно, анонимно, с заботой о вашем здоровье.
Исследовать вопрос подробнее – похмельный синдром лечение
Алкогольная зависимость — это хроническое заболевание, при котором устойчивое влечение к спиртному приводит к тяжёлым медицинским, социальным и психологическим последствиям. Когда пациент осознаёт, что самостоятельно справиться с этой проблемой не получается, наиболее эффективным методом становится кодирование от алкоголизма. В клинике «Ясное Будущее» в Одинцово мы используем сочетание проверенных методик кодирования и комплексной психологической поддержки, что позволяет достичь стойкой ремиссии и вернуть человеку контроль над собственной жизнью.
Выяснить больше – http://kodirovanie-ot-alkogolizma-odintsovo2.ru/
В условиях Донецка ДНР наши специалисты применяют современную методику вывода из запоя на дому, которая включает в себя несколько последовательных этапов для обеспечения максимально безопасного и эффективного лечения.
Изучить вопрос глубже – наркология вывод из запоя в донецке
Алкогольный запой — это острое состояние тяжёлой интоксикации, при котором организм накапливает критические уровни продуктов распада этанола и перестаёт справляться с их нейтрализацией. При этом страдают важнейшие органы и системы: печень, почки, сердце, центральная нервная система. Без квалифицированной медицинской помощи риск развития судорог, алкогольного делирия и полиорганной недостаточности возрастает многократно.
Получить дополнительные сведения – http://
Медикаментозное кодирование проводится с помощью препаратов, блокирующих ферменты, ответственные за расщепление этанола, что вызывает выраженное неприятие алкоголя при попытке его употребления. Препараты вводятся внутримышечно или с помощью подкожных имплантов и действуют в течение нескольких месяцев, обеспечивая длительный эффект.
Разобраться лучше – http://kodirovanie-ot-alkogolizma-odintsovo2.ru/
Наркологическая клиника «НОВЫЙ НАРКОЛОГ» в Санкт-Петербурге предлагает комплексное лечение алкогольной и наркотической зависимости, включая детоксикацию, амбулаторные и стационарные программы, а также психотерапевтическую поддержку. Опытные врачи СПб применяют современные методы для быстрой и эффективной помощи.
Узнать больше – https://new-narkolog.ru/stati/gemosorbciya-metody-i-pokazaniya.html
дебетовая карта курьером Ваш компетентный гид в мире банковских карт. Получение современной дебетовой карты стало простым и удобным с нашей помощью. Выберите карту, идеально отвечающую вашим потребностям, и используйте все преимущества современного финансового сервиса. Что мы предлагаем? Практические советы: Полезные рекомендации и лайфхаки для эффективного использования вашей карты. Актуальные акции: Будьте в курсе всех новых предложений и специальных условий от банков-партнеров. Преимущества нашего сообщества. Мы предоставляем полную информацию о различных типах карт, особенностях тарифов и комиссий. Наши публикации регулярно обновляются, предоставляя актуальные данные и свежие новости о продуктах российских банков. Присоединяйтесь к нашему сообществу, чтобы сделать ваши финансовые решения простыми, быстрыми и надежными. Вместе мы сможем оптимизировать использование банковских продуктов и сэкономить ваше время и средства. Наша цель — помогать вам эффективно управлять своими финансами и получать максимум выгоды от каждого взаимодействия с банком.
После процедуры пациент чувствует значительное облегчение состояния, улучшение самочувствия и снижение тяги к алкоголю.
Подробнее тут – капельница от запоя
После процедуры пациент чувствует значительное облегчение состояния, улучшение самочувствия и снижение тяги к алкоголю.
Детальнее – врач на дом капельница от запоя
После процедуры пациент чувствует значительное облегчение состояния, улучшение самочувствия и снижение тяги к алкоголю.
Получить дополнительные сведения – http://kapelnica-ot-zapoya-sochi00.ru/kapelnicza-ot-zapoya-czena-sochi/
скачать мод на тик ток последняя Мир мобильных приложений не стоит на месте, и Тик Ток продолжает оставаться одной из самых популярных платформ для создания и обмена короткими видео. Но что, если стандартной функциональности вам недостаточно? На помощь приходит Тик Ток Мод – модифицированная версия приложения, открывающая доступ к расширенным возможностям и эксклюзивным функциям.
Алкогольная зависимость — это хроническое заболевание, при котором устойчивое влечение к спиртному приводит к тяжёлым медицинским, социальным и психологическим последствиям. Когда пациент осознаёт, что самостоятельно справиться с этой проблемой не получается, наиболее эффективным методом становится кодирование от алкоголизма. В клинике «Ясное Будущее» в Одинцово мы используем сочетание проверенных методик кодирования и комплексной психологической поддержки, что позволяет достичь стойкой ремиссии и вернуть человеку контроль над собственной жизнью.
Узнать больше – kodirovanie ot alkogolizma odincovo
Аппаратные методы кодирования включают лазерную терапию и электростимуляцию биологически активных точек, влияющих на центры зависимости в головном мозге. Эти методики способствуют быстрому формированию устойчивого отвращения к спиртному и хорошо переносятся пациентами.
Получить больше информации – kodirovanie ot alkogolizma gipnozom
После процедуры пациент чувствует значительное облегчение состояния, улучшение самочувствия и снижение тяги к алкоголю.
Узнать больше – https://kapelnica-ot-zapoya-sochi00.ru/kapelnicza-ot-zapoya-detoks-sochi/
Клиника «НОВЫЙ НАРКОЛОГ» в Санкт-Петербурге — это центр помощи при зависимости с профессиональной командой наркологов и психотерапевтов. Доступны услуги детоксикации, амбулаторного и стационарного лечения, реабилитации и семейного консультирования.
Детальнее – как убрать алкогольный тремор в домашних условиях
«В первые часы после окончания запоя организм наиболее уязвим, и своевременное вмешательство значительно снижает риски осложнений», — подчёркивает заведующая отделением наркологической реанимации Елена Морозова.
Исследовать вопрос подробнее – https://vyvod-iz-zapoya-krasnogorsk2.ru/vyvod-iz-zapoya-cena
В условиях Донецка ДНР наши специалисты применяют современную методику вывода из запоя на дому, которая включает в себя несколько последовательных этапов для обеспечения максимально безопасного и эффективного лечения.
Выяснить больше – вывод из запоя донецк
Кодирование создаёт стойкое отвращение к этилированному спирту за счёт фармакологического или психотерапевтического воздействия, а дальнейшая работа с психологом помогает сформировать новую модель поведения и мотивацию к сохранению трезвости. Современные технологии в сочетании с индивидуальным подходом делают процедуру безопасной и максимально комфортной для пациента.
Изучить вопрос глубже – кодирование от алкоголизма
В клинике «НОВЫЙ НАРКОЛОГ» в СПб оказывают квалифицированную наркологическую помощь: от экстренного вывода из запоя до длительной реабилитации. Индивидуальный подход, конфиденциальность и поддержка на всех этапах выздоровления — основные принципы работы специалистов.
Получить больше информации – https://new-narkolog.ru/stati/alkogol-i-vaktsinatsiya-ot-koronavirusa-covid-19/
«Кодирование — это не магическое решение, а важный этап в комплексной программе лечения, — поясняет ведущий нарколог клиники «Ясное Будущее» Марина Иванова. — Главное — сочетание фармакологического воздействия и последующей работы с психологом для формирования устойчивой мотивации к трезвости».
Детальнее – https://kodirovanie-ot-alkogolizma-odintsovo2.ru/kodirovanie-ot-alkogolizma-cena
Этот информационный обзор станет отличным путеводителем по актуальным темам, объединяющим важные факты и мнения экспертов. Мы исследуем ключевые идеи и представляем их в доступной форме для более глубокого понимания. Читайте, чтобы оставаться в курсе событий!
Подробнее можно узнать тут – http://marcelalozano.com/mar_m001_probabilidad_50x50cm_-2
Эта статья сочетает познавательный и занимательный контент, что делает ее идеальной для любителей глубоких исследований. Мы рассмотрим увлекательные аспекты различных тем и предоставим вам новые знания, которые могут оказаться полезными в будущем.
Разобраться лучше – https://bestselection.site/kaiunbracelet-rightorleft/powerstonemigitekouka
В этой информационной статье вы найдете интересное содержание, которое поможет вам расширить свои знания. Мы предлагаем увлекательный подход и уникальные взгляды на обсуждаемые темы, побуждая пользователей к активному мышлению и критическому анализу!
Получить дополнительную информацию – https://ugi.tn/2024/05/28/bonjour-tout-le-monde
В этом интересном тексте собраны обширные сведения, которые помогут вам понять различные аспекты обсуждаемой темы. Мы разбираем детали и факты, делая акцент на важности каждого элемента. Не упустите возможность расширить свои знания и взглянуть на мир по-новому!
Ознакомиться с деталями – http://www.voxmea.com/cgi/blog/log/eid21.html
общие аккаунты стим бесплатно стим аккаунт бесплатно без игр
resume for engineer with experience resume biomedical engineer
бесплатные акки стим халявные аккаунты стим
Эта статья предлагает захватывающий и полезный контент, который привлечет внимание широкого круга читателей. Мы постараемся представить тебе идеи, которые вдохновят вас на изменения в жизни и предоставят практические решения для повседневных вопросов. Читайте и вдохновляйтесь!
Узнать больше – http://juxtapositiontwin.ru/catalog/29
Да, «Путь к жизни» оформляет все документы на номер договора без указания фамилии пациента и не передаёт сведения третьим лицам.
Подробнее тут – http://lechenie-narkomanii-volgograd9.ru
В течение полугода пациент может бесплатно посещать онлайн-группы поддержки и консультироваться у психологов клиники.
Получить дополнительную информацию – http://lechenie-narkomanii-volgograd9.ru/
фотозона баннер Фотографическая зона, оформленная баннером; декоративный баннер для фотозоны; праздничный баннер “С днем рождения” для создания фотозоны; баннер размером 2 на 2 метра, предназначенный для оформления фотозоны на дне рождения. Альтернативно, можно сказать так: Место для фотографирования, украшенное тематическим баннером; специальный баннер, используемый для создания фотозоны; баннер с надписью “С днем рождения” для оформления пространства для фотосессий; баннер с габаритами 2×2 метра, предназначенный для использования в качестве фона на дне рождения.
«Стоп Алко» — квалифицированная наркологическая помощь без ожидания. Быстрое выведение токсинов, восстановление организма, устранение последствий отравлений. Врачи работают 24/7, индивидуальный подход и полная анонимность.
Исследовать вопрос подробнее – алкоголь влияет на потенцию у мужчин
Наши специалисты строят программу лечения на основе многоступенчатой схемы, включающей медицинские, психологические и социальные компоненты. Каждый этап нацелен на устранение физической зависимости, стабилизацию психоэмоционального состояния и восстановление социальных связей.
Получить больше информации – https://lechenie-narkomanii-volgograd9.ru/czentr-lecheniya-narkomanii-volgograd
Полноценное восстановление включает не только прекращение приёма наркотиков, но и формирование здорового образа жизни, навыков эмоционального самоконтроля и социокультурной адаптации.
Изучить вопрос глубже – centr lecheniya narkomanii volgograd
Аппаратные методы кодирования включают лазерную терапию и электростимуляцию биологически активных точек, влияющих на центры зависимости в головном мозге. Эти методики способствуют быстрому формированию устойчивого отвращения к спиртному и хорошо переносятся пациентами.
Подробнее тут – https://kodirovanie-ot-alkogolizma-odintsovo2.ru/
С учётом всех этапов (детоксикация, терапевтическая работа и адаптация) курс занимает от одного до трёх месяцев, в зависимости от индивидуальных особенностей пациента.
Получить дополнительную информацию – http://lechenie-narkomanii-volgograd9.ru
Да, «Путь к жизни» оформляет все документы на номер договора без указания фамилии пациента и не передаёт сведения третьим лицам.
Получить дополнительные сведения – http://lechenie-narkomanii-volgograd9.ru/lechenie-narkomanii-i-alkogolizma-volgograd/https://lechenie-narkomanii-volgograd9.ru
После поступления в клинику проводится осмотр, измеряется давление, оценивается общее состояние. При необходимости проводятся экспресс-анализы на содержание веществ и ЭКГ.
Подробнее тут – https://narkologicheskaya-klinika-voronezh9.ru/uslugi-narkologicheskoj-kliniki-voronezh/
Да, «Путь к жизни» оформляет все документы на номер договора без указания фамилии пациента и не передаёт сведения третьим лицам.
Разобраться лучше – centr lecheniya narkomanii volgograd
Научно-популярный сайт https://phenoma.ru — малоизвестные факты, редкие феномены, тайны природы и сознания. Гипотезы, наблюдения и исследования — всё, что будоражит воображение и вдохновляет на поиски ответов.
личные дебетовые карты Ваш персональный консультант в мире банковских карт. Получение современной дебетовой карты стало простым и удобным с нашей помощью. Выберите карту, которая наилучшим образом соответствует вашим потребностям, и используйте все преимущества современного финансового сервиса. Что мы предлагаем? Ценные советы: Полезные лайфхаки и рекомендации для эффективного использования вашей карты. Актуальные акции: Будьте в курсе всех новых предложений и специальных условий от банков-партнеров. Преимущества нашего сообщества. Мы предоставляем полную информацию о различных типах карт, особенностях тарифов и комиссий. Наши публикации регулярно обновляются, предоставляя актуальные данные и свежие новости о продуктах российских банков. Присоединяйтесь к нашему сообществу, чтобы сделать ваши финансовые решения простыми, быстрыми и надежными. Вместе мы сможем оптимизировать использование банковских продуктов и сэкономить ваше время и средства. Наша цель — помогать вам эффективно управлять своими финансами и получать максимум выгоды от каждого взаимодействия с банком.
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me.
Great post. I was checking continuously this blog and I am impressed! Extremely useful information particularly the last part 🙂 I care for such information much. I was looking for this particular information for a long time. Thank you and good luck.
I like the helpful info you provide in your articles. I will bookmark your weblog and check again here regularly. I am quite sure I will learn lots of new stuff right here! Best of luck for the next!
Наркологическая клиника «Стоп Алко» — современная система экстренной помощи. Детоксикация, снятие абстиненции, внутривенная терапия и проверенные методы восстановления. Работаем круглосуточно, приезжаем быстро.
Углубиться в тему – алкогольный делирий
Алкогольная зависимость — это хроническое заболевание, при котором устойчивое влечение к спиртному приводит к тяжёлым медицинским, социальным и психологическим последствиям. Когда пациент осознаёт, что самостоятельно справиться с этой проблемой не получается, наиболее эффективным методом становится кодирование от алкоголизма. В клинике «Ясное Будущее» в Одинцово мы используем сочетание проверенных методик кодирования и комплексной психологической поддержки, что позволяет достичь стойкой ремиссии и вернуть человеку контроль над собственной жизнью.
Ознакомиться с деталями – https://kodirovanie-ot-alkogolizma-odintsovo2.ru/kodirovanie-ot-alkogolizma-na-domu
Перед тем как перейти к описанию методов и стоимости, важно определить основные показания для кодирования. Ниже перечислены ключевые признаки, при наличии которых кодирование рекомендуется как этап комплексного лечения:
Получить больше информации – kodirovanie ot alkogolizma
«Стоп Алко» — квалифицированная наркологическая помощь без ожидания. Быстрое выведение токсинов, восстановление организма, устранение последствий отравлений. Врачи работают 24/7, индивидуальный подход и полная анонимность.
Подробнее – таблетки от похмелья самые эффективные
«НОВЫЙ НАРКОЛОГ» — наркологическая клиника в СПб с полным спектром услуг: детоксикация, лечение зависимостей, реабилитация, психологическая поддержка. Доверие пациентов и высокая эффективность подтверждаются отзывами и результатами работы.
Подробнее тут – как вывести человека из запоя дома
Полноценное восстановление включает не только прекращение приёма наркотиков, но и формирование здорового образа жизни, навыков эмоционального самоконтроля и социокультурной адаптации.
Ознакомиться с деталями – lechenie narkomanii i alkogolizma volgograd
дистанційна робота для дівчат Польща Стань вебкам моделью в польской студии, работающей в Варшаве! Открыты вакансии для девушек в Польше, особенно для тех, кто говорит по-русски. Ищешь способ заработать онлайн в Польше? Предлагаем подработку для девушек в Варшаве с возможностью работы в интернете, даже с проживанием. Рассматриваешь удаленную работу в Польше? Узнай, как стать вебкам моделью и сколько можно заработать. Работа для украинок в Варшаве и высокооплачиваемые возможности для девушек в Польше ждут тебя. Мы предлагаем легальную вебкам работу в Польше, онлайн работа без необходимости знания польского языка. Приглашаем девушек без опыта в Варшаве в нашу вебкам студию с обучением. Возможность заработка в интернете без вложений. Работа моделью онлайн в Польше — это шанс для тебя! Ищешь “praca dla dziewczyn online”, “praca webcam Polska”, “praca modelka online” или “zarabianie przez internet dla kobiet”? Наше “agencja webcam Warszawa” и “webcam studio Polska” предлагают “praca dla mlodych kobiet Warszawa” и “legalna praca online Polska”. Смотри “oferty pracy dla Ukrainek w Polsce” и “praca z domu dla dziewczyn”.
С учётом всех этапов (детоксикация, терапевтическая работа и адаптация) курс занимает от одного до трёх месяцев, в зависимости от индивидуальных особенностей пациента.
Получить дополнительную информацию – лечение наркомании наркология
С учётом всех этапов (детоксикация, терапевтическая работа и адаптация) курс занимает от одного до трёх месяцев, в зависимости от индивидуальных особенностей пациента.
Исследовать вопрос подробнее – https://lechenie-narkomanii-volgograd9.ru/lechenie-narkomanii-i-alkogolizma-volgograd/
Наши специалисты строят программу лечения на основе многоступенчатой схемы, включающей медицинские, психологические и социальные компоненты. Каждый этап нацелен на устранение физической зависимости, стабилизацию психоэмоционального состояния и восстановление социальных связей.
Углубиться в тему – лечение наркомании и алкоголизма
Платная наркологическая клиника «НОВЫЙ НАРКОЛОГ» в Санкт-Петербурге обеспечивает профессиональное лечение зависимостей, включая кодирование, медикаментозную терапию и восстановление психологического состояния. Круглосуточный приём и выезд врача на дом.
Получить дополнительные сведения – https://new-narkolog.ru/narkologicheskaya-pomosch/
Да, «Путь к жизни» оформляет все документы на номер договора без указания фамилии пациента и не передаёт сведения третьим лицам.
Получить дополнительные сведения – центр лечения наркомании в волгограде
С учётом всех этапов (детоксикация, терапевтическая работа и адаптация) курс занимает от одного до трёх месяцев, в зависимости от индивидуальных особенностей пациента.
Углубиться в тему – https://lechenie-narkomanii-volgograd9.ru/lechenie-narkomanii-i-alkogolizma-volgograd
С учётом всех этапов (детоксикация, терапевтическая работа и адаптация) курс занимает от одного до трёх месяцев, в зависимости от индивидуальных особенностей пациента.
Получить дополнительную информацию – https://lechenie-narkomanii-volgograd9.ru/czentr-lecheniya-narkomanii-volgograd
Платная наркологическая клиника «НОВЫЙ НАРКОЛОГ» в Санкт-Петербурге обеспечивает профессиональное лечение зависимостей, включая кодирование, медикаментозную терапию и восстановление психологического состояния. Круглосуточный приём и выезд врача на дом.
Получить дополнительные сведения – https://new-narkolog.ru/kodirovanie-ot-alkogolizma/anonimnoe-kodirovanie-ot-alkogolizma/
Ниже приведены ключевые сигналы, при появлении которых требуется немедленное реагирование:
Углубиться в тему – https://vyvod-iz-zapoya-krasnogorsk2.ru/vyvod-iz-zapoya-anonimno/
Мы принимаем пациентов старше 18 лет; для лиц старше 65 лет возможна адаптация схемы с учётом сопутствующих заболеваний.
Исследовать вопрос подробнее – принудительное лечение наркомании в волгограде
Ниже приведены ключевые сигналы, при появлении которых требуется немедленное реагирование:
Детальнее – vyvod iz zapoya
Врач устанавливает внутривенную капельницу, через которую вводятся специально подобранные препараты для очищения организма от алкоголя, восстановления баланса жидкости и нормализации работы всех органов и систем. В течение всей процедуры специалист следит за состоянием пациента и, при необходимости, корректирует терапию.
Выяснить больше – http://kapelnica-ot-zapoya-sochi00.ru
Алкогольная зависимость — это хроническое заболевание, при котором устойчивое влечение к спиртному приводит к тяжёлым медицинским, социальным и психологическим последствиям. Когда пациент осознаёт, что самостоятельно справиться с этой проблемой не получается, наиболее эффективным методом становится кодирование от алкоголизма. В клинике «Ясное Будущее» в Одинцово мы используем сочетание проверенных методик кодирования и комплексной психологической поддержки, что позволяет достичь стойкой ремиссии и вернуть человеку контроль над собственной жизнью.
Узнать больше – http://kodirovanie-ot-alkogolizma-odintsovo2.ru/kodirovanie-ot-alkogolizma-na-domu/
При длительном запое или серьезной алкогольной интоксикации часто нет возможности или желания ехать в стационар. В таких ситуациях оптимальным решением становится вызов нарколога на дом в Сочи. Специалисты клиники «Жизнь без Запоя» круглосуточно приезжают к пациентам, оперативно оказывают медицинскую помощь и проводят профессиональную детоксикацию организма прямо в домашних условиях. Благодаря комфортному лечению на дому пациенты быстрее восстанавливаются, избегают дополнительного стресса и осложнений, связанных с госпитализацией.
Узнать больше – http://narcolog-na-dom-sochi0.ru/narkolog-na-dom-czena-sochi/
В этом интересном тексте собраны обширные сведения, которые помогут вам понять различные аспекты обсуждаемой темы. Мы разбираем детали и факты, делая акцент на важности каждого элемента. Не упустите возможность расширить свои знания и взглянуть на мир по-новому!
Подробнее – https://terapiasma.cl/wp/?p=9339
Этот информативный текст выделяется своими захватывающими аспектами, которые делают сложные темы доступными и понятными. Мы стремимся предложить читателям глубину знаний вместе с разнообразием интересных фактов. Откройте новые горизонты и развивайте свои способности познавать мир!
Подробнее – https://www.celinepeters.nl/derde-oog-workshop
Эта публикация погружает вас в мир увлекательных фактов и удивительных открытий. Мы расскажем о ключевых событиях, которые изменили ход истории, и приоткроем завесу над научными достижениями, которые вдохновили миллионы. Узнайте, чему может научить нас прошлое и как применить эти знания в будущем.
Ознакомиться с деталями – http://traffikreklam.com/index.php/2016/03/01/standard-post-with-preview-picture-images-slider
В этом интересном тексте собраны обширные сведения, которые помогут вам понять различные аспекты обсуждаемой темы. Мы разбираем детали и факты, делая акцент на важности каждого элемента. Не упустите возможность расширить свои знания и взглянуть на мир по-новому!
Подробнее можно узнать тут – https://avcanroca.org/archives/aiovg_videos/v-festa-major-infantil-virtual-can-roca-2020
В данной обзорной статье представлены интригующие факты, которые не оставят вас равнодушными. Мы критикуем и анализируем события, которые изменили наше восприятие мира. Узнайте, что стоит за новыми открытиями и как они могут изменить ваше восприятие реальности.
Изучить вопрос глубже – https://www.charivarietcompagnie.fr/realisations
работа моделью онлайн в Польше Стань вебкам моделью в польской студии, работающей в Варшаве! Открыты вакансии для девушек в Польше, особенно для тех, кто говорит по-русски. Ищешь способ заработать онлайн в Польше? Предлагаем подработку для девушек в Варшаве с возможностью работы в интернете, даже с проживанием. Рассматриваешь удаленную работу в Польше? Узнай, как стать вебкам моделью и сколько можно заработать. Работа для украинок в Варшаве и высокооплачиваемые возможности для девушек в Польше ждут тебя. Мы предлагаем легальную вебкам работу в Польше, онлайн работа без необходимости знания польского языка. Приглашаем девушек без опыта в Варшаве в нашу вебкам студию с обучением. Возможность заработка в интернете без вложений. Работа моделью онлайн в Польше — это шанс для тебя! Ищешь “praca dla dziewczyn online”, “praca webcam Polska”, “praca modelka online” или “zarabianie przez internet dla kobiet”? Наше “agencja webcam Warszawa” и “webcam studio Polska” предлагают “praca dla mlodych kobiet Warszawa” и “legalna praca online Polska”. Смотри “oferty pracy dla Ukrainek w Polsce” и “praca z domu dla dziewczyn”.
Этот информационный материал привлекает внимание множеством интересных деталей и необычных ракурсов. Мы предлагаем уникальные взгляды на привычные вещи и рассматриваем вопросы, которые волнуют общество. Будьте в курсе актуальных тем и расширяйте свои знания!
Выяснить больше – https://pdnyanlaeg.dk/a-nice-post
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Подробнее – https://jereparsdetoi.org/ar/blog/2020/05/30/r2
В этом интересном тексте собраны обширные сведения, которые помогут вам понять различные аспекты обсуждаемой темы. Мы разбираем детали и факты, делая акцент на важности каждого элемента. Не упустите возможность расширить свои знания и взглянуть на мир по-новому!
Детальнее – https://divinedivaevents.com/sed-ut-perspiciatis-unde-omnis-iste-natus-error-sit
Для эффективного лечения алкогольной интоксикации и восстановления организма врачи клиники «АлкоДоктор» используют комплекс препаратов, которые индивидуально подбираются с учетом состояния пациента.
Подробнее можно узнать тут – https://kapelnica-ot-zapoya-sochi0.ru/kapelnicza-ot-zapoya-detoks-sochi/
В этой статье вы найдете познавательную и занимательную информацию, которая поможет вам лучше понять мир вокруг. Мы собрали интересные данные, которые вдохновляют на размышления и побуждают к действиям. Открывайте новую информацию и получайте удовольствие от чтения!
Подробнее можно узнать тут – https://iamkblog.com/img_2407
Этот информационный обзор станет отличным путеводителем по актуальным темам, объединяющим важные факты и мнения экспертов. Мы исследуем ключевые идеи и представляем их в доступной форме для более глубокого понимания. Читайте, чтобы оставаться в курсе событий!
Выяснить больше – https://swedfriends.com/visiting-green-association-of-kurdistan
Когда организм на пределе, важна срочная помощь в Сочи — это команда опытных наркологов, которые помогут быстро и мягко выйти из запоя без вреда для здоровья.
Выяснить больше – запой нарколог на дом
собрать компьютер онлайн Компьютер для стрима: Высокое качество трансляций Компьютер для стрима должен обеспечивать стабильную работу во время трансляций, высокое качество изображения и звука. Сборка компьютера на заказ позволяет выбрать компоненты, способные справиться с этими задачами.
Перед тем как перейти к описанию методов и стоимости, важно определить основные показания для кодирования. Ниже перечислены ключевые признаки, при наличии которых кодирование рекомендуется как этап комплексного лечения:
Получить дополнительные сведения – https://kodirovanie-ot-alkogolizma-odintsovo2.ru/kodirovanie-ot-alkogolizma-cena
Перед тем как перейти к описанию методов и стоимости, важно определить основные показания для кодирования. Ниже перечислены ключевые признаки, при наличии которых кодирование рекомендуется как этап комплексного лечения:
Выяснить больше – http://kodirovanie-ot-alkogolizma-odintsovo2.ru/kodirovanie-ot-alkogolizma-cena/
В нашей клинике применяются различные техники кодирования, которые подбираются с учётом медицинских показаний, психологического состояния и пожеланий пациента.
Детальнее – https://kodirovanie-ot-alkogolizma-odintsovo2.ru/kodirovanie-ot-alkogolizma-cena
В Сочи решение есть — наркологическая клиника. Здесь помогают людям выйти из запоя без страха и осуждения. Всё анонимно, грамотно и с заботой о каждом пациенте.
Исследовать вопрос подробнее – врач нарколог на дом
В Сочи решение есть — наркологическая клиника. Здесь помогают людям выйти из запоя без страха и осуждения. Всё анонимно, грамотно и с заботой о каждом пациенте.
Подробнее можно узнать тут – vyzov-narkologa-na-dom
Миссия центра “Луч Надежды” — помогать людям, попавшим в плен зависимости, находить путь к выздоровлению. Мы не ограничиваемся лечением, а делаем акцент на профилактике рецидивов, социальной адаптации пациентов и их возвращении к полноценной, радостной жизни без психоактивных веществ.
Детальнее – вывод из запоя цена наркология
Каждый день запоя увеличивает риск для жизни. Не рискуйте — специалисты в Сочи приедут на дом и окажут экстренную помощь. Без боли, стресса и ожидания.
Ознакомиться с деталями – нарколог на дом
Наркологический центр “Луч Надежды” — это место, где можно найти поддержку и помощь, даже когда кажется, что выход потерян. Наша команда врачей-наркологов, психологов и психотерапевтов использует современные методы лечения и реабилитации, помогая пациентам вернуть трезвость и полноценную жизнь. Мы стремимся не только к устранению симптомов, но и к выявлению причин заболевания, давая пациентам необходимые инструменты для борьбы с тягой к психоактивным веществам и формированию новых жизненных установок.
Подробнее можно узнать тут – вывод из запоя круглосуточно уфа
В Сочи решение есть — наркологическая клиника. Здесь помогают людям выйти из запоя без страха и осуждения. Всё анонимно, грамотно и с заботой о каждом пациенте.
Ознакомиться с деталями – нарколог на дом недорого
Основой успешной работы клиники “Луч Надежды” является команда высококвалифицированных специалистов, которые искренне стремятся помочь людям в борьбе с зависимостью. Наши врачи-наркологи высшей категории обладают большим опытом в лечении различных видов зависимости и владеют современными методами детоксикации, купирования абстинентного синдрома, кодирования и фармакотерапии.
Ознакомиться с деталями – наркологический центр уфа
«В первые часы после окончания запоя организм наиболее уязвим, и своевременное вмешательство значительно снижает риски осложнений», — подчёркивает заведующая отделением наркологической реанимации Елена Морозова.
Подробнее – срочный вывод из запоя
Эта публикация дает возможность задействовать различные источники информации и представить их в удобной форме. Читатели смогут быстро найти нужные данные и получить ответы на интересующие их вопросы. Мы стремимся к четкости и доступности материала для всех!
Углубиться в тему – https://www.clauskc.dk/blog.php/htl.com/%D0%9A%D0%B0%D0%BA%D0%A1%D0%B2%D0%BE%D0%B8%D0%BC+-+%D0%BF%D0%B5%D1%80%D0%B5%D1%82%D1%8F%D0%B6%D0%BA%D0%B0+%D0%BC%D0%B5%D0%B1%D0%B5%D0%BB%D0%B8?n=393
Алкогольная зависимость — это хроническое заболевание, при котором устойчивое влечение к спиртному приводит к тяжёлым медицинским, социальным и психологическим последствиям. Когда пациент осознаёт, что самостоятельно справиться с этой проблемой не получается, наиболее эффективным методом становится кодирование от алкоголизма. В клинике «Ясное Будущее» в Одинцово мы используем сочетание проверенных методик кодирования и комплексной психологической поддержки, что позволяет достичь стойкой ремиссии и вернуть человеку контроль над собственной жизнью.
Изучить вопрос глубже – http://kodirovanie-ot-alkogolizma-odintsovo2.ru/kodirovanie-ot-alkogolizma-cena/
Эта публикация дает возможность задействовать различные источники информации и представить их в удобной форме. Читатели смогут быстро найти нужные данные и получить ответы на интересующие их вопросы. Мы стремимся к четкости и доступности материала для всех!
Получить дополнительные сведения – https://vhwconsulting.be/component/k2/item/3-these-cases-are-perfectly-simple-and-easy-to-distinguish?start=68990
Современная наркология предлагает два основных формата вывода из запоя:
Разобраться лучше – вывод из запоя в стационаре
I don’t think the title of your article matches the content lol. Just kidding, mainly because I had some doubts after reading the article.
Алкогольный запой — это острое состояние тяжёлой интоксикации, при котором организм накапливает критические уровни продуктов распада этанола и перестаёт справляться с их нейтрализацией. При этом страдают важнейшие органы и системы: печень, почки, сердце, центральная нервная система. Без квалифицированной медицинской помощи риск развития судорог, алкогольного делирия и полиорганной недостаточности возрастает многократно.
Подробнее можно узнать тут – vyvod iz zapoya anonimno
Эта статья сочетает в себе как полезные, так и интересные сведения, которые обогатят ваше понимание насущных тем. Мы предлагаем практические советы и рекомендации, которые легко внедрить в повседневную жизнь. Узнайте, как улучшить свои навыки и обогатить свой опыт с помощью простых, но эффективных решений.
Изучить вопрос глубже – https://www.taxidermia.cl/sitio/ets0289
В данной обзорной статье представлены интригующие факты, которые не оставят вас равнодушными. Мы критикуем и анализируем события, которые изменили наше восприятие мира. Узнайте, что стоит за новыми открытиями и как они могут изменить ваше восприятие реальности.
Детальнее – https://senyumpeople.com/2015/04/29/justin-pearson
Эта статья полна интересного контента, который побудит вас исследовать новые горизонты. Мы собрали полезные факты и удивительные истории, которые обогащают ваше понимание темы. Читайте, погружайтесь в детали и наслаждайтесь процессом изучения!
Подробнее можно узнать тут – https://www.forestpub.co.jp/author/oishi/lp/shikou2/hello-world
Эта статья сочетает познавательный и занимательный контент, что делает ее идеальной для любителей глубоких исследований. Мы рассмотрим увлекательные аспекты различных тем и предоставим вам новые знания, которые могут оказаться полезными в будущем.
Получить больше информации – https://irishnationals.ie/results-marks-2018-2/25-boys-16-17
В этой статье-обзоре мы соберем актуальную информацию и интересные факты, которые освещают важные темы. Читатели смогут ознакомиться с различными мнениями и подходами, что позволит им расширить кругозор и глубже понять обсуждаемые вопросы.
Ознакомиться с деталями – https://avcanroca.org/archives/aiovg_videos/v-festa-major-infantil-virtual-can-roca-2020
Эта статья сочетает в себе как полезные, так и интересные сведения, которые обогатят ваше понимание насущных тем. Мы предлагаем практические советы и рекомендации, которые легко внедрить в повседневную жизнь. Узнайте, как улучшить свои навыки и обогатить свой опыт с помощью простых, но эффективных решений.
Детальнее – https://creditnice.ru/polezno-znat
Каждый пациент проходит три основные стадии терапии, начиная с момента первого обращения.
Получить больше информации – наркологическая клиника в уфе
Каждый пациент проходит три основные стадии терапии, начиная с момента первого обращения.
Получить больше информации – частная наркологическая клиника уфа.
Для комплексного восстановления мы предлагаем ряд вспомогательных процедур, которые улучшают самочувствие и ускоряют реабилитацию.
Подробнее тут – наркологические клиники алкоголизм
I don’t think the title of your article matches the content lol. Just kidding, mainly because I had some doubts after reading the article.
Перед началом процедуры врач проводит осмотр: измеряет давление, пульс, уровень кислорода в крови, оценивает тяжесть абстинентного синдрома. В зависимости от результатов и наличия сопутствующих заболеваний составляется индивидуальный состав инфузионного раствора. Он может включать:
Подробнее – http://www.domen.ru
Мы понимаем, насколько важна приватность для пациентов и их близких. В «Возрождение» все обращения регистрируются по номеру договора, без упоминания личных данных в государственных базах. Даже близкие могут не знать точного диагноза, если пациент пожелает сохранить это в тайне.
Исследовать вопрос подробнее – бесплатная наркологическая клиника
Клиника «Возрождение» гарантирует:
Получить дополнительные сведения – наркологические клиники алкоголизм в уфе
Самостоятельно выйти из запоя — почти невозможно. В Сочи врачи клиники проводят медикаментозный вывод из запоя с круглосуточным выездом. Доверяйте профессионалам.
Получить дополнительные сведения – нарколог на дом недорого
Запой — это не просто следствие чрезмерного употребления алкоголя, а серьёзное патологическое состояние, которое требует срочной медицинской помощи. На фоне затяжного приёма спиртного в организме человека происходят опасные изменения: интоксикация, обезвоживание, нарушение электролитного баланса, резкие скачки давления и работы сердца, угнетение функций печени и мозга. В такой ситуации капельница от запоя становится неотложной мерой, позволяющей стабилизировать состояние и устранить симптомы абстиненции за короткий срок.
Узнать больше – https://kapelnica-ot-zapoya-msk55.ru
Каждый пациент проходит три основные стадии терапии, начиная с момента первого обращения.
Получить больше информации – http://
Перед началом процедуры врач проводит осмотр: измеряет давление, пульс, уровень кислорода в крови, оценивает тяжесть абстинентного синдрома. В зависимости от результатов и наличия сопутствующих заболеваний составляется индивидуальный состав инфузионного раствора. Он может включать:
Исследовать вопрос подробнее – postavit kapelnitsu ot zapoia odintsovo
Thank you for your sharing. I am worried that I lack creative ideas. It is your article that makes me full of hope. Thank you. But, I have a question, can you help me?
Клиника «Возрождение» гарантирует:
Углубиться в тему – наркологическая клиника республика башкортостан
Наш стационар оснащён всем необходимым для безопасного и комфортного лечения. Здесь вы получите круглосуточный мониторинг, современное оборудование и услуги психологов, социальных педагогов и физиотерапевтов.
Подробнее можно узнать тут – наркологическая клиника нарколог
Самостоятельно выйти из запоя — почти невозможно. В Сочи врачи клиники проводят медикаментозный вывод из запоя с круглосуточным выездом. Доверяйте профессионалам.
Разобраться лучше – нарколог на дом вывод
Наш стационар оснащён всем необходимым для безопасного и комфортного лечения. Здесь вы получите круглосуточный мониторинг, современное оборудование и услуги психологов, социальных педагогов и физиотерапевтов.
Получить дополнительную информацию – наркологические клиники алкоголизм в уфе
Близкий человек в запое? Не ждите ухудшения. Обратитесь в клинику Сочи — здесь проведут профессиональный вывод из запоя с последующим восстановлением организма.
Исследовать вопрос подробнее – выезд нарколога на дом
Когда организм на пределе, важна срочная помощь в Сочи — это команда опытных наркологов, которые помогут быстро и мягко выйти из запоя без вреда для здоровья.
Выяснить больше – нарколог на дом недорого
Каждый пациент проходит три основные стадии терапии, начиная с момента первого обращения.
Углубиться в тему – https://narkologicheskaya-klinika-ufa9.ru/chastnaya-narkologicheskaya-klinika-ufa
Для комплексного восстановления мы предлагаем ряд вспомогательных процедур, которые улучшают самочувствие и ускоряют реабилитацию.
Выяснить больше – http://narkologicheskaya-klinika-ufa9.ru/chastnaya-narkologicheskaya-klinika-ufa/
Клиника «Возрождение» гарантирует:
Подробнее – narkologicheskaya-klinika-ufa9.ru/
Клиника «Возрождение» гарантирует:
Исследовать вопрос подробнее – https://narkologicheskaya-klinika-ufa9.ru/narkologicheskie-kliniki-alkogolizm-ufa
В Сочи решение есть — наркологическая клиника. Здесь помогают людям выйти из запоя без страха и осуждения. Всё анонимно, грамотно и с заботой о каждом пациенте.
Подробнее – врач нарколог на дом
В наркологической клинике «Перезагрузка» в Химках капельницы проводятся под строгим медицинским наблюдением. Мы используем современные препараты, индивидуально подбираем состав инфузии и гарантируем конфиденциальность. Наша задача — не просто снять симптомы, а обеспечить реальную поддержку организму на физиологическом уровне, чтобы предотвратить повторный срыв и минимизировать риски для здоровья.
Узнать больше – поставить капельницу от запоя
Показанием к стационарному лечению служат случаи, при которых домашняя терапия становится небезопасной или недостаточно эффективной. Рекомендуем госпитализацию при:
Выяснить больше – http://narkologicheskaya-klinika-ufa9.ru/narkologicheskie-kliniki-alkogolizm-ufa/
Thanks , I’ve recently been searching for information approximately this topic for a long time and yours is the best I’ve discovered till now. However, what in regards to the conclusion? Are you positive concerning the source?
F*ckin? awesome things here. I?m very glad to see your post. Thanks a lot and i’m looking forward to contact you. Will you please drop me a mail?
Каждый день запоя увеличивает риск для жизни. Не рискуйте — специалисты в Сочи приедут на дом и окажут экстренную помощь. Без боли, стресса и ожидания.
Узнать больше – нарколог на дом круглосуточно
Эти процедуры направлены на фильтрацию плазмы и избавление крови от токсинов:
Подробнее тут – наркологический вывод из запоя красноярск
Каждый пациент проходит три основные стадии терапии, начиная с момента первого обращения.
Выяснить больше – http://narkologicheskaya-klinika-ufa9.ru
Запой — это не просто несколько дней бесконтрольного употребления алкоголя. Это тяжёлое патологическое состояние, при котором организм человека накапливает токсические продукты распада этанола, теряет жизненно важные электролиты, обезвоживается и выходит из равновесия. На фоне этого нарушается работа сердца, мозга, печени и других систем. Чем дольше длится запой, тем тяжелее последствия и выше риск развития осложнений, вплоть до алкогольного психоза или инсульта. В такой ситуации незаменимым методом экстренной помощи становится капельница от запоя — процедура, позволяющая быстро и безопасно вывести токсины, стабилизировать жизненно важные функции и вернуть человеку контроль над собой.
Подробнее – kapelnica-ot-zapoya-moskva3.ru/
Этот этап лечения направлен на купирование острых симптомов, связанных с абстинентным синдромом. Пациенту назначаются современные препараты, способствующие выведению токсинов, нормализации работы сердца, печени, центральной нервной системы.
Получить дополнительную информацию – наркологические клиники алкоголизм волгоградская область
Дополнительно усиливаются сердечно-сосудистые риски: густая кровь, дефицит калия и магния провоцируют тахикардию, скачки давления и повышают вероятность инфаркта или инсульта. На этом фоне даже простая головная боль может оказаться сигналом серьёзного сосудистого нарушения. Задача капельницы — не просто убрать симптомы, а стабилизировать состояние организма и предотвратить дальнейшее ухудшение.
Подробнее можно узнать тут – капельница от запоя цена
Клиника «Возрождение» гарантирует:
Выяснить больше – бесплатная наркологическая клиника в уфе
Базовый метод, сочетающий регидратацию, электролитную коррекцию и витаминные комплексы:
Разобраться лучше – http://medicinskij-vyvod-iz-zapoya.ru/vyvod-iz-zapoya-krulosutochno-krasnoyarsk/
Запой — это не просто несколько дней бесконтрольного употребления алкоголя. Это тяжёлое патологическое состояние, при котором организм человека накапливает токсические продукты распада этанола, теряет жизненно важные электролиты, обезвоживается и выходит из равновесия. На фоне этого нарушается работа сердца, мозга, печени и других систем. Чем дольше длится запой, тем тяжелее последствия и выше риск развития осложнений, вплоть до алкогольного психоза или инсульта. В такой ситуации незаменимым методом экстренной помощи становится капельница от запоя — процедура, позволяющая быстро и безопасно вывести токсины, стабилизировать жизненно важные функции и вернуть человеку контроль над собой.
Получить дополнительную информацию – http://kapelnica-ot-zapoya-moskva3.ru
Запой — это не просто следствие чрезмерного употребления алкоголя, а серьёзное патологическое состояние, которое требует срочной медицинской помощи. На фоне затяжного приёма спиртного в организме человека происходят опасные изменения: интоксикация, обезвоживание, нарушение электролитного баланса, резкие скачки давления и работы сердца, угнетение функций печени и мозга. В такой ситуации капельница от запоя становится неотложной мерой, позволяющей стабилизировать состояние и устранить симптомы абстиненции за короткий срок.
Получить дополнительные сведения – vrach na dom kapelnitsa ot zapoia odintsovo
Обратиться за помощью необходимо при:
Получить больше информации – https://medicinskij-vyvod-iz-zapoya.ru/vyvod-iz-zapoya-na-domu-krasnoyarsk/
Капельница от запоя необходима, если у пациента наблюдаются следующие симптомы:
Получить дополнительные сведения – kapelnitsa ot zapoia tsena
Каждый пациент проходит три основные стадии терапии, начиная с момента первого обращения.
Выяснить больше – http://narkologicheskaya-klinika-ufa9.ru/narkologicheskie-kliniki-alkogolizm-ufa/https://narkologicheskaya-klinika-ufa9.ru
Показанием к стационарному лечению служат случаи, при которых домашняя терапия становится небезопасной или недостаточно эффективной. Рекомендуем госпитализацию при:
Узнать больше – https://narkologicheskaya-klinika-ufa9.ru/narkologicheskie-kliniki-alkogolizm-ufa
Наш стационар оснащён всем необходимым для безопасного и комфортного лечения. Здесь вы получите круглосуточный мониторинг, современное оборудование и услуги психологов, социальных педагогов и физиотерапевтов.
Детальнее – частная наркологическая клиника уфа
В Сочи решение есть — наркологическая клиника. Здесь помогают людям выйти из запоя без страха и осуждения. Всё анонимно, грамотно и с заботой о каждом пациенте.
Исследовать вопрос подробнее – нарколог на дом круглосуточно
Каждый пациент проходит три основные стадии терапии, начиная с момента первого обращения.
Получить дополнительные сведения – наркологическая клиника республика башкортостан
Клиника «Возрождение» гарантирует:
Получить дополнительные сведения – https://narkologicheskaya-klinika-ufa9.ru
температура воды красное море
Запой — это не просто следствие чрезмерного употребления алкоголя, а серьёзное патологическое состояние, которое требует срочной медицинской помощи. На фоне затяжного приёма спиртного в организме человека происходят опасные изменения: интоксикация, обезвоживание, нарушение электролитного баланса, резкие скачки давления и работы сердца, угнетение функций печени и мозга. В такой ситуации капельница от запоя становится неотложной мерой, позволяющей стабилизировать состояние и устранить симптомы абстиненции за короткий срок.
Изучить вопрос глубже – врача капельницу от запоя
Близкий человек в запое? Не ждите ухудшения. Обратитесь в клинику Сочи — здесь проведут профессиональный вывод из запоя с последующим восстановлением организма.
Узнать больше – выезд нарколога на дом
Капельница от запоя необходима, если у пациента наблюдаются следующие симптомы:
Подробнее – поставить капельницу от запоя
Затяжной запой опасен для жизни. Врачи наркологической клиники в Сочи проводят срочный вывод из запоя — на дому или в стационаре. Анонимно, безопасно, круглосуточно.
Изучить вопрос глубже – vyzov-narkologa-na-dom
Наш стационар оснащён всем необходимым для безопасного и комфортного лечения. Здесь вы получите круглосуточный мониторинг, современное оборудование и услуги психологов, социальных педагогов и физиотерапевтов.
Изучить вопрос глубже – chastnaya narkologicheskaya klinika ufa
Когда организм на пределе, важна срочная помощь в Сочи — это команда опытных наркологов, которые помогут быстро и мягко выйти из запоя без вреда для здоровья.
Углубиться в тему – https://narkolog-na-dom-ekaterinburg11.ru
Капельница от запоя необходима, если у пациента наблюдаются следующие симптомы:
Подробнее тут – http://kapelnica-ot-zapoya-msk55.ru
Близкий человек в запое? Не ждите ухудшения. Обратитесь в клинику Сочи — здесь проведут профессиональный вывод из запоя с последующим восстановлением организма.
Подробнее тут – врач нарколог на дом
Мы понимаем, насколько важна приватность для пациентов и их близких. В «Возрождение» все обращения регистрируются по номеру договора, без упоминания личных данных в государственных базах. Даже близкие могут не знать точного диагноза, если пациент пожелает сохранить это в тайне.
Разобраться лучше – наркологическая клиника уфа.
Каждый пациент проходит три основные стадии терапии, начиная с момента первого обращения.
Изучить вопрос глубже – http://narkologicheskaya-klinika-ufa9.ru/narkologicheskie-kliniki-alkogolizm-ufa/
Каждый день запоя увеличивает риск для жизни. Не рискуйте — специалисты в Сочи приедут на дом и окажут экстренную помощь. Без боли, стресса и ожидания.
Ознакомиться с деталями – вызвать нарколога на дом
Капельница от запоя необходима, если у пациента наблюдаются следующие симптомы:
Подробнее можно узнать тут – vyezd na dom kapelnitsa ot zapoia
Самостоятельно выйти из запоя — почти невозможно. В Сочи врачи клиники проводят медикаментозный вывод из запоя с круглосуточным выездом. Доверяйте профессионалам.
Подробнее можно узнать тут – врач нарколог на дом
В наркологической клинике «Прозрение» в Одинцово процедура проводится с соблюдением всех стандартов безопасности, под контролем опытных врачей. Мы применяем комплексный подход, направленный не только на детоксикацию, но и на поддержку всех систем организма. Уже после одного сеанса пациенты отмечают улучшение самочувствия, снижение тревожности, исчезновение головной боли и тошноты.
Получить больше информации – vyezd na dom kapelnitsa ot zapoia
В наркологической клинике «Прозрение» в Одинцово процедура проводится с соблюдением всех стандартов безопасности, под контролем опытных врачей. Мы применяем комплексный подход, направленный не только на детоксикацию, но и на поддержку всех систем организма. Уже после одного сеанса пациенты отмечают улучшение самочувствия, снижение тревожности, исчезновение головной боли и тошноты.
Углубиться в тему – vrach na dom kapelnitsa ot zapoia odintsovo
excellent issues altogether, you simply gained a brand new reader. What might you recommend about your publish that you just made some days ago? Any positive?
Hello, Neat post. There’s an issue together with your site in web explorer, could test this? IE still is the market leader and a huge component of people will miss your great writing due to this problem.
Капельница от запоя необходима, если у пациента наблюдаются следующие симптомы:
Изучить вопрос глубже – поставить капельницу от запоя
Процедура начинается с врачебного осмотра. Специалист оценивает общее состояние, артериальное давление, пульс, сатурацию, уровень обезвоживания, жалобы пациента. При необходимости проводятся экспресс-анализы. Далее индивидуально подбирается состав инфузионной терапии. В большинстве случаев капельница включает:
Узнать больше – vyzvat kapelnitsu ot zapoia khimki
Капельница от запоя необходима, если у пациента наблюдаются следующие симптомы:
Подробнее – kapelnitsa ot zapoia odintsovo
Запой — это не просто несколько дней бесконтрольного употребления алкоголя. Это тяжёлое патологическое состояние, при котором организм человека накапливает токсические продукты распада этанола, теряет жизненно важные электролиты, обезвоживается и выходит из равновесия. На фоне этого нарушается работа сердца, мозга, печени и других систем. Чем дольше длится запой, тем тяжелее последствия и выше риск развития осложнений, вплоть до алкогольного психоза или инсульта. В такой ситуации незаменимым методом экстренной помощи становится капельница от запоя — процедура, позволяющая быстро и безопасно вывести токсины, стабилизировать жизненно важные функции и вернуть человеку контроль над собой.
Подробнее тут – kapelnitsa ot zapoia na domu khimki
Самостоятельно выйти из запоя — почти невозможно. В Сочи врачи клиники проводят медикаментозный вывод из запоя с круглосуточным выездом. Доверяйте профессионалам.
Получить дополнительную информацию – вызов врача нарколога на дом
Самостоятельно выйти из запоя — почти невозможно. В Сочи врачи клиники проводят медикаментозный вывод из запоя с круглосуточным выездом. Доверяйте профессионалам.
Получить дополнительные сведения – запой нарколог на дом
Каждый день запоя увеличивает риск для жизни. Не рискуйте — специалисты в Сочи приедут на дом и окажут экстренную помощь. Без боли, стресса и ожидания.
Получить дополнительные сведения – вызов врача нарколога на дом
Наш стационар оснащён всем необходимым для безопасного и комфортного лечения. Здесь вы получите круглосуточный мониторинг, современное оборудование и услуги психологов, социальных педагогов и физиотерапевтов.
Углубиться в тему – наркологическая клиника уфа
Мы понимаем, насколько важна приватность для пациентов и их близких. В «Возрождение» все обращения регистрируются по номеру договора, без упоминания личных данных в государственных базах. Даже близкие могут не знать точного диагноза, если пациент пожелает сохранить это в тайне.
Узнать больше – https://narkologicheskaya-klinika-ufa9.ru
Близкий человек в запое? Не ждите ухудшения. Обратитесь в клинику Сочи — здесь проведут профессиональный вывод из запоя с последующим восстановлением организма.
Подробнее можно узнать тут – https://narkolog-na-dom-ekaterinburg12.ru
Наш стационар оснащён всем необходимым для безопасного и комфортного лечения. Здесь вы получите круглосуточный мониторинг, современное оборудование и услуги психологов, социальных педагогов и физиотерапевтов.
Ознакомиться с деталями – http://narkologicheskaya-klinika-ufa9.ru/narkologicheskie-kliniki-alkogolizm-ufa/https://narkologicheskaya-klinika-ufa9.ru
Когда организм на пределе, важна срочная помощь в Сочи — это команда опытных наркологов, которые помогут быстро и мягко выйти из запоя без вреда для здоровья.
Разобраться лучше – https://narkolog-na-dom-ekaterinburg11.ru/
Затяжной запой представляет собой состояние, при котором организм накапливает токсичные продукты распада алкоголя, нарушается работа сердца, печени и нервной системы. Без своевременного медицинского вмешательства возможны серьёзные осложнения: судороги, алкогольный психоз и острые нарушения гемодинамики. В Красноярске клиника «Красмед» предлагает круглосуточную службу вывода из запоя с применением передовых методик детоксикации и постоянным контролем состояния пациента.
Подробнее можно узнать тут – https://medicinskij-vyvod-iz-zapoya.ru/vyvod-iz-zapoya-na-domu-krasnoyarsk
Клиника «Возрождение» гарантирует:
Подробнее тут – narkologicheskie kliniki alkogolizm ufa
Запой — это не просто несколько дней бесконтрольного употребления алкоголя. Это тяжёлое патологическое состояние, при котором организм человека накапливает токсические продукты распада этанола, теряет жизненно важные электролиты, обезвоживается и выходит из равновесия. На фоне этого нарушается работа сердца, мозга, печени и других систем. Чем дольше длится запой, тем тяжелее последствия и выше риск развития осложнений, вплоть до алкогольного психоза или инсульта. В такой ситуации незаменимым методом экстренной помощи становится капельница от запоя — процедура, позволяющая быстро и безопасно вывести токсины, стабилизировать жизненно важные функции и вернуть человеку контроль над собой.
Получить дополнительные сведения – https://kapelnica-ot-zapoya-moskva3.ru/
Показанием к стационарному лечению служат случаи, при которых домашняя терапия становится небезопасной или недостаточно эффективной. Рекомендуем госпитализацию при:
Получить дополнительные сведения – http://narkologicheskaya-klinika-ufa9.ru/chastnaya-narkologicheskaya-klinika-ufa/
Каждый пациент проходит три основные стадии терапии, начиная с момента первого обращения.
Получить дополнительные сведения – наркологические клиники алкоголизм республика башкортостан
Для максимальной эффективности и безопасности «Красмед» использует комбинированные подходы:
Ознакомиться с деталями – наркологический вывод из запоя красноярск
В Сочи решение есть — наркологическая клиника. Здесь помогают людям выйти из запоя без страха и осуждения. Всё анонимно, грамотно и с заботой о каждом пациенте.
Ознакомиться с деталями – вызов нарколога на дом
Перед началом процедуры врач проводит осмотр: измеряет давление, пульс, уровень кислорода в крови, оценивает тяжесть абстинентного синдрома. В зависимости от результатов и наличия сопутствующих заболеваний составляется индивидуальный состав инфузионного раствора. Он может включать:
Детальнее – http://kapelnica-ot-zapoya-msk55.ru
Затяжной запой опасен для жизни. Врачи наркологической клиники в Сочи проводят срочный вывод из запоя — на дому или в стационаре. Анонимно, безопасно, круглосуточно.
Подробнее – нарколог на дом срочно
Процедура длится от одного до трёх часов. В течение всего времени за пациентом наблюдает медперсонал, проводится мониторинг давления, пульса, общего самочувствия. Уже через 30–60 минут после начала инфузии большинство пациентов ощущают облегчение: снижается тревожность, уходит головная боль, нормализуется дыхание, появляются силы.
Ознакомиться с деталями – капельница от запоя
Наш стационар оснащён всем необходимым для безопасного и комфортного лечения. Здесь вы получите круглосуточный мониторинг, современное оборудование и услуги психологов, социальных педагогов и физиотерапевтов.
Изучить вопрос глубже – http://
Для максимальной эффективности и безопасности «Красмед» использует комбинированные подходы:
Получить больше информации – вывод из запоя на дому круглосуточно красноярск
Близкий человек в запое? Не ждите ухудшения. Обратитесь в клинику Сочи — здесь проведут профессиональный вывод из запоя с последующим восстановлением организма.
Узнать больше – нарколог на дом вывод
кайт анапа Кайтсерфинг в Анапе – это выбор тех, кто ценит активный отдых.
Каждый пациент проходит три основные стадии терапии, начиная с момента первого обращения.
Подробнее – chastnaya narkologicheskaya klinika ufa
Перед началом процедуры врач проводит осмотр: измеряет давление, пульс, уровень кислорода в крови, оценивает тяжесть абстинентного синдрома. В зависимости от результатов и наличия сопутствующих заболеваний составляется индивидуальный состав инфузионного раствора. Он может включать:
Разобраться лучше – kapelnitsy ot zapoia na domu
Затяжной запой опасен для жизни. Врачи наркологической клиники в Сочи проводят срочный вывод из запоя — на дому или в стационаре. Анонимно, безопасно, круглосуточно.
Изучить вопрос глубже – запой нарколог на дом
Эти процедуры направлены на фильтрацию плазмы и избавление крови от токсинов:
Детальнее – vyvod-iz-zapoya-kruglosutochno krasnojarsk
Самостоятельно выйти из запоя — почти невозможно. В Сочи врачи клиники проводят медикаментозный вывод из запоя с круглосуточным выездом. Доверяйте профессионалам.
Подробнее тут – запой нарколог на дом
Rattling clear internet site, thankyou for this post.
Каждый день запоя увеличивает риск для жизни. Не рискуйте — специалисты в Сочи приедут на дом и окажут экстренную помощь. Без боли, стресса и ожидания.
Выяснить больше – нарколог на дом круглосуточно
Эта статья предлагает уникальную подборку занимательных фактов и необычных историй, которые вы, возможно, не знали. Мы постараемся вдохновить ваше воображение и разнообразить ваш кругозор, погружая вас в мир, полный интересных открытий. Читайте и открывайте для себя новое!
Подробнее – https://www.cometov.art/?p=1
В данной обзорной статье представлены интригующие факты, которые не оставят вас равнодушными. Мы критикуем и анализируем события, которые изменили наше восприятие мира. Узнайте, что стоит за новыми открытиями и как они могут изменить ваше восприятие реальности.
Подробнее – http://detsite.com/dva-brata
Каждый день запоя увеличивает риск для жизни. Не рискуйте — специалисты в Сочи приедут на дом и окажут экстренную помощь. Без боли, стресса и ожидания.
Подробнее можно узнать тут – срочный вывод из запоя
Когда организм на пределе, важна срочная помощь в Сочи — это команда опытных наркологов, которые помогут быстро и мягко выйти из запоя без вреда для здоровья.
Углубиться в тему – нарколог на дом вывод
В обзорной статье вы найдете собрание важных фактов и аналитики по самым разнообразным темам. Мы рассматриваем как современные исследования, так и исторические контексты, чтобы вы могли получить полное представление о предмете. Погрузитесь в мир знаний и сделайте шаг к пониманию!
Узнать больше – https://statuscaptions.com/iob-balance-check-number-check-them-here.html
Эта статья для ознакомления предлагает читателям общее представление об актуальной теме. Мы стремимся представить ключевые факты и идеи, которые помогут читателям получить представление о предмете и решить, стоит ли углубляться в изучение.
Детальнее – https://ms-kobo.jp/blog/2014/07/27/ms%E5%B7%A5%E6%88%BF%E3%81%8C%E8%A1%8C%E3%81%8F%E8%A1%97%E8%A7%92%EF%BC%92
Эта разъяснительная статья содержит простые и доступные разъяснения по актуальным вопросам. Мы стремимся сделать информацию понятной для широкой аудитории, чтобы каждый смог разобраться в предмете и извлечь из него максимум пользы.
Получить дополнительные сведения – http://samanthaseara.com/info-nitrites
В этой статье представлен занимательный и актуальный контент, который заставит вас задуматься. Мы обсуждаем насущные вопросы и проблемы, а также освещаем истории, которые вдохновляют на действия и изменения. Узнайте, что стоит за событиями нашего времени!
Узнать больше – https://evolutionmarketing.co.in/in-the-first-place-posted-of-the-ykimber-better
В этом информативном обзоре собраны самые интересные статистические данные и факты, которые помогут лучше понять текущие тренды. Мы представим вам цифры и графики, которые иллюстрируют, как развиваются различные сферы жизни. Эта информация станет отличной основой для глубокого анализа и принятия обоснованных решений.
Получить больше информации – https://sci.oouagoiwoye.edu.ng/2018/05/24/dr-folorunso-sakinat-oluwabukonla
Эта познавательная публикация погружает вас в море интересного контента, который быстро захватит ваше внимание. Мы рассмотрим важные аспекты темы и предоставим вам уникальныеInsights и полезные сведения для дальнейшего изучения.
Исследовать вопрос подробнее – https://szostaksmb.pl/cropped-logo_szostak-png
Эта статья предлагает захватывающий и полезный контент, который привлечет внимание широкого круга читателей. Мы постараемся представить тебе идеи, которые вдохновят вас на изменения в жизни и предоставят практические решения для повседневных вопросов. Читайте и вдохновляйтесь!
Исследовать вопрос подробнее – http://www.anterohein.com/dsc00911
Эта обзорная заметка содержит ключевые моменты и факты по актуальным вопросам. Она поможет читателям быстро ориентироваться в теме и узнать о самых важных аспектах сегодня. Получите краткий курс по современной информации и оставайтесь в курсе событий!
Разобраться лучше – https://andsinfo.com.br/index.php/2022/11/16/ola-mundo
Этот информативный материал предлагает содержательную информацию по множеству задач и вопросов. Мы призываем вас исследовать различные идеи и факты, обобщая их для более глубокого понимания. Наша цель — сделать обучение доступным и увлекательным.
Ознакомиться с деталями – https://www.ibizasoulluxuryvillas.com/bookings/booking-request-306
Professional concrete driveway contractors in seattle — high-quality installation, durable materials and strict adherence to deadlines. We work under a contract, provide a guarantee, and visit the site. Your reliable choice in Seattle.
Эта статья сочетает в себе как полезные, так и интересные сведения, которые обогатят ваше понимание насущных тем. Мы предлагаем практические советы и рекомендации, которые легко внедрить в повседневную жизнь. Узнайте, как улучшить свои навыки и обогатить свой опыт с помощью простых, но эффективных решений.
Получить дополнительные сведения – http://crm.czest.pl/index.php/2014/09/13/ustawa-o-prawach-konsumenta
Professional Seattle power washing — effective cleaning of facades, sidewalks, driveways and other surfaces. Modern equipment, affordable prices, travel throughout Seattle. Cleanliness that is visible at first glance.
Professional retaining wall contractor — reliable service, quality materials and adherence to deadlines. Individual approach, experienced team, free estimate. Your project — turnkey with a guarantee.
Эта статья для ознакомления предлагает читателям общее представление об актуальной теме. Мы стремимся представить ключевые факты и идеи, которые помогут читателям получить представление о предмете и решить, стоит ли углубляться в изучение.
Детальнее – http://www.taxi-bateau-bassindarcachon.com/olympus-digital-camera-36
I appreciate, cause I found exactly what I was looking for. You’ve ended my four day long hunt! God Bless you man. Have a nice day. Bye
I don?t even know how I ended up here, but I thought this post was good. I do not know who you are but certainly you are going to a famous blogger if you are not already 😉 Cheers!
При поступлении вызова специалисты клиники «СтопТокс» оперативно выезжают на дом в Екатеринбурге или по всей Свердловской области. По прибытии врач проводит всестороннюю диагностику, включая измерение артериального давления, пульса и уровня кислорода в крови, а также собирает анамнез и оценивает степень интоксикации. На основе полученной информации составляется индивидуальный план лечения, который включает следующие этапы:
Детальнее – https://narcolog-na-dom-ekaterinburg000.ru/narkolog-na-dom-czena-ekb
Затяжной запой представляет собой состояние, при котором организм накапливает токсичные продукты распада алкоголя, нарушается работа сердца, печени и нервной системы. Без своевременного медицинского вмешательства возможны серьёзные осложнения: судороги, алкогольный психоз и острые нарушения гемодинамики. В Красноярске клиника «Красмед» предлагает круглосуточную службу вывода из запоя с применением передовых методик детоксикации и постоянным контролем состояния пациента.
Подробнее тут – вывод из запоя на дому цена в красноярске
Каждый день запоя увеличивает риск для жизни. Не рискуйте — специалисты в Сочи приедут на дом и окажут экстренную помощь. Без боли, стресса и ожидания.
Изучить вопрос глубже – нарколог на дом круглосуточно
Серьезные состояния, вызванные длительным употреблением алкоголя или наркотиков, требуют немедленного вмешательства. Если пациент испытывает ухудшение самочувствия вследствие продолжительного запоя, его организм начинает накапливать токсичные вещества, что ведёт к нарушению работы внутренних органов. При появлении таких симптомов, как сильная рвота, спутанность сознания, судороги, резкие скачки артериального давления, а также выраженные признаки абстинентного синдрома (сильная дрожь, панические атаки, бессонница, тревожность), вызов нарколога становится жизненно необходимым. Экстренное вмешательство позволяет стабилизировать состояние больного и предотвратить развитие серьёзных осложнений, включая сердечно-сосудистые нарушения, повреждение печени и развитие алкогольного психоза. В таких ситуациях профессиональное лечение на дому — лучший способ сохранить здоровье и жизнь пациента.
Разобраться лучше – http://narcolog-na-dom-ekaterinburg000.ru
Эти процедуры направлены на фильтрацию плазмы и избавление крови от токсинов:
Углубиться в тему – вывод из запоя круглосуточно в красноярске
Базовый метод, сочетающий регидратацию, электролитную коррекцию и витаминные комплексы:
Подробнее тут – вывод из запоя цена красноярск
Функция и назначение
Подробнее можно узнать тут – нарколог на дом цена екатеринбург
Инфузионная терапия проходит под непрерывным контролем врача и медсестры: каждые 15–20 минут измеряются АД, пульс и сатурация, при возникновении любых нежелательных реакций раствор корректируется. Стандартная продолжительность курса — от одного до трёх часов, но может быть продлена в зависимости от индивидуальных показателей. Уже после первого часа инфузии пациенты отмечают исчезновение головной боли, нормализацию сна, улучшение аппетита и выраженное эмоциональное облегчение.
Подробнее можно узнать тут – https://kapelnica-ot-zapoya-moskva1.ru/kapelnicy-ot-zapoya-na-domu-v-balashihe
Need transportation? vehicle shipping company car transportation company services — from one car to large lots. Delivery to new owners, between cities. Safety, accuracy, licenses and experience over 10 years.
Капельница от запоя необходима, если у пациента наблюдаются следующие симптомы:
Выяснить больше – капельница от запоя одинцово
Нужна камера? wi fi камера видеонаблюдения для дома, офиса и улицы. Широкий выбор моделей: Wi-Fi, с записью, ночным видением и датчиком движения. Гарантия, быстрая доставка, помощь в подборе и установке.
Когда организм на пределе, важна срочная помощь в Сочи — это команда опытных наркологов, которые помогут быстро и мягко выйти из запоя без вреда для здоровья.
Получить дополнительные сведения – врач нарколог на дом
Запой — это не просто усиленное похмелье, а критическое состояние алкогольной интоксикации, при котором организм оказывается неспособным самостоятельно вывести накопившиеся токсины. При затяжном приёме алкоголя страдает не только печень — нарушаются функции сердечно-сосудистой системы, тормозятся нейрохимические процессы в головном мозге, развивается выраженная дегидратация и электролитный дисбаланс. Первая помощь в такой ситуации — экстренная инфузионная терапия, которую мы проводим в наркологической клинике «Источник Здоровья» в Балашихе.
Получить дополнительные сведения – капельницы от запоя на дому
После купирования острой фазы мы предлагаем полное сопровождение на этапе восстановления, чтобы закрепить результаты и снизить риск повторных срывов. В первые дни показаны сеансы кислородной терапии, которые активизируют клеточный обмен и способствуют быстрейшему выведению остатков токсинов. Параллельно проводятся физиотерапевтические процедуры — магнитотерапия и лазерная стимуляция, укрепляющие сосудистую стенку и ускоряющие заживление микроциркуляторных нарушений.
Подробнее можно узнать тут – вызвать капельницу от запоя балашиха
Самостоятельно выйти из запоя — почти невозможно. В Сочи врачи клиники проводят медикаментозный вывод из запоя с круглосуточным выездом. Доверяйте профессионалам.
Изучить вопрос глубже – вызов нарколога на дом
Перед началом процедуры врач проводит осмотр: измеряет давление, пульс, уровень кислорода в крови, оценивает тяжесть абстинентного синдрома. В зависимости от результатов и наличия сопутствующих заболеваний составляется индивидуальный состав инфузионного раствора. Он может включать:
Разобраться лучше – http://www.domen.ru
Близкий человек в запое? Не ждите ухудшения. Обратитесь в клинику Сочи — здесь проведут профессиональный вывод из запоя с последующим восстановлением организма.
Получить больше информации – вывод из запоя в стационаре
Инфузия проводится под постоянным контролем медицинского персонала. Длительность процедуры составляет от одного до трёх часов. Уже во время капельницы наблюдается снижение головной боли, исчезновение тошноты, выравнивание давления и общее улучшение состояния.
Получить больше информации – kapelnica-ot-zapoya-msk55.ru/
В «Сибирском Докторе» работают врачи с многолетним стажем и профильным образованием:
Углубиться в тему – narkolog-vyvod-iz-zapoya novosibirsk
I was just looking for this info for some time. After six hours of continuous Googleing, at last I got it in your site. I wonder what’s the lack of Google strategy that do not rank this type of informative sites in top of the list. Generally the top web sites are full of garbage.
I have seen lots of useful items on your site about pc’s. However, I have the opinion that laptops are still not quite powerful adequately to be a option if you often do jobs that require lots of power, like video editing and enhancing. But for website surfing, word processing, and most other frequent computer work they are all right, provided you do not mind small screen size. Appreciate sharing your opinions.
Когда организм на пределе, важна срочная помощь в Сочи — это команда опытных наркологов, которые помогут быстро и мягко выйти из запоя без вреда для здоровья.
Углубиться в тему – врач нарколог на дом
Близкий человек в запое? Не ждите ухудшения. Обратитесь в клинику Сочи — здесь проведут профессиональный вывод из запоя с последующим восстановлением организма.
Разобраться лучше – нарколог на дом анонимно
Обращение за медицинской помощью становится необходимым, когда пациент пребывает в состоянии, требующем немедленного вмешательства, так как самостоятельное лечение может только усугубить ситуацию. Это происходит, если запой продолжается несколько дней, и организм не успевает справляться с накопившимися токсинами, что ведёт к нарушению работы внутренних органов. Если у пациента регулярно наблюдаются симптомы, такие как частая рвота, сильное головокружение, спутанность сознания, судороги или резкие колебания артериального давления, это является явным сигналом к вызову специалиста. Особенно важно обращаться за помощью при выраженных признаках абстинентного синдрома, когда сильная дрожь, панические атаки, бессонница, тревожность и даже галлюцинации свидетельствуют о том, что организм испытывает критическую нехватку поддержки. Наличие психических нарушений, таких как агрессивное поведение, спутанность сознания или признаки алкогольного психоза, также требует незамедлительного вмешательства. В таких ситуациях обращение за профессиональной помощью помогает быстро стабилизировать состояние пациента, предотвратить развитие тяжелых осложнений и сохранить жизнь.
Подробнее – https://narcolog-na-dom-ekaterinburg00.ru/zapoj-narkolog-na-dom-ekb
Инфузии выполняются с помощью автоматизированных насосов, позволяющих скорректировать скорость введения в зависимости от показателей безопасности.
Получить дополнительную информацию – вывод из запоя капельница в красноярске
Эта информационная заметка предлагает лаконичное и четкое освещение актуальных вопросов. Здесь вы найдете ключевые факты и основную информацию по теме, которые помогут вам сформировать собственное мнение и повысить уровень осведомленности.
Ознакомиться с деталями – https://nilevalley.edu.sd/teach/?portfolio=hero-gadget
Каждый день запоя увеличивает риск для жизни. Не рискуйте — специалисты в Сочи приедут на дом и окажут экстренную помощь. Без боли, стресса и ожидания.
Получить дополнительную информацию – екатеринбург.
Клиника «Красмед» специализируется на экстренной и плановой наркологической помощи более десяти лет. В арсенале клиники:
Разобраться лучше – вывод из запоя цена
Эта публикация завернет вас в вихрь увлекательного контента, сбрасывая стереотипы и открывая двери к новым идеям. Каждый абзац станет для вас открытием, полным ярких примеров и впечатляющих достижений. Подготовьтесь быть вовлеченными и удивленными каждый раз, когда продолжите читать.
Выяснить больше – http://ukr-novyny-ua.ru/amerikanski-vijskovi-vidkrili-centr-nanotexnologij/.html
Эта обзорная заметка содержит ключевые моменты и факты по актуальным вопросам. Она поможет читателям быстро ориентироваться в теме и узнать о самых важных аспектах сегодня. Получите краткий курс по современной информации и оставайтесь в курсе событий!
Подробнее – https://vanproosdijenvandebunt.nl/2022/04/19/3-simple-tips-for-using-pink
Эта статья предлагает живое освещение актуальной темы с множеством интересных фактов. Мы рассмотрим ключевые моменты, которые делают данную тему важной и актуальной. Подготовьтесь к насыщенному путешествию по неизвестным аспектам и узнайте больше о значимых событиях.
Получить больше информации – https://riseas-basketball.com/if-yuta-wokrout-with-you
В этой статье представлен занимательный и актуальный контент, который заставит вас задуматься. Мы обсуждаем насущные вопросы и проблемы, а также освещаем истории, которые вдохновляют на действия и изменения. Узнайте, что стоит за событиями нашего времени!
Разобраться лучше – https://prime.itxoft.com/seo-white-hat-techniques-itxoft-13886
auto car transport ship car from california to texas
Hi! Someone in my Facebook group shared this site with us so I came to look it over. I’m definitely loving the information. I’m bookmarking and will be tweeting this to my followers! Terrific blog and fantastic design and style.
Wow! This can be one particular of the most beneficial blogs We’ve ever arrive across on this subject. Actually Great. I am also an expert in this topic therefore I can understand your hard work.
Для детоксикации и восстановления организма после запоя используются только сертифицированные лекарственные препараты с доказанной эффективностью и безопасностью:
Подробнее можно узнать тут – нарколог на дом круглосуточно
Вызов нарколога на дом становится необходимым при любых состояниях, когда отказ от алкоголя сопровождается выраженными симптомами интоксикации и абстиненции. Основные ситуации, в которых срочно требуется профессиональная помощь врача:
Углубиться в тему – https://narcolog-na-dom-sochi0.ru/narkolog-na-dom-czena-sochi/
Длительный запой представляет собой крайне опасное состояние, способное нанести непоправимый вред организму. При отсутствии своевременного вмешательства алкогольная интоксикация может привести к серьезным осложнениям, таким как нарушение работы сердца, печени, почек и нервной системы, а также развитию алкогольного психоза. В таких ситуациях экстренная медицинская помощь является залогом спасения жизни и предотвращения необратимых последствий. Клиника «ЗдоровьеНорм» предлагает круглосуточный выезд специалистов для вывода из запоя на дому в Краснодаре и по всему Краснодарскому краю. Наши врачи работают 24 часа в сутки, обеспечивая полный комплекс процедур по детоксикации, снятию абстинентного синдрома и восстановлению организма, при этом гарантируя полную анонимность и индивидуальный подход к каждому пациенту.
Исследовать вопрос подробнее – https://narcolog-na-dom-krasnodar0.ru/narkolog-na-dom-kruglosutochno-krasnodar
При длительном запое или серьезной алкогольной интоксикации часто нет возможности или желания ехать в стационар. В таких ситуациях оптимальным решением становится вызов нарколога на дом в Сочи. Специалисты клиники «Жизнь без Запоя» круглосуточно приезжают к пациентам, оперативно оказывают медицинскую помощь и проводят профессиональную детоксикацию организма прямо в домашних условиях. Благодаря комфортному лечению на дому пациенты быстрее восстанавливаются, избегают дополнительного стресса и осложнений, связанных с госпитализацией.
Выяснить больше – вызов врача нарколога на дом
Когда организм на пределе, важна срочная помощь в Сочи — это команда опытных наркологов, которые помогут быстро и мягко выйти из запоя без вреда для здоровья.
Изучить вопрос глубже – вызвать нарколога на дом
Чем дольше человек находится в состоянии запоя, тем больше накапливаются токсины в организме, что негативно сказывается на всех системах. Отказ от алкоголя без должного контроля может привести к серьезным последствиям, таким как:
Подробнее – нарколог на дом срочно краснодар
Инфузия проводится под постоянным контролем медицинского персонала. Длительность процедуры составляет от одного до трёх часов. Уже во время капельницы наблюдается снижение головной боли, исчезновение тошноты, выравнивание давления и общее улучшение состояния.
Получить дополнительную информацию – https://kapelnica-ot-zapoya-msk55.ru/
Чем дольше человек находится в состоянии запоя, тем больше накапливаются токсины в организме, что негативно сказывается на всех системах. Отказ от алкоголя без должного контроля может привести к серьезным последствиям, таким как:
Получить дополнительные сведения – вызвать нарколога на дом
Алкогольная интоксикация разрушает организм изнутри. В первую очередь страдает центральная нервная система: снижается уровень витаминов группы B, нарушаются когнитивные функции, появляются раздражительность, бессонница, панические атаки. Следом — страдает печень, главный орган метаболической детоксикации. Под действием этанола её функции подавляются, а токсины накапливаются в крови. Это вызывает системное отравление и разрушает внутренние органы.
Получить больше информации – капельница от запоя цена
Затяжной запой опасен для жизни. Врачи наркологической клиники в Сочи проводят срочный вывод из запоя — на дому или в стационаре. Анонимно, безопасно, круглосуточно.
Углубиться в тему – narkolog-na-dom
Инфузия проводится под постоянным контролем медицинского персонала. Длительность процедуры составляет от одного до трёх часов. Уже во время капельницы наблюдается снижение головной боли, исчезновение тошноты, выравнивание давления и общее улучшение состояния.
Подробнее – vyzvat kapelnitsu ot zapoia
Самостоятельно выйти из запоя — почти невозможно. В Сочи врачи клиники проводят медикаментозный вывод из запоя с круглосуточным выездом. Доверяйте профессионалам.
Разобраться лучше – врач нарколог на дом
В Сочи решение есть — наркологическая клиника. Здесь помогают людям выйти из запоя без страха и осуждения. Всё анонимно, грамотно и с заботой о каждом пациенте.
Получить больше информации – вывод из запоя на дому
В Сочи решение есть — наркологическая клиника. Здесь помогают людям выйти из запоя без страха и осуждения. Всё анонимно, грамотно и с заботой о каждом пациенте.
Подробнее – vrach-narkolog-na-dom
Каждый день запоя увеличивает риск для жизни. Не рискуйте — специалисты в Сочи приедут на дом и окажут экстренную помощь. Без боли, стресса и ожидания.
Разобраться лучше – нарколог на дом срочно
Balloons Dubai https://balloons-dubai1.com stunning balloon decorations for birthdays, weddings, baby showers, and corporate events. Custom designs, same-day delivery, premium quality.
Близкий человек в запое? Не ждите ухудшения. Обратитесь в клинику Сочи — здесь проведут профессиональный вывод из запоя с последующим восстановлением организма.
Углубиться в тему – нарколог на дом вывод
Запой — это не просто несколько дней бесконтрольного употребления алкоголя. Это тяжёлое патологическое состояние, при котором организм человека накапливает токсические продукты распада этанола, теряет жизненно важные электролиты, обезвоживается и выходит из равновесия. На фоне этого нарушается работа сердца, мозга, печени и других систем. Чем дольше длится запой, тем тяжелее последствия и выше риск развития осложнений, вплоть до алкогольного психоза или инсульта. В такой ситуации незаменимым методом экстренной помощи становится капельница от запоя — процедура, позволяющая быстро и безопасно вывести токсины, стабилизировать жизненно важные функции и вернуть человеку контроль над собой.
Исследовать вопрос подробнее – http://kapelnica-ot-zapoya-moskva3.ru
I have been absent for a while, but now I remember why I used to love this site. Thank you, I?ll try and check back more frequently. How frequently you update your website?
Great post. I was checking continuously this weblog and I’m inspired! Very helpful information specially the ultimate section 🙂 I maintain such information much. I was seeking this certain information for a very long time. Thanks and best of luck.
Для безопасного и эффективного лечения наши специалисты используют только проверенные и сертифицированные медикаменты, подбираемые индивидуально с учетом состояния пациента. В состав капельницы входят следующие группы препаратов:
Изучить вопрос глубже – https://narcolog-na-dom-krasnodar0.ru/narkolog-na-dom-kruglosutochno-krasnodar
Для безопасного и эффективного лечения наши специалисты используют только проверенные и сертифицированные медикаменты, подбираемые индивидуально с учетом состояния пациента. В состав капельницы входят следующие группы препаратов:
Получить больше информации – narkolog-na-dom-kruglosutochno krasnodar
Вызов нарколога на дом становится необходимым при любых состояниях, когда отказ от алкоголя сопровождается выраженными симптомами интоксикации и абстиненции. Основные ситуации, в которых срочно требуется профессиональная помощь врача:
Разобраться лучше – нарколог на дом цена в сочи
Процедура длится от 40 минут до 2 часов, в зависимости от тяжести состояния, и проводится в комфортной домашней обстановке, что значительно снижает стресс у пациента и его близких.
Детальнее – http://narcolog-na-dom-krasnodar0.ru/narkolog-na-dom-czena-krasnodar/
Для безопасного и эффективного лечения наши специалисты используют только проверенные и сертифицированные медикаменты, подбираемые индивидуально с учетом состояния пациента. В состав капельницы входят следующие группы препаратов:
Разобраться лучше – vrach-narkolog-na-dom krasnodar
Процедура начинается с врачебного осмотра. Специалист оценивает общее состояние, артериальное давление, пульс, сатурацию, уровень обезвоживания, жалобы пациента. При необходимости проводятся экспресс-анализы. Далее индивидуально подбирается состав инфузионной терапии. В большинстве случаев капельница включает:
Получить больше информации – стоимость капельницы от запоя
Капельница от запоя необходима, если у пациента наблюдаются следующие симптомы:
Получить дополнительные сведения – vrach na dom kapelnitsa ot zapoia odintsovo
Этот увлекательный информационный материал подарит вам массу новых знаний и ярких эмоций. Мы собрали для вас интересные факты и сведения, которые обогатят ваш опыт. Откройте для себя увлекательный мир информации и насладитесь процессом изучения!
Получить дополнительные сведения – https://www.levesolls.com/woocommerce-placeholder
Эта обзорная заметка содержит ключевые моменты и факты по актуальным вопросам. Она поможет читателям быстро ориентироваться в теме и узнать о самых важных аспектах сегодня. Получите краткий курс по современной информации и оставайтесь в курсе событий!
Подробнее тут – https://masdarvieux.fr/un-mariage-colore-au-mas-darvieux-en-provence-2
Эта обзорная заметка содержит ключевые моменты и факты по актуальным вопросам. Она поможет читателям быстро ориентироваться в теме и узнать о самых важных аспектах сегодня. Получите краткий курс по современной информации и оставайтесь в курсе событий!
Подробнее тут – http://www.angarsk-goradm.ru/news/2014/10/7
Выезд врача-нарколога из клиники «ТрезвоПрофи» на дом происходит в любое время суток, включая выходные и праздники. Перед началом детоксикации врач проводит осмотр, измеряет давление, частоту пульса, уровень кислорода в крови и подбирает индивидуальную схему лечения. Сама процедура обычно занимает от 1 до 2 часов и проводится под строгим контролем врача.
Подробнее тут – капельница от запоя выезд сочи
Чем раньше будет проведена процедура детоксикации, тем выше шансы избежать осложнений и быстрее восстановить здоровье пациента. Врачи клиники «ТрезвоПрофи» оперативно реагируют на вызовы, выезжая в любой район Сочи и прилегающие населенные пункты.
Получить больше информации – вызвать капельницу от запоя на дому сочи
Выезд врача-нарколога из клиники «ТрезвоПрофи» на дом происходит в любое время суток, включая выходные и праздники. Перед началом детоксикации врач проводит осмотр, измеряет давление, частоту пульса, уровень кислорода в крови и подбирает индивидуальную схему лечения. Сама процедура обычно занимает от 1 до 2 часов и проводится под строгим контролем врача.
Углубиться в тему – https://kapelnica-ot-zapoya-sochi00.ru/kapelnicza-ot-zapoya-czena-sochi/
горшки дизайнерские купить https://dizaynerskie-kashpo.ru/ .
Выезд врача-нарколога из клиники «ТрезвоПрофи» на дом происходит в любое время суток, включая выходные и праздники. Перед началом детоксикации врач проводит осмотр, измеряет давление, частоту пульса, уровень кислорода в крови и подбирает индивидуальную схему лечения. Сама процедура обычно занимает от 1 до 2 часов и проводится под строгим контролем врача.
Выяснить больше – http://kapelnica-ot-zapoya-sochi00.ru
It?s really a nice and helpful piece of information. I am glad that you shared this useful info with us. Please keep us up to date like this. Thanks for sharing.
This is very interesting, You’re a very skilled blogger. I’ve joined your feed and look forward to seeking more of your excellent post. Also, I’ve shared your site in my social networks!
Экстренная установка капельницы необходима, если пациент находится в состоянии запоя более 2–3 дней или испытывает симптомы тяжелой интоксикации алкоголем:
Углубиться в тему – kapelnicza-ot-zapoya-czena sochi
Психологическая реабилитация: Психологическая поддержка – один из главных аспектов нашего подхода. Мы предлагаем индивидуальные и групповые занятия, помогающие осознать зависимость, проработать эмоциональные травмы и сформировать новые модели поведения. Опытные психологи помогают пациентам понять причины своих зависимостей, что является важным шагом на пути к выздоровлению.
Исследовать вопрос подробнее – http://srochnyj-vyvod-iz-zapoya.ru
Перед тем как перейти к описанию методов и стоимости, важно определить основные показания для кодирования. Ниже перечислены ключевые признаки, при наличии которых кодирование рекомендуется как этап комплексного лечения:
Ознакомиться с деталями – https://kodirovanie-ot-alkogolizma-odintsovo2.ru/
Таким образом, наш подход направлен на создание комплексной системы поддержки, которая помогает каждому пациенту справиться с зависимостью и вернуться к полноценной жизни.
Подробнее можно узнать тут – https://srochnyj-vyvod-iz-zapoya.ru/vyvod-iz-zapoya-na-domu-v-kazani.ru
Психологическая реабилитация: Психологическая поддержка – один из главных аспектов нашего подхода. Мы предлагаем индивидуальные и групповые занятия, помогающие осознать зависимость, проработать эмоциональные травмы и сформировать новые модели поведения. Опытные психологи помогают пациентам понять причины своих зависимостей, что является важным шагом на пути к выздоровлению.
Выяснить больше – срочный вывод из запоя казань
Медикаментозное кодирование проводится с помощью препаратов, блокирующих ферменты, ответственные за расщепление этанола, что вызывает выраженное неприятие алкоголя при попытке его употребления. Препараты вводятся внутримышечно или с помощью подкожных имплантов и действуют в течение нескольких месяцев, обеспечивая длительный эффект.
Узнать больше – centr kodirovaniya ot alkogolizma
Перед тем как перейти к описанию методов и стоимости, важно определить основные показания для кодирования. Ниже перечислены ключевые признаки, при наличии которых кодирование рекомендуется как этап комплексного лечения:
Узнать больше – https://kodirovanie-ot-alkogolizma-odintsovo2.ru/kodirovanie-ot-alkogolizma-cena/
стоимость плитки для пола керамогранитная плитка 1200х600
В клинике «Горизонт Жизни» в Красногорске разработаны протоколы экстренного вывода из запоя, которые выполняются 24 часа в сутки, семь дней в неделю. Благодаря выезду бригады врачей-наркологов и оснащённости современным оборудованием мы оказываем помощь в кратчайшие сроки, обеспечивая максимальную безопасность и комфорт пациенту.
Ознакомиться с деталями – вывод из запоя капельница на дому
В клинике «Нарколог-Профи» используются только проверенные и сертифицированные медикаменты, подбираемые индивидуально для каждого пациента. Ниже представлена таблица с основными группами препаратов и их функциями:
Подробнее можно узнать тут – нарколог на дом вывод
Медикаментозное лечение: Мы применяем современные препараты, которые помогают облегчить симптомы абстиненции и улучшить состояние пациентов в первые дни лечения. Индивидуальный подбор лекарственных схем позволяет минимизировать побочные эффекты и достичь наилучших результатов.
Получить дополнительные сведения – вывод из запоя круглосуточно в казани
«В первые часы после окончания запоя организм наиболее уязвим, и своевременное вмешательство значительно снижает риски осложнений», — подчёркивает заведующая отделением наркологической реанимации Елена Морозова.
Получить дополнительные сведения – врач вывод из запоя
Срочное вмешательство врача необходимо при появлении следующих симптомов:
Получить больше информации – https://vyvod-iz-zapoya-korolev2.ru/
Алкогольный запой — это острое состояние тяжёлой интоксикации, при котором организм накапливает критические уровни продуктов распада этанола и перестаёт справляться с их нейтрализацией. При этом страдают важнейшие органы и системы: печень, почки, сердце, центральная нервная система. Без квалифицированной медицинской помощи риск развития судорог, алкогольного делирия и полиорганной недостаточности возрастает многократно.
Углубиться в тему – http://vyvod-iz-zapoya-krasnogorsk2.ru
Перед тем как перейти к описанию методов и стоимости, важно определить основные показания для кодирования. Ниже перечислены ключевые признаки, при наличии которых кодирование рекомендуется как этап комплексного лечения:
Выяснить больше – центр кодирования от алкоголизма
«Кодирование — это не магическое решение, а важный этап в комплексной программе лечения, — поясняет ведущий нарколог клиники «Ясное Будущее» Марина Иванова. — Главное — сочетание фармакологического воздействия и последующей работы с психологом для формирования устойчивой мотивации к трезвости».
Подробнее – klinika kodirovaniya ot alkogolizma
Профессиональное https://kosmetologicheskoe-oborudovanie-msk.ru для салонов красоты, клиник и частных мастеров. Аппараты для чистки, омоложения, лазерной эпиляции, лифтинга и ухода за кожей.
«Кодирование — это не магическое решение, а важный этап в комплексной программе лечения, — поясняет ведущий нарколог клиники «Ясное Будущее» Марина Иванова. — Главное — сочетание фармакологического воздействия и последующей работы с психологом для формирования устойчивой мотивации к трезвости».
Разобраться лучше – http://kodirovanie-ot-alkogolizma-odintsovo2.ru/kodirovanie-ot-alkogolizma-cena/
I don?t even know how I finished up right here, however I believed this put up was great. I do not recognize who you’re but definitely you are going to a well-known blogger in case you aren’t already 😉 Cheers!
Pretty part of content. I simply stumbled upon your website and in accession capital to say that I acquire in fact enjoyed account your weblog posts. Any way I will be subscribing in your augment and even I fulfillment you get entry to consistently rapidly.
ultimate createporn generator. Create hentai art, porn comics, and NSFW with the best AI porn maker online. Start generating AI porn now!
сколько консультация юриста https://besplatnaya-yuridicheskaya-konsultaciya-moskva-po-telefonu.ru
ultimate AI porn maker generator. Create hentai art, porn comics, and NSFW with the best AI porn maker online. Start generating AI porn now!
Перед тем как перейти к описанию методов и стоимости, важно определить основные показания для кодирования. Ниже перечислены ключевые признаки, при наличии которых кодирование рекомендуется как этап комплексного лечения:
Ознакомиться с деталями – kodirovanie-ot-alkogolizma-odintsovo2.ru/
Аппаратные методы кодирования включают лазерную терапию и электростимуляцию биологически активных точек, влияющих на центры зависимости в головном мозге. Эти методики способствуют быстрому формированию устойчивого отвращения к спиртному и хорошо переносятся пациентами.
Подробнее можно узнать тут – kodirovanie ot alkogolizma ceny
Алкогольная зависимость — это хроническое заболевание, при котором устойчивое влечение к спиртному приводит к тяжёлым медицинским, социальным и психологическим последствиям. Когда пациент осознаёт, что самостоятельно справиться с этой проблемой не получается, наиболее эффективным методом становится кодирование от алкоголизма. В клинике «Ясное Будущее» в Одинцово мы используем сочетание проверенных методик кодирования и комплексной психологической поддержки, что позволяет достичь стойкой ремиссии и вернуть человеку контроль над собственной жизнью.
Подробнее тут – https://kodirovanie-ot-alkogolizma-odintsovo2.ru/kodirovanie-ot-alkogolizma-cena
Алкогольный запой — это острое состояние тяжёлой интоксикации, при котором организм накапливает критические уровни продуктов распада этанола и перестаёт справляться с их нейтрализацией. При этом страдают важнейшие органы и системы: печень, почки, сердце, центральная нервная система. Без квалифицированной медицинской помощи риск развития судорог, алкогольного делирия и полиорганной недостаточности возрастает многократно.
Детальнее – vyvod iz zapoya na domu
Алкогольная зависимость — это хроническое заболевание, при котором устойчивое влечение к спиртному приводит к тяжёлым медицинским, социальным и психологическим последствиям. Когда пациент осознаёт, что самостоятельно справиться с этой проблемой не получается, наиболее эффективным методом становится кодирование от алкоголизма. В клинике «Ясное Будущее» в Одинцово мы используем сочетание проверенных методик кодирования и комплексной психологической поддержки, что позволяет достичь стойкой ремиссии и вернуть человеку контроль над собственной жизнью.
Ознакомиться с деталями – кодирование от алкоголизма цены
«В первые часы после окончания запоя организм наиболее уязвим, и своевременное вмешательство значительно снижает риски осложнений», — подчёркивает заведующая отделением наркологической реанимации Елена Морозова.
Подробнее тут – vyvod iz zapoya
В нашей клинике применяются различные техники кодирования, которые подбираются с учётом медицинских показаний, психологического состояния и пожеланий пациента.
Подробнее можно узнать тут – kodirovanie ot alkogolizma dovzhenko
Медикаментозное кодирование проводится с помощью препаратов, блокирующих ферменты, ответственные за расщепление этанола, что вызывает выраженное неприятие алкоголя при попытке его употребления. Препараты вводятся внутримышечно или с помощью подкожных имплантов и действуют в течение нескольких месяцев, обеспечивая длительный эффект.
Узнать больше – http://kodirovanie-ot-alkogolizma-odintsovo2.ru/
Алкогольная зависимость — это хроническое заболевание, при котором устойчивое влечение к спиртному приводит к тяжёлым медицинским, социальным и психологическим последствиям. Когда пациент осознаёт, что самостоятельно справиться с этой проблемой не получается, наиболее эффективным методом становится кодирование от алкоголизма. В клинике «Ясное Будущее» в Одинцово мы используем сочетание проверенных методик кодирования и комплексной психологической поддержки, что позволяет достичь стойкой ремиссии и вернуть человеку контроль над собственной жизнью.
Получить больше информации – https://kodirovanie-ot-alkogolizma-odintsovo2.ru/kodirovanie-ot-alkogolizma-cena/
В «Горизонте Жизни» доступны два основных формата экстренной помощи: выездная служба на дому и лечение в условиях стационара.
Получить больше информации – https://vyvod-iz-zapoya-krasnogorsk2.ru/vyvod-iz-zapoya-cena/
Кодирование создаёт стойкое отвращение к этилированному спирту за счёт фармакологического или психотерапевтического воздействия, а дальнейшая работа с психологом помогает сформировать новую модель поведения и мотивацию к сохранению трезвости. Современные технологии в сочетании с индивидуальным подходом делают процедуру безопасной и максимально комфортной для пациента.
Узнать больше – http://kodirovanie-ot-alkogolizma-odintsovo2.ru
Алкогольный запой — это острое состояние тяжёлой интоксикации, при котором организм накапливает критические уровни продуктов распада этанола и перестаёт справляться с их нейтрализацией. При этом страдают важнейшие органы и системы: печень, почки, сердце, центральная нервная система. Без квалифицированной медицинской помощи риск развития судорог, алкогольного делирия и полиорганной недостаточности возрастает многократно.
Получить дополнительные сведения – вывод из запоя на дому
Thanks for the recommendations on credit repair on this particular site. A few things i would advice people is usually to give up this mentality they can buy at this point and pay out later. Like a society we tend to do this for many factors. This includes trips, furniture, and items we really want to have. However, you’ll want to separate your own wants from the needs. When you’re working to raise your credit ranking score actually you need some sacrifices. For example you’ll be able to shop online to economize or you can look at second hand stores instead of highly-priced department stores intended for clothing.
F*ckin? awesome things here. I?m very glad to see your article. Thanks a lot and i’m looking forward to contact you. Will you please drop me a mail?
Pretty section of content. I just stumbled upon your web site and in accession capital to assert that I get actually enjoyed account your weblog posts. Anyway I will be subscribing to your augment or even I achievement you get admission to consistently fast.
The payout system at ck222 app is fast and fair.
КредитоФФ http://creditoroff.ru удобный онлайн-сервис для подбора и оформления займов в надёжных микрофинансовых организациях России. Здесь вы найдёте лучшие предложения от МФО
Медикаментозное кодирование проводится с помощью препаратов, блокирующих ферменты, ответственные за расщепление этанола, что вызывает выраженное неприятие алкоголя при попытке его употребления. Препараты вводятся внутримышечно или с помощью подкожных имплантов и действуют в течение нескольких месяцев, обеспечивая длительный эффект.
Получить больше информации – https://kodirovanie-ot-alkogolizma-odintsovo2.ru
Алкогольный запой — это острое состояние тяжёлой интоксикации, при котором организм накапливает критические уровни продуктов распада этанола и перестаёт справляться с их нейтрализацией. При этом страдают важнейшие органы и системы: печень, почки, сердце, центральная нервная система. Без квалифицированной медицинской помощи риск развития судорог, алкогольного делирия и полиорганной недостаточности возрастает многократно.
Исследовать вопрос подробнее – https://vyvod-iz-zapoya-krasnogorsk2.ru/vyvod-iz-zapoya-anonimno
Hi there, You’ve done an incredible job. I?ll definitely digg it and personally recommend to my friends. I’m sure they’ll be benefited from this web site.
very nice put up, i certainly love this web site, carry on it
Алкогольный запой — это острое состояние тяжёлой интоксикации, при котором организм накапливает критические уровни продуктов распада этанола и перестаёт справляться с их нейтрализацией. При этом страдают важнейшие органы и системы: печень, почки, сердце, центральная нервная система. Без квалифицированной медицинской помощи риск развития судорог, алкогольного делирия и полиорганной недостаточности возрастает многократно.
Ознакомиться с деталями – http://vyvod-iz-zapoya-krasnogorsk2.ru/vyvod-iz-zapoya-anonimno/
«Кодирование — это не магическое решение, а важный этап в комплексной программе лечения, — поясняет ведущий нарколог клиники «Ясное Будущее» Марина Иванова. — Главное — сочетание фармакологического воздействия и последующей работы с психологом для формирования устойчивой мотивации к трезвости».
Получить дополнительные сведения – http://www.domen.ru
В «Горизонте Жизни» доступны два основных формата экстренной помощи: выездная служба на дому и лечение в условиях стационара.
Узнать больше – http://vyvod-iz-zapoya-krasnogorsk2.ru/
Алкогольный запой — это острое состояние тяжёлой интоксикации, при котором организм накапливает критические уровни продуктов распада этанола и перестаёт справляться с их нейтрализацией. При этом страдают важнейшие органы и системы: печень, почки, сердце, центральная нервная система. Без квалифицированной медицинской помощи риск развития судорог, алкогольного делирия и полиорганной недостаточности возрастает многократно.
Получить дополнительную информацию – вывод из запоя
Алкогольный запой — это острое состояние тяжёлой интоксикации, при котором организм накапливает критические уровни продуктов распада этанола и перестаёт справляться с их нейтрализацией. При этом страдают важнейшие органы и системы: печень, почки, сердце, центральная нервная система. Без квалифицированной медицинской помощи риск развития судорог, алкогольного делирия и полиорганной недостаточности возрастает многократно.
Получить дополнительные сведения – https://vyvod-iz-zapoya-krasnogorsk2.ru/vyvod-iz-zapoya-na-domu/
What a data of un-ambiguity and preserveness of precious experience concerning unpredicted feelings.
Ranked as a top site — explore 88fb casino now
В клинике «Горизонт Жизни» в Красногорске разработаны протоколы экстренного вывода из запоя, которые выполняются 24 часа в сутки, семь дней в неделю. Благодаря выезду бригады врачей-наркологов и оснащённости современным оборудованием мы оказываем помощь в кратчайшие сроки, обеспечивая максимальную безопасность и комфорт пациенту.
Получить дополнительные сведения – нарколог вывод из запоя
Услуги юриста Екатеринбург http://yuristy-ekaterinburga.ru
Алкогольный запой — это острое состояние тяжёлой интоксикации, при котором организм накапливает критические уровни продуктов распада этанола и перестаёт справляться с их нейтрализацией. При этом страдают важнейшие органы и системы: печень, почки, сердце, центральная нервная система. Без квалифицированной медицинской помощи риск развития судорог, алкогольного делирия и полиорганной недостаточности возрастает многократно.
Подробнее можно узнать тут – https://vyvod-iz-zapoya-krasnogorsk2.ru/vyvod-iz-zapoya-cena
Аппаратные методы кодирования включают лазерную терапию и электростимуляцию биологически активных точек, влияющих на центры зависимости в головном мозге. Эти методики способствуют быстрому формированию устойчивого отвращения к спиртному и хорошо переносятся пациентами.
Углубиться в тему – http://kodirovanie-ot-alkogolizma-odintsovo2.ru
Алкогольная зависимость — это хроническое заболевание, при котором устойчивое влечение к спиртному приводит к тяжёлым медицинским, социальным и психологическим последствиям. Когда пациент осознаёт, что самостоятельно справиться с этой проблемой не получается, наиболее эффективным методом становится кодирование от алкоголизма. В клинике «Ясное Будущее» в Одинцово мы используем сочетание проверенных методик кодирования и комплексной психологической поддержки, что позволяет достичь стойкой ремиссии и вернуть человеку контроль над собственной жизнью.
Разобраться лучше – кодирование от алкоголизма одинцово
оригинальное кашпо оригинальное кашпо .
Аппаратные методы кодирования включают лазерную терапию и электростимуляцию биологически активных точек, влияющих на центры зависимости в головном мозге. Эти методики способствуют быстрому формированию устойчивого отвращения к спиртному и хорошо переносятся пациентами.
Получить больше информации – кодирование от алкоголизма цены
На дом выезжает квалифицированный врач, который проводит процедуру детоксикации в комфортных условиях, позволяя пациенту избежать стресса и огласки. С помощью капельницы и медикаментов нормализуется состояние, восстанавливаются основные функции организма. Процедура длится несколько часов, после чего врач оставляет рекомендации по поддерживающему лечению.
Получить дополнительные сведения – вывод из запоя люберцы
Аппаратные методы кодирования включают лазерную терапию и электростимуляцию биологически активных точек, влияющих на центры зависимости в головном мозге. Эти методики способствуют быстрому формированию устойчивого отвращения к спиртному и хорошо переносятся пациентами.
Получить дополнительную информацию – кодирование от алкоголизма
Домашний формат идеально подходит для тех, кто находится в удовлетворительном состоянии и не требует круглосуточного контроля.
Ознакомиться с деталями – https://vyvod-iz-zapoya-lyubertsy2.ru/
«В первые часы после окончания запоя организм наиболее уязвим, и своевременное вмешательство значительно снижает риски осложнений», — подчёркивает заведующая отделением наркологической реанимации Елена Морозова.
Выяснить больше – вывод из запоя
Ниже приведены ключевые сигналы, при появлении которых требуется немедленное реагирование:
Подробнее можно узнать тут – vyvod iz zapoya krasnogorsk
Базовый метод, сочетающий регидратацию, электролитную коррекцию и витаминные комплексы:
Углубиться в тему – vyvod-iz-zapoya-klinika krasnojarsk
В нашей клинике применяются различные техники кодирования, которые подбираются с учётом медицинских показаний, психологического состояния и пожеланий пациента.
Получить дополнительные сведения – кодирование от алкоголизма гипнозом
«В первые часы после окончания запоя организм наиболее уязвим, и своевременное вмешательство значительно снижает риски осложнений», — подчёркивает заведующая отделением наркологической реанимации Елена Морозова.
Узнать больше – нарколог вывод из запоя
Алкогольный запой — это острое состояние тяжёлой интоксикации, при котором организм накапливает критические уровни продуктов распада этанола и перестаёт справляться с их нейтрализацией. При этом страдают важнейшие органы и системы: печень, почки, сердце, центральная нервная система. Без квалифицированной медицинской помощи риск развития судорог, алкогольного делирия и полиорганной недостаточности возрастает многократно.
Подробнее тут – vyvod-iz-zapoya-krasnogorsk2.ru/
займы онлайн без процентов займ на карту онлайн первый раз
Алкогольный запой — это острое состояние тяжёлой интоксикации, при котором организм накапливает критические уровни продуктов распада этанола и перестаёт справляться с их нейтрализацией. При этом страдают важнейшие органы и системы: печень, почки, сердце, центральная нервная система. Без квалифицированной медицинской помощи риск развития судорог, алкогольного делирия и полиорганной недостаточности возрастает многократно.
Ознакомиться с деталями – vyvod iz zapoya cena
Алкогольный запой — это острое состояние тяжёлой интоксикации, при котором организм накапливает критические уровни продуктов распада этанола и перестаёт справляться с их нейтрализацией. При этом страдают важнейшие органы и системы: печень, почки, сердце, центральная нервная система. Без квалифицированной медицинской помощи риск развития судорог, алкогольного делирия и полиорганной недостаточности возрастает многократно.
Получить больше информации – https://vyvod-iz-zapoya-krasnogorsk2.ru/
Базовый метод, сочетающий регидратацию, электролитную коррекцию и витаминные комплексы:
Подробнее тут – вывод из запоя капельница красноярск
Базовый метод, сочетающий регидратацию, электролитную коррекцию и витаминные комплексы:
Разобраться лучше – вывод из запоя на дому цена красноярск
Клиника «Красмед» специализируется на экстренной и плановой наркологической помощи более десяти лет. В арсенале клиники:
Разобраться лучше – https://medicinskij-vyvod-iz-zapoya.ru/vyvod-iz-zapoya-na-domu-krasnoyarsk/
В нашей клинике применяются различные техники кодирования, которые подбираются с учётом медицинских показаний, психологического состояния и пожеланий пациента.
Узнать больше – центр кодирования от алкоголизма
Эта обзорная заметка содержит ключевые моменты и факты по актуальным вопросам. Она поможет читателям быстро ориентироваться в теме и узнать о самых важных аспектах сегодня. Получите краткий курс по современной информации и оставайтесь в курсе событий!
Получить дополнительные сведения – https://coachsamira.com/uncategorized/le-developpement-professionnel-une-cle-pour-levolution-des-employes-et-la-croissance-des-entreprises
В этом информативном тексте представлены захватывающие события и факты, которые заставят вас задуматься. Мы обращаем внимание на важные моменты, которые часто остаются незамеченными, и предлагаем новые перспективы на привычные вещи. Подготовьтесь к тому, чтобы быть поглощенным увлекательными рассказами!
Исследовать вопрос подробнее – https://remeslneprace.com/connecting-with-natures-tranquil-essence
В данной обзорной статье представлены интригующие факты, которые не оставят вас равнодушными. Мы критикуем и анализируем события, которые изменили наше восприятие мира. Узнайте, что стоит за новыми открытиями и как они могут изменить ваше восприятие реальности.
Узнать больше – https://kawaiiclinic.vn/dieu-tri-tham-mat-bang-cong-nghe-laser-toning
В этот этап включено:
Углубиться в тему – vyvod-iz-zapoya-kruglosutochno novosibirsk
Эта статья сочетает в себе как полезные, так и интересные сведения, которые обогатят ваше понимание насущных тем. Мы предлагаем практические советы и рекомендации, которые легко внедрить в повседневную жизнь. Узнайте, как улучшить свои навыки и обогатить свой опыт с помощью простых, но эффективных решений.
Исследовать вопрос подробнее – https://game.center.ru/forum/viewtopic.php?f=7&t=28729&p=194209
Эта статья предлагает уникальную подборку занимательных фактов и необычных историй, которые вы, возможно, не знали. Мы постараемся вдохновить ваше воображение и разнообразить ваш кругозор, погружая вас в мир, полный интересных открытий. Читайте и открывайте для себя новое!
Получить больше информации – https://domains.tntcode.com/ip/87.236.16.191
Городской портал Черкассы https://u-misti.cherkasy.ua новости, обзоры, события Черкасс и области
Этот информативный текст выделяется своими захватывающими аспектами, которые делают сложные темы доступными и понятными. Мы стремимся предложить читателям глубину знаний вместе с разнообразием интересных фактов. Откройте новые горизонты и развивайте свои способности познавать мир!
Выяснить больше – https://lyubimiigorod.ru/taganrog/WMnzn9FKlp
Основные показания для вызова нарколога:
Разобраться лучше – врач нарколог на дом платный иркутск
Запой — это тяжёлое состояние, характеризующееся длительным употреблением алкоголя, при котором человек не в силах самостоятельно прекратить пить. Алкогольная интоксикация при длительных запоях вызывает нарушения в работе всех органов и систем, приводя к серьёзным последствиям, таким как инфаркты, инсульты, психозы и даже летальный исход. В такой ситуации единственным надёжным решением становится обращение за профессиональной помощью.
Изучить вопрос глубже – вывод из запоя
Эта публикация завернет вас в вихрь увлекательного контента, сбрасывая стереотипы и открывая двери к новым идеям. Каждый абзац станет для вас открытием, полным ярких примеров и впечатляющих достижений. Подготовьтесь быть вовлеченными и удивленными каждый раз, когда продолжите читать.
Получить больше информации – https://divinewoodncrafts.com/creating-a-pious-space-within-the-house-for-prayer
Клиника «АнтиАлко» предлагает экстренную медицинскую помощь на дому в Новосибирске и Новосибирской области для тех, кто столкнулся с запоем. Если вы или ваш близкий оказались в состоянии длительной алкогольной интоксикации, наши специалисты готовы оперативно приехать к вам, провести комплексную детоксикацию и купировать симптомы абстинентного синдрома. Мы гарантируем высокий уровень безопасности, полную анонимность и индивидуальный подход к каждому пациенту.
Детальнее – вывод из запоя на дому круглосуточно новосибирск
После поступления вызова наш нарколог выезжает к пациенту в кратчайшие сроки, прибывая по адресу в пределах 30–60 минут. Специалист начинает процедуру с подробного осмотра и диагностики, измеряя ключевые показатели организма: артериальное давление, частоту пульса, насыщенность кислородом и собирая подробный анамнез.
Выяснить больше – вызов нарколога на дом в новосибирске
Портал города Черновцы https://u-misti.chernivtsi.ua последние новости, события, обзоры
Запой — это тяжёлое состояние, характеризующееся длительным употреблением алкоголя, при котором человек не в силах самостоятельно прекратить пить. Алкогольная интоксикация при длительных запоях вызывает нарушения в работе всех органов и систем, приводя к серьёзным последствиям, таким как инфаркты, инсульты, психозы и даже летальный исход. В такой ситуации единственным надёжным решением становится обращение за профессиональной помощью.
Изучить вопрос глубже – вывод из запоя на дому круглосуточно
Наши врачи используют только проверенные и сертифицированные медикаменты, индивидуально подбираемые для каждого пациента. В состав лечебного курса входят:
Подробнее – нарколог вывод из запоя новосибирск
В таких случаях своевременный вызов нарколога на дом позволяет быстро стабилизировать состояние больного и предотвратить тяжелые последствия.
Подробнее – https://narcolog-na-dom-novosibirsk00.ru/narkolog-na-dom-kruglosutochno-novosibirsk
вызвать нарколога на дом анонимно нарколог на домв нижнем новгороде
Запой — это тяжёлое состояние, характеризующееся длительным употреблением алкоголя, при котором человек не в силах самостоятельно прекратить пить. Алкогольная интоксикация при длительных запоях вызывает нарушения в работе всех органов и систем, приводя к серьёзным последствиям, таким как инфаркты, инсульты, психозы и даже летальный исход. В такой ситуации единственным надёжным решением становится обращение за профессиональной помощью.
Подробнее можно узнать тут – вывод из запоя на дому королев
Наркологическая клиника «МедЛайн» предоставляет профессиональные услуги врача-нарколога с выездом на дом в Новосибирске и Новосибирской области. Мы оперативно помогаем пациентам справиться с тяжелыми состояниями при алкогольной и наркотической зависимости. Экстренный выезд наших специалистов доступен круглосуточно, а лечение проводится с применением проверенных методик и препаратов, что гарантирует безопасность и конфиденциальность каждому пациенту.
Выяснить больше – http://narcolog-na-dom-novosibirsk00.ru
Действие и назначение
Получить дополнительные сведения – вывод из запоя круглосуточно в новосибирске
кодировка от алкоголя цена https://kodirovanie-info.ru
лечение алкоголизма в стационаре лечение алкоголизма в Нижнем Новгороде
вывод из запоя сейчас выведение из запоя цена
Основные показания для вызова нарколога:
Углубиться в тему – http://narcolog-na-dom-v-irkutske00.ru
Вызывать нарколога на дом рекомендуется при следующих состояниях:
Подробнее – нарколог на дом вывод из запоя в санкт-петербурге
Праздничная продукция https://prazdnik-x.ru для любого повода: шары, гирлянды, декор, упаковка, сувениры. Всё для дня рождения, свадьбы, выпускного и корпоративов.
оценка активов москва оценка торговой недвижимости
лечение наркомании кодирование лечение наркомании НН
Всё для строительства https://d20.com.ua и ремонта: инструкции, обзоры, экспертизы, калькуляторы. Профессиональные советы, новинки рынка, база строительных компаний.
прикольные кашпо прикольные кашпо .
Вызывать нарколога на дом рекомендуется при следующих состояниях:
Изучить вопрос глубже – нарколог на дом круглосуточно санкт-петербург
После завершения процедур пациенту предоставляется подробная консультация с рекомендациями по дальнейшему восстановлению и профилактике повторных случаев зависимости.
Выяснить больше – https://narcolog-na-dom-novosibirsk00.ru
Вызов врача-нарколога на дом позволяет избежать стресса госпитализации, обеспечивая комфорт и удобство как для пациента, так и для его близких.
Исследовать вопрос подробнее – нарколог на дом недорого
Строительный журнал https://garant-jitlo.com.ua всё о технологиях, материалах, архитектуре, ремонте и дизайне. Интервью с экспертами, кейсы, тренды рынка.
Онлайн-журнал https://inox.com.ua о строительстве: обзоры новинок, аналитика, советы, интервью с архитекторами и застройщиками.
Современный строительный https://interiordesign.kyiv.ua журнал: идеи, решения, технологии, тенденции. Всё о ремонте, стройке, дизайне и инженерных системах.
Пациенты выбирают нашу клинику для срочного вызова врача-нарколога благодаря следующим важным преимуществам:
Узнать больше – выезд нарколога на дом в новосибирске
Информационный журнал https://newhouse.kyiv.ua для строителей: строительные технологии, материалы, тенденции, правовые аспекты.
Некоторые состояния требуют немедленного вмешательства специалиста. Если алкогольное отравление или запойное состояние не купируется вовремя, это может привести к тяжелым последствиям для здоровья.
Получить больше информации – вызов нарколога на дом цена в иркутске
Запой — одно из самых опасных проявлений алкогольной зависимости. Он сопровождается глубокой интоксикацией организма, нарушением работы сердца, печени, головного мозга и других жизненно важных систем. Когда человек не может остановиться самостоятельно, а организм больше не справляется с нагрузкой, требуется медицинская помощь. В наркологической клинике «Спасение» в Мытищах мы проводим экстренные процедуры инфузионной терапии, позволяющие эффективно и безопасно вывести пациента из состояния запоя. Капельница — это первый шаг на пути к восстановлению здоровья и возвращению к нормальной жизни.
Выяснить больше – поставить капельницу от запоя
Основные показания для вызова нарколога:
Ознакомиться с деталями – https://narcolog-na-dom-v-irkutske00.ru/narkolog-na-dom-czena-irkutsk
В таких случаях своевременный вызов нарколога на дом позволяет быстро стабилизировать состояние больного и предотвратить тяжелые последствия.
Узнать больше – https://narcolog-na-dom-novosibirsk00.ru/vyzov-narkologa-na-dom-novosibirsk
Наркологическая клиника «Крылья Надежды» в Королеве оказывает квалифицированную помощь в выводе из запоя с применением безопасных, сертифицированных методик и круглосуточным наблюдением специалистов.
Подробнее тут – https://vyvod-iz-zapoya-korolev2.ru/vyvod-iz-zapoya-kruglosutochno
Действие и назначение
Разобраться лучше – vyvod-iz-zapoya-kruglosutochno novosibirsk
Наркологическая клиника «Крылья Надежды» в Королеве оказывает квалифицированную помощь в выводе из запоя с применением безопасных, сертифицированных методик и круглосуточным наблюдением специалистов.
Подробнее можно узнать тут – вывод из запоя круглосуточно
После поступления вызова наш нарколог выезжает к пациенту в кратчайшие сроки, прибывая по адресу в пределах 30–60 минут. Специалист начинает процедуру с подробного осмотра и диагностики, измеряя ключевые показатели организма: артериальное давление, частоту пульса, насыщенность кислородом и собирая подробный анамнез.
Исследовать вопрос подробнее – нарколог на дом вывод
Наркологическая клиника «МедЛайн» предоставляет профессиональные услуги врача-нарколога с выездом на дом в Новосибирске и Новосибирской области. Мы оперативно помогаем пациентам справиться с тяжелыми состояниями при алкогольной и наркотической зависимости. Экстренный выезд наших специалистов доступен круглосуточно, а лечение проводится с применением проверенных методик и препаратов, что гарантирует безопасность и конфиденциальность каждому пациенту.
Ознакомиться с деталями – нарколог на дом новосибирск
Длительное и бесконтрольное употребление алкоголя может привести к состоянию запоя — опасному и тяжелому состоянию, при котором человек не способен самостоятельно отказаться от спиртного. Во время запоя организм постепенно накапливает токсины, что негативно сказывается на работе всех внутренних органов и систем. В таких случаях пациенту необходима экстренная врачебная помощь, и специалисты наркологической клиники «АнтиТокс» готовы оперативно оказать профессиональную медицинскую поддержку на дому в Новосибирске.
Получить дополнительную информацию – наркологический вывод из запоя новосибирск
В обзорной статье вы найдете собрание важных фактов и аналитики по самым разнообразным темам. Мы рассматриваем как современные исследования, так и исторические контексты, чтобы вы могли получить полное представление о предмете. Погрузитесь в мир знаний и сделайте шаг к пониманию!
Углубиться в тему – https://agence-bonjour.fr/6-astuces-pour-booster-son-compte-instagram
Новинний сайт Житомира https://faine-misto.zt.ua новости Житомира сегодня
Домашний формат идеально подходит для тех, кто находится в удовлетворительном состоянии и не требует круглосуточного контроля.
Узнать больше – https://vyvod-iz-zapoya-lyubertsy2.ru/vyvod-iz-zapoya-na-domu/
Эта публикация погружает вас в мир увлекательных фактов и удивительных открытий. Мы расскажем о ключевых событиях, которые изменили ход истории, и приоткроем завесу над научными достижениями, которые вдохновили миллионы. Узнайте, чему может научить нас прошлое и как применить эти знания в будущем.
Получить дополнительную информацию – http://www.evangelikusiskola.hu/hitelet/img_20160912_075207
После поступления вызова наш нарколог выезжает к пациенту в кратчайшие сроки, прибывая по адресу в пределах 30–60 минут. Специалист начинает процедуру с подробного осмотра и диагностики, измеряя ключевые показатели организма: артериальное давление, частоту пульса, насыщенность кислородом и собирая подробный анамнез.
Ознакомиться с деталями – вызов нарколога на дом в новосибирске
Предлагаем вашему вниманию интересную справочную статью, в которой собраны ключевые моменты и нюансы по актуальным вопросам. Эта информация будет полезна как для профессионалов, так и для тех, кто только начинает изучать тему. Узнайте ответы на важные вопросы и расширьте свои знания!
Получить дополнительные сведения – https://mostravinimontepagano.it/cambria-italic
Строительный журнал https://poradnik.com.ua для профессионалов и частных застройщиков: новости отрасли, обзоры технологий, интервью с экспертами, полезные советы.
Всё о строительстве https://stroyportal.kyiv.ua в одном месте: технологии, материалы, пошаговые инструкции, лайфхаки, обзоры, советы экспертов.
Журнал о строительстве https://sovetik.in.ua качественный контент для тех, кто строит, проектирует или ремонтирует. Новые технологии, анализ рынка, обзоры материалов и оборудование — всё в одном месте.
Полезный сайт https://vasha-opora.com.ua для тех, кто строит: от фундамента до крыши. Советы, инструкции, сравнение материалов, идеи для ремонта и дизайна.
Эта информационная заметка предлагает лаконичное и четкое освещение актуальных вопросов. Здесь вы найдете ключевые факты и основную информацию по теме, которые помогут вам сформировать собственное мнение и повысить уровень осведомленности.
Подробнее – https://www.kaokimhourn.com/eng/?p=3376
Эта разъяснительная статья содержит простые и доступные разъяснения по актуальным вопросам. Мы стремимся сделать информацию понятной для широкой аудитории, чтобы каждый смог разобраться в предмете и извлечь из него максимум пользы.
Подробнее – https://economic-travel.com/introducing-this-amazing-city-2
Этот информативный текст отличается привлекательным содержанием и актуальными данными. Мы предлагаем читателям взглянуть на привычные вещи под новым углом, предоставляя интересный и доступный материал. Получите удовольствие от чтения и расширьте кругозор!
Получить дополнительные сведения – https://www.chiaviexpress.eu/2017/06/18/duplicazioni-chiavi-bmw
В этой статье-обзоре мы соберем актуальную информацию и интересные факты, которые освещают важные темы. Читатели смогут ознакомиться с различными мнениями и подходами, что позволит им расширить кругозор и глубже понять обсуждаемые вопросы.
Детальнее – https://airport-transfer.si/2019/01/28/a-walk-outside
Когда следует немедленно обращаться за помощью:
Узнать больше – http://narcolog-na-dom-novokuznetsk0.ru/narkolog-na-dom-czena-novokuzneczk/
Алкогольная зависимость — это хроническое заболевание, при котором устойчивое влечение к спиртному приводит к тяжёлым медицинским, социальным и психологическим последствиям. Когда пациент осознаёт, что самостоятельно справиться с этой проблемой не получается, наиболее эффективным методом становится кодирование от алкоголизма. В клинике «Ясное Будущее» в Одинцово мы используем сочетание проверенных методик кодирования и комплексной психологической поддержки, что позволяет достичь стойкой ремиссии и вернуть человеку контроль над собственной жизнью.
Выяснить больше – https://kodirovanie-ot-alkogolizma-odintsovo2.ru/kodirovanie-ot-alkogolizma-na-domu/
Новости Полтава https://u-misti.poltava.ua городской портал, последние события Полтавы и области
Комплексная терапия при выводе из запоя на дому включает в себя два основных направления: медикаментозную детоксикацию и психологическую поддержку. Такой подход позволяет добиться быстрого и устойчивого эффекта, минимизируя риск осложнений и обеспечивая долгосрочную ремиссию.
Выяснить больше – narkolog na dom
Эта публикация погружает вас в мир увлекательных фактов и удивительных открытий. Мы расскажем о ключевых событиях, которые изменили ход истории, и приоткроем завесу над научными достижениями, которые вдохновили миллионы. Узнайте, чему может научить нас прошлое и как применить эти знания в будущем.
Детальнее – https://espacouvir.com.br/profissionais-aprovam-novas-regras-do-selo-ruido
Запой может быть не только физически тяжёлым, но и психологически разрушительным. Поэтому важно вовремя обратиться за помощью. Вывод из запоя в Нижнем Новгороде — это необходимая медицинская процедура, которая помогает победить алкогольную зависимость и восстановить здоровье. Мы в клинике «АнтиЗависимость» предлагаем круглосуточную помощь в комфортных условиях — на дому или в стационаре.
Выяснить больше – нарколог на дом круглосуточно в новокузнецке
Запой может быть не только физически тяжёлым, но и психологически разрушительным. Поэтому важно вовремя обратиться за помощью. Вывод из запоя в Нижнем Новгороде — это необходимая медицинская процедура, которая помогает победить алкогольную зависимость и восстановить здоровье. Мы в клинике «АнтиЗависимость» предлагаем круглосуточную помощь в комфортных условиях — на дому или в стационаре.
Получить больше информации – выезд нарколога на дом
Этот обзорный материал предоставляет информационно насыщенные данные, касающиеся актуальных тем. Мы стремимся сделать информацию доступной и структурированной, чтобы читатели могли легко ориентироваться в наших выводах. Познайте новое с нашим обзором!
Получить больше информации – http://cinemovel.tv/sic/2020/dal-primo-omicidio-allarresto-una-lunga-scia-di-orrori
Комплексная терапия при выводе из запоя на дому включает в себя два основных направления: медикаментозную детоксикацию и психологическую поддержку. Такой подход позволяет добиться быстрого и устойчивого эффекта, минимизируя риск осложнений и обеспечивая долгосрочную ремиссию.
Получить дополнительные сведения – вызов нарколога цена уфа
Лечение зависимости требует не только физической детоксикации, но и работы с психоэмоциональным состоянием пациента. Психотерапевтическая поддержка помогает выявить глубинные причины зависимости, снизить уровень стресса и сформировать устойчивые навыки самоконтроля, что существенно снижает риск рецидивов.
Подробнее – платный нарколог на дом в уфе
Кулинарный портал https://vagon-restoran.kiev.ua с тысячами проверенных рецептов на каждый день и для особых случаев. Пошаговые инструкции, фото, видео, советы шефов.
Мужской журнал https://hand-spin.com.ua о стиле, спорте, отношениях, здоровье, технике и бизнесе. Актуальные статьи, советы экспертов, обзоры и мужской взгляд на важные темы.
Журнал для мужчин https://swiss-watches.com.ua которые ценят успех, свободу и стиль. Практичные советы, мотивация, интервью, спорт, отношения, технологии.
Читайте мужской https://zlochinec.kyiv.ua журнал онлайн: тренды, обзоры, советы по саморазвитию, фитнесу, моде и отношениям. Всё о том, как быть уверенным, успешным и сильным — каждый день.
При длительном запое в организме накапливаются вредные токсины, что ведёт к нарушениям работы сердца, печени, почек и других жизненно важных органов. Чем быстрее начинается терапия, тем выше шансы избежать серьёзных осложнений и обеспечить качественное восстановление. Метод капельничного лечения позволяет оперативно начать детоксикацию, что особенно важно для спасения жизни и предупреждения хронических последствий злоупотребления алкоголем.
Получить дополнительные сведения – https://kapelnica-ot-zapoya-tyumen00.ru/kapelnicza-ot-zapoya-na-domu-tyumen/
Также страдают сердце и сосуды. У пациентов часто наблюдаются тахикардия, нестабильное давление, аритмии, повышенный риск инфаркта или инсульта. Система пищеварения реагирует воспалением: гастрит, панкреатит, тошнота, рвота. Все эти изменения усиливаются на фоне обезвоживания и электролитного дисбаланса. Именно поэтому стандартное «отлежаться» или домашнее лечение чаще всего оказывается неэффективным и даже опасным. Необходима полноценная капельная терапия — с грамотно подобранными препаратами и медицинским наблюдением.
Детальнее – капельница от запоя на дому химки
При поступлении вызова нарколог незамедлительно приезжает на дом для проведения тщательного осмотра. На этом этапе специалист измеряет жизненно важные показатели, собирает подробный анамнез и определяет степень интоксикации. Эти данные являются ключевыми для составления индивидуального плана лечения.
Подробнее – после капельницы от запоя на дому в тюмени
Врач уточняет продолжительность запоя, характер употребляемого алкоголя и наличие сопутствующих заболеваний. Детальное обследование позволяет оперативно подобрать необходимые медикаменты и минимизировать риск осложнений.
Детальнее – после капельницы от запоя на дому в тюмени
Запой может быть не только физически тяжёлым, но и психологически разрушительным. Поэтому важно вовремя обратиться за помощью. Вывод из запоя в Нижнем Новгороде — это необходимая медицинская процедура, которая помогает победить алкогольную зависимость и восстановить здоровье. Мы в клинике «АнтиЗависимость» предлагаем круглосуточную помощь в комфортных условиях — на дому или в стационаре.
Углубиться в тему – https://narcolog-na-dom-novokuznetsk0.ru
ИнфоКиев https://infosite.kyiv.ua события, новости обзоры в Киеве и области.
Процедура начинается с врачебного осмотра. Специалист оценивает общее состояние, артериальное давление, пульс, сатурацию, уровень обезвоживания, жалобы пациента. При необходимости проводятся экспресс-анализы. Далее индивидуально подбирается состав инфузионной терапии. В большинстве случаев капельница включает:
Подробнее – http://kapelnica-ot-zapoya-moskva3.ru
Комплексная терапия при выводе из запоя на дому включает в себя два основных направления: медикаментозную детоксикацию и психологическую поддержку. Такой подход позволяет добиться быстрого и устойчивого эффекта, минимизируя риск осложнений и обеспечивая долгосрочную ремиссию.
Ознакомиться с деталями – https://narcolog-na-dom-ufa000.ru/narkolog-na-dom-czena-ufa/
Запой может быть не только физически тяжёлым, но и психологически разрушительным. Поэтому важно вовремя обратиться за помощью. Вывод из запоя в Нижнем Новгороде — это необходимая медицинская процедура, которая помогает победить алкогольную зависимость и восстановить здоровье. Мы в клинике «АнтиЗависимость» предлагаем круглосуточную помощь в комфортных условиях — на дому или в стационаре.
Получить дополнительную информацию – http://www.domen.ru
Комплексное лечение организовано по строго отлаженной схеме, которая включает несколько последовательных этапов, позволяющих обеспечить оперативное и безопасное восстановление организма.
Изучить вопрос глубже – https://kapelnica-ot-zapoya-tyumen00.ru/postavit-kapelniczu-ot-zapoya-tyumen
Процедура начинается с врачебного осмотра. Специалист оценивает общее состояние, артериальное давление, пульс, сатурацию, уровень обезвоживания, жалобы пациента. При необходимости проводятся экспресс-анализы. Далее индивидуально подбирается состав инфузионной терапии. В большинстве случаев капельница включает:
Подробнее можно узнать тут – http://kapelnica-ot-zapoya-moskva3.ru
После поступления звонка нарколог оперативно выезжает по указанному адресу и прибывает в течение 30–60 минут. Врач незамедлительно приступает к оказанию помощи по четко отработанному алгоритму, состоящему из следующих этапов:
Изучить вопрос глубже – https://narcolog-na-dom-voronezh00.ru/vyzov-narkologa-na-dom-voronezh/
Комплексная терапия при выводе из запоя на дому включает в себя два основных направления: медикаментозную детоксикацию и психологическую поддержку. Такой подход позволяет добиться быстрого и устойчивого эффекта, минимизируя риск осложнений и обеспечивая долгосрочную ремиссию.
Детальнее – нарколог на дом цены уфа
При длительном запое в организме накапливаются вредные токсины, что ведёт к нарушениям работы сердца, печени, почек и других жизненно важных органов. Чем быстрее начинается терапия, тем выше шансы избежать серьёзных осложнений и обеспечить качественное восстановление. Метод капельничного лечения позволяет оперативно начать детоксикацию, что особенно важно для спасения жизни и предупреждения хронических последствий злоупотребления алкоголем.
Получить дополнительные сведения – после капельницы от запоя тюмень
Когда следует немедленно обращаться за помощью:
Получить дополнительные сведения – врач нарколог на дом кемеровская область
Выбор капельничного метода в условиях домашнего лечения обладает рядом преимуществ:
Разобраться лучше – капельница от запоя на дому тюмень
Услуга “Нарколог на дом” в Уфе охватывает широкий спектр лечебных мероприятий, направленных как на устранение токсической нагрузки, так и на работу с психоэмоциональным состоянием пациента. Комплексная терапия включает в себя медикаментозную детоксикацию, корректировку обменных процессов, а также психотерапевтическую поддержку, что позволяет не только вывести пациента из состояния запоя, но и помочь ему справиться с наркотической зависимостью.
Получить больше информации – narkolog na dom ufa
Все новинки https://helikon.com.ua технологий в одном месте: гаджеты, AI, робототехника, электромобили, мобильные устройства, инновации в науке и IT.
Портал о ремонте https://as-el.com.ua и строительстве: от черновых работ до отделки. Статьи, обзоры, идеи, лайфхаки.
Ремонт без стресса https://odessajs.org.ua вместе с нами! Полезные статьи, лайфхаки, дизайн-проекты, калькуляторы и обзоры.
Сайт о строительстве https://selma.com.ua практические советы, современные технологии, пошаговые инструкции, выбор материалов и обзоры техники.
При длительном запое в организме накапливаются вредные токсины, что ведёт к нарушениям работы сердца, печени, почек и других жизненно важных органов. Чем быстрее начинается терапия, тем выше шансы избежать серьёзных осложнений и обеспечить качественное восстановление. Метод капельничного лечения позволяет оперативно начать детоксикацию, что особенно важно для спасения жизни и предупреждения хронических последствий злоупотребления алкоголем.
Углубиться в тему – https://kapelnica-ot-zapoya-tyumen00.ru/kapelnicza-ot-zapoya-na-domu-tyumen
Когда следует немедленно обращаться за помощью:
Получить дополнительную информацию – нарколог на дом клиника новокузнецк
Комплексное лечение организовано по строго отлаженной схеме, которая включает несколько последовательных этапов, позволяющих обеспечить оперативное и безопасное восстановление организма.
Углубиться в тему – https://kapelnica-ot-zapoya-tyumen00.ru/
Запой может быть не только физически тяжёлым, но и психологически разрушительным. Поэтому важно вовремя обратиться за помощью. Вывод из запоя в Нижнем Новгороде — это необходимая медицинская процедура, которая помогает победить алкогольную зависимость и восстановить здоровье. Мы в клинике «АнтиЗависимость» предлагаем круглосуточную помощь в комфортных условиях — на дому или в стационаре.
Получить дополнительную информацию – нарколог на дом недорого новокузнецк
дизайнерский горшок дизайнерский горшок .
Процесс вывода из запоя капельничным методом организован по строгой схеме, позволяющей обеспечить максимальную эффективность терапии. Каждая стадия направлена на комплексное восстановление организма и минимизацию риска осложнений.
Углубиться в тему – http://kapelnica-ot-zapoya-tyumen0.ru/kapelnicza-ot-zapoya-na-domu-czena-tyumen/
Лечение зависимости требует не только физической детоксикации, но и работы с психоэмоциональным состоянием пациента. Психотерапевтическая поддержка помогает выявить глубинные причины зависимости, снизить уровень стресса и сформировать устойчивые навыки самоконтроля, что существенно снижает риск рецидивов.
Получить дополнительные сведения – http://narcolog-na-dom-ufa000.ru
Лечение зависимости требует не только физической детоксикации, но и работы с психоэмоциональным состоянием пациента. Психотерапевтическая поддержка помогает выявить глубинные причины зависимости, снизить уровень стресса и сформировать устойчивые навыки самоконтроля, что существенно снижает риск рецидивов.
Изучить вопрос глубже – https://narcolog-na-dom-ufa000.ru/narkolog-na-dom-kruglosutochno-ufa/
После первичной диагностики начинается активная фаза детоксикации. Современные препараты вводятся капельничным методом, что позволяет быстро снизить концентрацию токсинов в крови и восстановить нормальные обменные процессы. Этот этап является основополагающим для стабилизации работы внутренних органов, таких как печень, почки и сердце.
Подробнее – https://kapelnica-ot-zapoya-tyumen00.ru/kapelnicza-ot-zapoya-na-domu-tyumen/
Запой может быть не только физически тяжёлым, но и психологически разрушительным. Поэтому важно вовремя обратиться за помощью. Вывод из запоя в Нижнем Новгороде — это необходимая медицинская процедура, которая помогает победить алкогольную зависимость и восстановить здоровье. Мы в клинике «АнтиЗависимость» предлагаем круглосуточную помощь в комфортных условиях — на дому или в стационаре.
Подробнее можно узнать тут – врач нарколог на дом в новокузнецке
После поступления звонка нарколог оперативно выезжает по указанному адресу и прибывает в течение 30–60 минут. Врач незамедлительно приступает к оказанию помощи по четко отработанному алгоритму, состоящему из следующих этапов:
Подробнее тут – нарколог на дом цена
Врач уточняет продолжительность запоя, характер употребляемого алкоголя и наличие сопутствующих заболеваний. Детальное обследование позволяет оперативно подобрать необходимые медикаменты и минимизировать риск осложнений.
Подробнее – https://kapelnica-ot-zapoya-tyumen00.ru/kapelnicza-ot-zapoya-na-domu-czena-tyumen/
Услуга “Нарколог на дом” в Уфе охватывает широкий спектр лечебных мероприятий, направленных как на устранение токсической нагрузки, так и на работу с психоэмоциональным состоянием пациента. Комплексная терапия включает в себя медикаментозную детоксикацию, корректировку обменных процессов, а также психотерапевтическую поддержку, что позволяет не только вывести пациента из состояния запоя, но и помочь ему справиться с наркотической зависимостью.
Изучить вопрос глубже – вызов нарколога на дом цена уфа
Экстренная медицинская помощь при зависимостях становится необходимостью в ситуациях, когда пациент не может самостоятельно прервать запой или прекратить употребление наркотических веществ. Обратиться к наркологу на дом срочно рекомендуется при возникновении следующих признаков:
Подробнее тут – https://narcolog-na-dom-voronezh00.ru/narkolog-na-dom-anonimno-voronezh
Когда запой превращается в угрозу для жизни, оперативное вмешательство становится критически важным. В Тюмени, Тюменская область, опытные наркологи предлагают услугу установки капельницы от запоя прямо на дому. Такой метод позволяет начать детоксикацию с использованием современных медикаментов, что способствует быстрому выведению токсинов, восстановлению обменных процессов и нормализации работы внутренних органов. Лечение на дому обеспечивает комфортную обстановку, полную конфиденциальность и индивидуальный подход к каждому пациенту.
Изучить вопрос глубже – https://kapelnica-ot-zapoya-tyumen00.ru/
Если кто ищет, где получить займ до 30 тысяч, а старые МФО уже надоели — советую написать Виктору Гардиенову на https://mfo-zaim.com/info-zaim/ . Руководит отделом клиентского обслуживания, разбирается в рынке. Помог с выбором МФО, где реально одобряют новичкам.
При длительном запое в организме накапливаются вредные токсины, что ведёт к нарушениям работы сердца, печени, почек и других жизненно важных органов. Чем быстрее начинается терапия, тем выше шансы избежать серьёзных осложнений и обеспечить качественное восстановление. Метод капельничного лечения позволяет оперативно начать детоксикацию, что особенно важно для спасения жизни и предупреждения хронических последствий злоупотребления алкоголем.
Получить дополнительные сведения – капельница от запоя на дому тюмень
При поступлении вызова нарколог незамедлительно приезжает на дом для проведения тщательного осмотра. На этом этапе специалист измеряет жизненно важные показатели, собирает подробный анамнез и определяет степень интоксикации. Эти данные являются ключевыми для составления индивидуального плана лечения.
Детальнее – https://kapelnica-ot-zapoya-tyumen00.ru/
Когда следует немедленно обращаться за помощью:
Исследовать вопрос подробнее – запой нарколог на дом
Наркологическая клиника «Крылья Надежды» в Королеве оказывает квалифицированную помощь в выводе из запоя с применением безопасных, сертифицированных методик и круглосуточным наблюдением специалистов.
Узнать больше – http://vyvod-iz-zapoya-korolev2.ru/
Комплексная терапия при выводе из запоя на дому включает в себя два основных направления: медикаментозную детоксикацию и психологическую поддержку. Такой подход позволяет добиться быстрого и устойчивого эффекта, минимизируя риск осложнений и обеспечивая долгосрочную ремиссию.
Детальнее – http://narcolog-na-dom-ufa000.ru/narkolog-na-dom-kruglosutochno-ufa/
Служба круглосуточного вывода из запоя организована таким образом, чтобы обеспечить максимальную оперативность и надежность. Независимо от времени суток, квалифицированные специалисты готовы выехать на дом или принять пациента в медицинском учреждении, чтобы приступить к детоксикации и стабилизации состояния.
Изучить вопрос глубже – http://vyvod-iz-zapoya-volgograd000.ru/vyvod-iz-zapoya-na-domu-volgograd/
Запой может быть не только физически тяжёлым, но и психологически разрушительным. Поэтому важно вовремя обратиться за помощью. Вывод из запоя в Нижнем Новгороде — это необходимая медицинская процедура, которая помогает победить алкогольную зависимость и восстановить здоровье. Мы в клинике «АнтиЗависимость» предлагаем круглосуточную помощь в комфортных условиях — на дому или в стационаре.
Исследовать вопрос подробнее – вызов врача нарколога на дом новокузнецк
Врач уточняет продолжительность запоя, характер употребляемого алкоголя и наличие сопутствующих заболеваний. Детальное обследование позволяет оперативно подобрать необходимые медикаменты и минимизировать риск осложнений.
Получить дополнительные сведения – http://kapelnica-ot-zapoya-tyumen00.ru/
Запой может быть не только физически тяжёлым, но и психологически разрушительным. Поэтому важно вовремя обратиться за помощью. Вывод из запоя в Нижнем Новгороде — это необходимая медицинская процедура, которая помогает победить алкогольную зависимость и восстановить здоровье. Мы в клинике «АнтиЗависимость» предлагаем круглосуточную помощь в комфортных условиях — на дому или в стационаре.
Изучить вопрос глубже – нарколог на дом недорого новокузнецк
Экстренное вмешательство необходимо, когда самостоятельное прекращение употребления алкоголя или наркотиков становится невозможным, а состояние пациента ухудшается. Основные показания включают:
Подробнее тут – вызов нарколога на дом уфа
Всем рекомендую зайти на https://mfo-zaim.com/zaim-pod-zalog-avto/ — особенно в раздел, где Дмитрий Сверидов собрал лучшие предложения по займам. Там действительно низкие ставки, не маркетинг. Я оформил под 0.6% в сутки, никаких комиссий не списали. Всё как обещано.
Лечение зависимости требует не только физической детоксикации, но и работы с психоэмоциональным состоянием пациента. Психотерапевтическая поддержка помогает выявить глубинные причины зависимости, снизить уровень стресса и сформировать устойчивые навыки самоконтроля, что существенно снижает риск рецидивов.
Углубиться в тему – вызов нарколога на дом уфа
Услуга “Нарколог на дом” в Уфе охватывает широкий спектр лечебных мероприятий, направленных как на устранение токсической нагрузки, так и на работу с психоэмоциональным состоянием пациента. Комплексная терапия включает в себя медикаментозную детоксикацию, корректировку обменных процессов, а также психотерапевтическую поддержку, что позволяет не только вывести пациента из состояния запоя, но и помочь ему справиться с наркотической зависимостью.
Подробнее – вызов нарколога цена уфа
Когда следует немедленно обращаться за помощью:
Детальнее – https://narcolog-na-dom-novokuznetsk0.ru/narkolog-na-dom-czena-novokuzneczk
Хочу поблагодарить Викторию Данилову, ведущего копирайтера https://mfo-zaim.com/ . Её статьи действительно помогают. Особенно понравился материал про отказ от всех дополнительных платных услуг займов и что грозит за неуплату кредита. Всё по полочкам, с цифрами и понятным языком.
Врач уточняет продолжительность запоя, характер употребляемого алкоголя и наличие сопутствующих заболеваний. Детальное обследование позволяет оперативно подобрать необходимые медикаменты и минимизировать риск осложнений.
Детальнее – https://kapelnica-ot-zapoya-tyumen00.ru/kapelnicza-ot-zapoya-na-domu-tyumen
Процедура начинается с врачебного осмотра. Специалист оценивает общее состояние, артериальное давление, пульс, сатурацию, уровень обезвоживания, жалобы пациента. При необходимости проводятся экспресс-анализы. Далее индивидуально подбирается состав инфузионной терапии. В большинстве случаев капельница включает:
Подробнее можно узнать тут – kapelnica-ot-zapoya-moskva3.ru/
Применение современных капельничных методов позволяет точно дозировать лекарственные средства. Постоянный мониторинг жизненно важных показателей пациента дает возможность оперативно корректировать терапию для достижения оптимального эффекта и предотвращения побочных реакций.
Исследовать вопрос подробнее – https://vyvod-iz-zapoya-volgograd00.ru/vyvod-iz-zapoya-na-domu-volgograd/
Алкогольная и наркотическая зависимость требуют незамедлительного и комплексного вмешательства для предотвращения серьезных осложнений и сохранения здоровья пациента. В Уфе, Республика Башкортостан, опытные наркологи выезжают на дом 24 часа в сутки, предоставляя оперативную помощь при запоях и в случаях наркотической интоксикации. Такой формат лечения позволяет начать детоксикацию в комфортной, привычной обстановке, обеспечивая максимальную конфиденциальность и индивидуальный подход к каждому пациенту.
Узнать больше – http://narcolog-na-dom-ufa000.ru/narkolog-na-dom-kruglosutochno-ufa/
Незамедлительно после вызова нарколог прибывает на место для проведения первичной диагностики. На этом этапе осуществляется сбор анамнеза, измерение жизненно важных показателей и оценка степени интоксикации, что является основой для составления индивидуального плана лечения.
Ознакомиться с деталями – https://vyvod-iz-zapoya-volgograd000.ru/vyvod-iz-zapoya-kruglosutochno-volgograd
Запой может быть не только физически тяжёлым, но и психологически разрушительным. Поэтому важно вовремя обратиться за помощью. Вывод из запоя в Нижнем Новгороде — это необходимая медицинская процедура, которая помогает победить алкогольную зависимость и восстановить здоровье. Мы в клинике «АнтиЗависимость» предлагаем круглосуточную помощь в комфортных условиях — на дому или в стационаре.
Узнать больше – вызов врача нарколога на дом
Также страдают сердце и сосуды. У пациентов часто наблюдаются тахикардия, нестабильное давление, аритмии, повышенный риск инфаркта или инсульта. Система пищеварения реагирует воспалением: гастрит, панкреатит, тошнота, рвота. Все эти изменения усиливаются на фоне обезвоживания и электролитного дисбаланса. Именно поэтому стандартное «отлежаться» или домашнее лечение чаще всего оказывается неэффективным и даже опасным. Необходима полноценная капельная терапия — с грамотно подобранными препаратами и медицинским наблюдением.
Углубиться в тему – kapelnitsa ot zapoia
Городской портал Винницы https://u-misti.vinnica.ua новости, события и обзоры Винницы и области
В обзорной статье вы найдете собрание важных фактов и аналитики по самым разнообразным темам. Мы рассматриваем как современные исследования, так и исторические контексты, чтобы вы могли получить полное представление о предмете. Погрузитесь в мир знаний и сделайте шаг к пониманию!
Исследовать вопрос подробнее – https://oficinas.unsch.edu.pe/ocri/convenio-para-otorgamiento-de-prestamos-con-descuento-enplanilla-entre-la-universidad-nacional-de-san-cristobal-de-huamanga-einterbank
В этой публикации мы сосредоточимся на интересных аспектах одной из самых актуальных тем современности. Совмещая факты и мнения экспертов, мы создадим полное представление о предмете, которое будет полезно как новичкам, так и тем, кто глубоко изучает вопрос.
Подробнее можно узнать тут – https://sabahi-sabahi.com/2021/01/05/%E2%98%86%E9%BB%92%E8%B1%86%E2%98%86
В этой статье вы найдете познавательную и занимательную информацию, которая поможет вам лучше понять мир вокруг. Мы собрали интересные данные, которые вдохновляют на размышления и побуждают к действиям. Открывайте новую информацию и получайте удовольствие от чтения!
Подробнее – http://missmosey.com/urbansuite-life
В этом интересном тексте собраны обширные сведения, которые помогут вам понять различные аспекты обсуждаемой темы. Мы разбираем детали и факты, делая акцент на важности каждого элемента. Не упустите возможность расширить свои знания и взглянуть на мир по-новому!
Ознакомиться с деталями – https://mgeservice.com/buildings-under-construction
Портал Львів https://u-misti.lviv.ua останні новини Львова и области.
Свежие новости https://ktm.org.ua Украины и мира: политика, экономика, происшествия, культура, спорт. Оперативно, объективно, без фейков.
Сайт о строительстве https://solution-ltd.com.ua и дизайне: как построить, отремонтировать и оформить дом со вкусом.
Эта публикация содержит ценные советы и рекомендации по избавлению от зависимости. Мы обсуждаем различные стратегии, которые могут помочь в процессе выздоровления и важность обращения за помощью. Читатели смогут использовать полученные знания для улучшения своего состояния.
Разобраться лучше – narkolog-na-dom-kruglosutochno
Авто портал https://real-voice.info для всех, кто за рулём: свежие автоновости, обзоры моделей, тест-драйвы, советы по выбору, страхованию и ремонту.
В этой статье рассматриваются способы преодоления зависимости и успешные истории людей, которые справились с этой проблемой. Мы обсудим важность поддержки со стороны близких и профессионалов, а также стратегии, которые могут помочь в процессе выздоровления. Научитесь первоочередным шагам к новой жизни.
Подробнее можно узнать тут – врач нарколог на дом
В этой статье обсуждаются актуальные медицинские вопросы, которые волнуют общество. Мы обращаем внимание на проблемы, касающиеся здравоохранения и лечения, а также на новшества в области медицины. Читатели будут осведомлены о последних событиях и смогут следить за тенденциями в медицине.
Получить дополнительные сведения – нарколог на дом вывод из запоя
Строительный портал https://apis-togo.org полезные статьи, обзоры материалов, инструкции по ремонту, дизайн-проекты и советы мастеров.
Комплексный строительный https://ko-online.com.ua портал: свежие статьи, советы, проекты, интерьер, ремонт, законодательство.
Всё о строительстве https://furbero.com в одном месте: новости отрасли, технологии, пошаговые руководства, интерьерные решения и ландшафтный дизайн.
Новини Львів https://faine-misto.lviv.ua последние новости и события – Файне Львов
В этой статье мы обсудим процесс восстановления после зависимостей, акцентируя внимание на различных методах и подходах к реабилитации. Читатели узнают, как создать план выздоровления и использовать полезные ресурсы для достижения устойчивых изменений.
Получить дополнительную информацию – http://narkolog-na-dom-krasnodar12.ru/http://narkolog-na-dom-krasnodar12.ru
What a stuff of un-ambiguity and preserveness of precious knowledge concerning unexpected emotions.
Ranked as a top site in Bangladesh, 88fb login offers real rewards
Системы автоматизированного дозирования обеспечивают точное введение медикаментов, что минимизирует риск побочных эффектов. Постоянный мониторинг жизненно важных показателей позволяет врачу корректировать терапию в режиме реального времени, гарантируя безопасность процедуры.
Получить дополнительную информацию – владимир вывод из запоя
Современный женский https://prowoman.kyiv.ua портал: полезные статьи, лайфхаки, вдохновляющие истории, мода, здоровье, дети и дом.
Онлайн-портал https://leif.com.ua для женщин: мода, психология, рецепты, карьера, дети и любовь. Читай, вдохновляйся, общайся, развивайся!
«В первые часы после окончания запоя организм наиболее уязвим, и своевременное вмешательство значительно снижает риски осложнений», — подчёркивает заведующая отделением наркологической реанимации Елена Морозова.
Выяснить больше – vrach vyvod iz zapoya
Системы автоматизированного дозирования обеспечивают точное введение медикаментов, что минимизирует риск побочных эффектов. Постоянный мониторинг жизненно важных показателей позволяет врачу корректировать терапию в режиме реального времени, гарантируя безопасность процедуры.
Получить дополнительную информацию – http://
Портал о маркетинге https://reklamspilka.org.ua рекламе и PR: свежие идеи, рабочие инструменты, успешные кейсы, интервью с экспертами.
Сразу после вызова нарколог приезжает для проведения детального осмотра. На этом этапе производится сбор анамнеза, измеряются жизненно важные показатели – пульс, артериальное давление, температура – и оценивается степень интоксикации.
Подробнее можно узнать тут – вывод из запоя цены владимир
оригинальные горшки для цветов оригинальные горшки для цветов .
Этот документ охватывает важные аспекты медицинской науки, сосредотачиваясь на ключевых вопросах, касающихся здоровья населения. Мы рассматриваем свежие исследования, клинические рекомендации и лучшие практики, которые помогут улучшить качество лечения и профилактики заболеваний. Читатели получат возможность углубиться в различные медицинские дисциплины.
Исследовать вопрос подробнее – нарколог на дом
Этот медицинский обзор сосредоточен на последних достижениях, которые оказывают влияние на пациентов и медицинскую практику. Мы разбираем инновационные методы лечения и исследований, акцентируя внимание на их значимости для общественного здоровья. Читатели узнают о свежих данных и их возможном применении.
Получить больше информации – нарколог на дом вывод
Когда запой начинает угрожать здоровью, оперативное вмешательство становится жизненно необходимым. В Туле опытные специалисты оказывают помощь на дому, позволяя начать лечение сразу же в комфортной обстановке. Такой формат терапии обеспечивает оперативную детоксикацию, восстановление нормального обмена веществ и стабилизацию работы внутренних органов, что особенно важно для пациентов, желающих избежать лишнего стресса и сохранить конфиденциальность.
Ознакомиться с деталями – вывод из запоя в стационаре
Эта публикация исследует взаимосвязь зависимости и психологии. Мы обсудим, как психологические аспекты влияют на появление зависимостей и процесс выздоровления. Читатели смогут понять важность профессиональной поддержки и применения научных подходов в терапии.
Подробнее можно узнать тут – вызов нарколога на дом
В этом исследовании рассмотрены методы лечения зависимостей и их эффективность. Мы проанализируем различные подходы, используемые в реабилитационных центрах, и представим данные о результативности программ. Читатели получат надежные и научно обоснованные сведения о данной проблеме.
Получить больше информации – https://narkolog-na-dom-krasnodar11.ru/
Семейный портал https://stepandstep.com.ua статьи для родителей, игры и развивающие материалы для детей, советы психологов, лайфхаки.
Клуб родителей https://entertainment.com.ua пространство поддержки, общения и обмена опытом.
Туристический портал https://aliana.com.ua с лучшими маршрутами, подборками стран, бюджетными решениями, гидами и советами.
Всё о спорте https://beachsoccer.com.ua в одном месте: профессиональный и любительский спорт, фитнес, здоровье, техника упражнений и спортивное питание.
Комплексное лечение на дому организовано по четкой схеме, состоящей из последовательных этапов. Каждый из них направлен на быстрое восстановление нормального функционирования организма.
Подробнее можно узнать тут – нарколог на дом вывод из запоя владимир
Выбор помощи на дому имеет ряд значительных преимуществ:
Подробнее – нарколог вывод из запоя
Услуга вывода из запоя на дому в Туле представляет собой комплекс мер, направленных на экстренную детоксикацию организма при алкогольной интоксикации. При вызове нарколога специалист прибывает в течение короткого времени, проводит первичный осмотр, собирает анамнез и определяет степень интоксикации. На основе полученной информации разрабатывается индивидуальный план лечения, который может включать медикаментозную детоксикацию, капельничное введение препаратов и психотерапевтическую поддержку.
Детальнее – вывод из запоя на дому круглосуточно в туле
Медицинская публикация представляет собой свод актуальных исследований, экспертных мнений и новейших достижений в сфере здравоохранения. Здесь вы найдете информацию о новых методах лечения, прорывных технологиях и их практическом применении. Мы стремимся сделать актуальные медицинские исследования доступными и понятными для широкой аудитории.
Углубиться в тему – https://narkolog-na-dom-krasnodar11.ru/
Эта публикация исследует взаимосвязь зависимости и психологии. Мы обсудим, как психологические аспекты влияют на появление зависимостей и процесс выздоровления. Читатели смогут понять важность профессиональной поддержки и применения научных подходов в терапии.
Разобраться лучше – http://narkolog-na-dom-krasnodar15.ru/http://narkolog-na-dom-krasnodar15.ru
Специалист выясняет, как долго продолжается запой, какие симптомы наблюдаются, а также наличие сопутствующих заболеваний. Эти данные позволяют сформировать индивидуальный план лечения и выбрать оптимальные методы детоксикации.
Подробнее можно узнать тут – https://vyvod-iz-zapoya-vladimir0.ru
Эта публикация исследует взаимосвязь зависимости и психологии. Мы обсудим, как психологические аспекты влияют на появление зависимостей и процесс выздоровления. Читатели смогут понять важность профессиональной поддержки и применения научных подходов в терапии.
Ознакомиться с деталями – vyzvat-narkologa-na-dom
Запой характеризуется накоплением токсинов и ухудшением работы внутренних органов. Чем дольше продолжается состояние интоксикации, тем выше риск серьезных осложнений. Помощь нарколога на дому позволяет начать детоксикацию в первые часы кризиса, что существенно повышает шансы на успешное восстановление и предотвращает развитие хронических заболеваний.
Детальнее – вывести из запоя
Системы автоматизированного дозирования обеспечивают точное введение медикаментов, что минимизирует риск побочных эффектов. Постоянный мониторинг жизненно важных показателей позволяет врачу корректировать терапию в режиме реального времени, гарантируя безопасность процедуры.
Получить дополнительные сведения – вывод из запоя в владимире
Специалист выясняет, как долго продолжается запой, какие симптомы наблюдаются, а также наличие сопутствующих заболеваний. Эти данные позволяют сформировать индивидуальный план лечения и выбрать оптимальные методы детоксикации.
Получить дополнительную информацию – вывод из запоя на дому владимир круглосуточно
В этой статье представлен занимательный и актуальный контент, который заставит вас задуматься. Мы обсуждаем насущные вопросы и проблемы, а также освещаем истории, которые вдохновляют на действия и изменения. Узнайте, что стоит за событиями нашего времени!
Узнать больше – https://shiftlier.uitinlier.be/hallo-wereld
Этот информационный материал привлекает внимание множеством интересных деталей и необычных ракурсов. Мы предлагаем уникальные взгляды на привычные вещи и рассматриваем вопросы, которые волнуют общество. Будьте в курсе актуальных тем и расширяйте свои знания!
Подробнее – https://www.rajas.edu/believing-is-the-absence-of-doubt
Продолжительный запой приводит к накоплению токсинов, нарушению обменных процессов и ухудшению работы внутренних органов. Чем быстрее начинается лечение, тем ниже риск развития осложнений, таких как повреждение печени, почек, сердечно-сосудистые нарушения и нервные расстройства. Экстренная помощь нарколога на дому в Рязани позволяет приступить к терапии уже в первые часы кризиса, что является решающим для предотвращения необратимых изменений в организме.
Детальнее – vyzvat-narkologa-na-dom rjazan’
События Днепр https://u-misti.dp.ua последние новости Днепра и области, обзоры и самое интересное
После поступления в клинику проводится осмотр, измеряется давление, оценивается общее состояние. При необходимости проводятся экспресс-анализы на содержание веществ и ЭКГ.
Получить дополнительную информацию – https://narkologicheskaya-klinika-voronezh9.ru/
Новости Украины https://useti.org.ua в реальном времени. Всё важное — от официальных заявлений до мнений экспертов.
Информационный портал https://comart.com.ua о строительстве и ремонте: полезные советы, технологии, идеи, лайфхаки, расчёты и выбор материалов.
Архитектурный портал https://skol.if.ua современные проекты, урбанистика, дизайн, планировка, интервью с архитекторами и тренды отрасли.
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Получить дополнительные сведения – https://www.kachelswk.nl/blog/kosten-pelletkachel-plaatsen
Всё о строительстве https://ukrainianpages.com.ua просто и по делу. Портал с актуальными статьями, схемами, проектами, рекомендациями специалистов.
Эта статья предлагает живое освещение актуальной темы с множеством интересных фактов. Мы рассмотрим ключевые моменты, которые делают данную тему важной и актуальной. Подготовьтесь к насыщенному путешествию по неизвестным аспектам и узнайте больше о значимых событиях.
Исследовать вопрос подробнее – https://bulle-perpignan.fr/lapproche-snoezelen
Новости Украины https://hansaray.org.ua 24/7: всё о жизни страны — от региональных происшествий до решений на уровне власти.
Всё об автомобилях https://autoclub.kyiv.ua в одном месте. Обзоры, новости, инструкции по уходу, автоистории и реальные тесты.
Строительный журнал https://dsmu.com.ua идеи, технологии, материалы, дизайн, проекты, советы и обзоры. Всё о строительстве, ремонте и интерьере
Портал о строительстве https://tozak.org.ua от идеи до готового дома. Проекты, сметы, выбор материалов, ошибки и их решения.
Новостной портал Одесса https://u-misti.odesa.ua последние события города и области. Обзоры и много интресного о жизни в Одессе.
Клиника также предлагает долгосрочные программы, которые включают как стационарное, так и амбулаторное лечение. Мы понимаем, что восстановление требует не только медицинской помощи, но и значительной психологической поддержки на каждом этапе.
Получить дополнительные сведения – https://медицина-вывод-из-запоя.рф/vyvod-iz-zapoya-v-stacionare-v-nizhnem-novgoroge.xn--p1ai
Зависимость от психоактивных веществ — серьёзная проблема, которая становится всё актуальнее в современном мире. Алкоголизм, наркомания и игромания представляют угрозу как для здоровья отдельного человека, так и для общества в целом. В условиях растущей нагрузки на систему здравоохранения Наркологическая клиника “Возрождение” предлагает комплексные решения для тех, кто страдает от различных видов зависимости. Мы придерживаемся индивидуального подхода, что позволяет достигать высоких результатов в лечении и реабилитации.
Ознакомиться с деталями – https://медицина-вывод-из-запоя.рф/vyvod-iz-zapoya-v-stacionare-v-nizhnem-novgoroge.xn--p1ai
Наш подход охватывает все аспекты реабилитации, помогая пациентам справиться с зависимостями и вернуться к полноценной жизни.
Получить дополнительные сведения – http://медицина-вывод-из-запоя.рф
Its like you learn my thoughts! You seem to understand a lot approximately this, like you wrote the e book in it or something. I feel that you just could do with a few percent to pressure the message house a bit, however instead of that, that is magnificent blog. An excellent read. I will definitely be back.
This is a excellent blog, would you be interested in doing an interview regarding just how you designed it? If so e-mail me!
Городской портал Одессы https://faine-misto.od.ua последние новости и происшествия в городе и области
Новостной портал https://news24.in.ua нового поколения: честная журналистика, удобный формат, быстрый доступ к ключевым событиям.
Информационный портал https://dailynews.kyiv.ua актуальные новости, аналитика, интервью и спецтемы.
Портал для женщин https://a-k-b.com.ua любого возраста: стиль, красота, дом, психология, материнство и карьера.
Онлайн-новости https://arguments.kyiv.ua без лишнего: коротко, по делу, достоверно. Политика, бизнес, происшествия, спорт, лайфстайл.
Наш подход охватывает все аспекты реабилитации, помогая пациентам справиться с зависимостями и вернуться к полноценной жизни.
Изучить вопрос глубже – https://медицина-вывод-из-запоя.рф/vyvod-iz-zapoya-v-stacionare-v-nizhnem-novgoroge.xn--p1ai
Основное направление работы клиники – это комплексный подход, который включает медицинское лечение, психотерапию и социальную реабилитацию. Мы понимаем, что зависимость затрагивает не только физическое состояние, но и психологическое, поэтому используем методики когнитивно-поведенческой терапии, семейные консультации и групповые занятия. Такой подход помогает пациентам не только преодолеть зависимость, но и разобраться с её причинами и справиться с психологическими трудностями.
Подробнее можно узнать тут – https://быстро-вывод-из-запоя.рф/vyvod-iz-zapoya-v-kruglosutochno-v-volgograde.xn--p1ai
Наркологическая клиника “Возрождение” находится по адресу: ул. Агрономическая, д. 122А, г. Нижний Новгород, Россия. Мы открыты для вас круглосуточно и также предлагаем онлайн-консультации, чтобы сделать наши услуги более доступными.
Подробнее можно узнать тут – https://медицина-вывод-из-запоя.рф/vyvod-iz-zapoya-v-kruglosutochno-v-nizhnem-novgoroge.xn--p1ai/
Наркологическая клиника “Возрождение” находится по адресу: ул. Агрономическая, д. 122А, г. Нижний Новгород, Россия. Мы открыты для вас круглосуточно и также предлагаем онлайн-консультации, чтобы сделать наши услуги более доступными.
Подробнее тут – http://медицина-вывод-из-запоя.рф
Мировые новости https://ua-novosti.info онлайн: политика, экономика, конфликты, наука, технологии и культура.
Только главное https://ua-vestnik.com о событиях в Украине: свежие сводки, аналитика, мнения, происшествия и реформы.
Женский портал https://woman24.kyiv.ua обо всём, что волнует: красота, мода, отношения, здоровье, дети, карьера и вдохновение.
защитный кейс digitalrazor http://plastcase.ru
Наш подход охватывает все аспекты реабилитации, помогая пациентам справиться с зависимостями и вернуться к полноценной жизни.
Ознакомиться с деталями – https://медицина-вывод-из-запоя.рф/vyvod-iz-zapoya-v-stacionare-v-nizhnem-novgoroge.xn--p1ai
Зависимость от психоактивных веществ — серьёзная проблема, которая становится всё актуальнее в современном мире. Алкоголизм, наркомания и игромания представляют угрозу как для здоровья отдельного человека, так и для общества в целом. В условиях растущей нагрузки на систему здравоохранения Наркологическая клиника “Возрождение” предлагает комплексные решения для тех, кто страдает от различных видов зависимости. Мы придерживаемся индивидуального подхода, что позволяет достигать высоких результатов в лечении и реабилитации.
Получить больше информации – https://медицина-вывод-из-запоя.рф/vyvod-iz-zapoya-v-kruglosutochno-v-nizhnem-novgoroge.xn--p1ai/
Офисная мебель https://officepro54.ru в Новосибирске купить недорого от производителя
Интернет займы мфо взять займ
Миссия клиники — оказание комплексной помощи людям с зависимостями. Основные задачи, которые мы ставим перед собой:
Узнать больше – https://медицина-вывод-из-запоя.рф/vyvod-iz-zapoya-na-domu-v-nizhnem-novgoroge.xn--p1ai/
Мы создаем благоприятные условия для полного выздоровления и восстановления личности каждого пациента. Наша команда разрабатывает индивидуальные программы терапии, учитывая особенности здоровья и психического состояния человека. Лечение строится на научно обоснованных методах, что позволяет нам добиваться высоких результатов.
Разобраться лучше – http://быстро-вывод-из-запоя.рф/vyvod-iz-zapoya-v-kruglosutochno-v-volgograde.xn--p1ai/
Piano klavier noten klavier noten
Мы уделяем особое внимание индивидуальному подходу к каждому пациенту, понимая, что причины и проявления зависимости у всех разные. Тщательная диагностика позволяет учитывать медицинские, психологические и социальные аспекты каждого случая, на основе чего разрабатываются персонализированные программы лечения. Они включают медикаментозную терапию, психотерапевтические методы и мероприятия по социальной адаптации.
Изучить вопрос глубже – https://срочно-вывод-из-запоя.рф/vyvod-iz-zapoya-cena-v-chelyabinske.xn--p1ai
Клиника также предлагает долгосрочные программы, которые включают как стационарное, так и амбулаторное лечение. Мы понимаем, что восстановление требует не только медицинской помощи, но и значительной психологической поддержки на каждом этапе.
Узнать больше – https://медицина-вывод-из-запоя.рф
Зависимость от психоактивных веществ — серьёзная проблема, которая становится всё актуальнее в современном мире. Алкоголизм, наркомания и игромания представляют угрозу как для здоровья отдельного человека, так и для общества в целом. В условиях растущей нагрузки на систему здравоохранения Наркологическая клиника “Возрождение” предлагает комплексные решения для тех, кто страдает от различных видов зависимости. Мы придерживаемся индивидуального подхода, что позволяет достигать высоких результатов в лечении и реабилитации.
Исследовать вопрос подробнее – http://медицина-вывод-из-запоя.рф/vyvod-iz-zapoya-v-kruglosutochno-v-nizhnem-novgoroge.xn--p1ai/
Миссия клиники — оказание комплексной помощи людям с зависимостями. Основные задачи, которые мы ставим перед собой:
Выяснить больше – https://медицина-вывод-из-запоя.рф/vyvod-iz-zapoya-cena-v-nizhnem-novgoroge.xn--p1ai/
Миссия клиники — оказание комплексной помощи людям с зависимостями. Основные задачи, которые мы ставим перед собой:
Получить дополнительные сведения – https://медицина-вывод-из-запоя.рф
Медицинская публикация представляет собой свод актуальных исследований, экспертных мнений и новейших достижений в сфере здравоохранения. Здесь вы найдете информацию о новых методах лечения, прорывных технологиях и их практическом применении. Мы стремимся сделать актуальные медицинские исследования доступными и понятными для широкой аудитории.
Подробнее – https://kakbik.ru/zabolevaniya/narkologiya/mediczinskij-czentr-narkolog-ekspress-pomoshh-speczialistov-v-sankt-peterburge.html
Эта публикация обращает внимание на важность профилактики зависимостей. Мы обсудим, как осведомленность и образование могут помочь в предотвращении возникновения зависимости. Читатели смогут ознакомиться с полезными советами и ресурсами, которые способствуют здоровому образу жизни.
Получить дополнительные сведения – https://fem-style.ru/vyvod-iz-zapoya-na-domu-v-rostove-na-donu
В этой статье обсуждаются актуальные медицинские вопросы, которые волнуют общество. Мы обращаем внимание на проблемы, касающиеся здравоохранения и лечения, а также на новшества в области медицины. Читатели будут осведомлены о последних событиях и смогут следить за тенденциями в медицине.
Получить дополнительные сведения – https://coyotehookah.ru/kapelnica-ot-zapoya-v-rostove-na-donu
научиться кайтсерфингу Кайт школа Египет – это разнообразие программ обучения, от начального уровня до продвинутого.
Хмельницький новини https://u-misti.khmelnytskyi.ua огляди, новини, сайт Хмельницького
Этот увлекательный информационный материал подарит вам массу новых знаний и ярких эмоций. Мы собрали для вас интересные факты и сведения, которые обогатят ваш опыт. Откройте для себя увлекательный мир информации и насладитесь процессом изучения!
Углубиться в тему – https://healthyrrific.com/becoming-a-social-worker-the-first-year
Эта информационная статья охватывает широкий спектр актуальных тем и вопросов. Мы стремимся осветить ключевые факты и события с ясностью и простотой, чтобы каждый читатель мог извлечь из нее полезные знания и полезные инсайты.
Получить больше информации – https://jereparsdetoi.org/ar/blog/2020/05/30/r2
Heya i am for the first time here. I came across this board and I in finding It really useful & it helped me out much. I’m hoping to present one thing again and aid others like you aided me.
I have mastered some new issues from your website about computers. Another thing I’ve always presumed is that laptop computers have become something that each household must have for many people reasons. They provide convenient ways to organize the home, pay bills, shop, study, focus on music and in many cases watch television shows. An innovative method to complete most of these tasks has been a computer. These pcs are mobile ones, small, powerful and portable.
I don’t think the title of your article matches the content lol. Just kidding, mainly because I had some doubts after reading the article.
отчет по практике на заказ онлайн сколько стоит купить отчет по практике
Платформа AntiNarcoForum объединяет людей, нуждающихся в анонимной и квалифицированной помощи при игровой, алкогольной или наркотической зависимости. Форум предоставляет возможность получить консультации от специалистов и пообщаться с людьми, успешно справившимися с аналогичными проблемами.
Подробнее – наркотическая зависимость
сколько стоит реферат https://referatymehanika.ru
диплом срочно заказать помощь в написании диплома
Экстренная установка капельницы необходима, если пациент находится в состоянии запоя более 2–3 дней или испытывает симптомы тяжелой интоксикации алкоголем:
Разобраться лучше – капельница от запоя в сочи
Платформа AntiNarcoForum объединяет людей, нуждающихся в анонимной и квалифицированной помощи при игровой, алкогольной или наркотической зависимости. Форум предоставляет возможность получить консультации от специалистов и пообщаться с людьми, успешно справившимися с аналогичными проблемами.
Получить дополнительную информацию – лечение алкоголизма психологическими методами
Форум AntiNarcoForum — место, где зависимые и их близкие могут анонимно получить помощь профессионалов и участников сообщества. Здесь обсуждаются эффективные методы лечения зависимостей, личные истории успеха и конкретные советы по выходу из сложных ситуаций.
Выяснить больше – виды наркотической зависимости
Экстренная установка капельницы необходима, если пациент находится в состоянии запоя более 2–3 дней или испытывает симптомы тяжелой интоксикации алкоголем:
Подробнее – вызвать капельницу от запоя в сочи
Экстренная установка капельницы необходима, если пациент находится в состоянии запоя более 2–3 дней или испытывает симптомы тяжелой интоксикации алкоголем:
Изучить вопрос глубже – капельница от запоя выезд сочи
Медпортал https://medportal.co.ua украинский блог о медициние и здоровье. Новости, статьи, медицинские учреждения
После завершения процедур врач дает пациенту и его родственникам подробные рекомендации по дальнейшему восстановлению и профилактике рецидивов.
Получить больше информации – http://narcolog-na-dom-krasnodar00.ru/
Форум AntiNarcoForum — место, где зависимые и их близкие могут анонимно получить помощь профессионалов и участников сообщества. Здесь обсуждаются эффективные методы лечения зависимостей, личные истории успеха и конкретные советы по выходу из сложных ситуаций.
Получить дополнительную информацию – лечение алкоголизма по методу довженко
Своевременное обращение к специалисту позволяет избежать опасных осложнений и облегчить процесс восстановления организма. Экстренный вызов врача-нарколога необходим в следующих случаях:
Разобраться лучше – вызвать нарколога на дом
Чем раньше будет проведена процедура детоксикации, тем выше шансы избежать осложнений и быстрее восстановить здоровье пациента. Врачи клиники «ТрезвоПрофи» оперативно реагируют на вызовы, выезжая в любой район Сочи и прилегающие населенные пункты.
Подробнее – kapelnica-ot-zapoya-sochi00.ru/
Алкогольная и наркотическая зависимость являются серьёзными заболеваниями, требующими оперативного и квалифицированного вмешательства. Когда речь идёт о критическом состоянии пациента, особенно после длительного употребления алкоголя или наркотических веществ, время играет ключевую роль. Клиника «РеабилитАльянс» в Краснодаре предлагает услугу нарколога на дом, обеспечивая пациентам необходимую помощь в любой момент дня и ночи. Наши специалисты готовы оперативно выехать по указанному адресу и предоставить все необходимые медицинские процедуры на месте.
Изучить вопрос глубже – нарколог на дом цена в краснодаре
I don’t think the title of your article matches the content lol. Just kidding, mainly because I had some doubts after reading the article.
Капельница от запоя — это комплексная процедура, направленная на быстрое выведение токсинов, нормализацию обменных процессов и восстановление жизненно важных функций организма. Врачи-наркологи подбирают индивидуальный состав капельницы, исходя из состояния пациента. В стандартный набор препаратов обычно входят:
Получить дополнительные сведения – капельница от запоя цена сочи.
Thanks for sharing your info. I truly appreciate your efforts and I will be waiting for your next write ups thank you once again.
Terrorism
Файне Винница https://faine-misto.vinnica.ua новости и события Винницы сегодня. Городской портал, обзоры.
AntiNarcoForum — форум помощи при зависимостях, обеспечивающий анонимность и поддержку каждому участнику. Здесь доступны проверенные методики лечения, реальные истории выздоровления и профессиональные рекомендации специалистов для эффективного преодоления зависимости.
Получить дополнительную информацию – https://antinarcoforum.ru/alkogolizm/skrytyj-alkogolizm-kak-ponyat-chto-blizkij-v-bede/
После процедуры пациент чувствует значительное облегчение состояния, улучшение самочувствия и снижение тяги к алкоголю.
Ознакомиться с деталями – http://kapelnica-ot-zapoya-sochi00.ru/
При длительном запое в организме накапливаются вредные токсины, что ведёт к нарушениям работы сердца, печени, почек и других жизненно важных органов. Чем быстрее начинается терапия, тем выше шансы избежать серьёзных осложнений и обеспечить качественное восстановление. Метод капельничного лечения позволяет оперативно начать детоксикацию, что особенно важно для спасения жизни и предупреждения хронических последствий злоупотребления алкоголем.
Выяснить больше – http://
AntiNarcoForum — это онлайн-форум, созданный для тех, кто столкнулся с проблемой алкоголизма или наркомании. Анонимность, индивидуальный подход к каждому пользователю и квалифицированная поддержка делают форум эффективным инструментом в борьбе с зависимостью.
Подробнее – какие реабилитационные центры
взять онлайн займ на карту https://zajmy-onlajn.ru
Капельница от запоя — это комплексная процедура, направленная на быстрое выведение токсинов, нормализацию обменных процессов и восстановление жизненно важных функций организма. Врачи-наркологи подбирают индивидуальный состав капельницы, исходя из состояния пациента. В стандартный набор препаратов обычно входят:
Детальнее – врача капельницу от запоя в сочи
Врач устанавливает внутривенную капельницу, через которую вводятся специально подобранные препараты для очищения организма от алкоголя, восстановления баланса жидкости и нормализации работы всех органов и систем. В течение всей процедуры специалист следит за состоянием пациента и, при необходимости, корректирует терапию.
Детальнее – капельница от запоя клиника сочи
Выезд врача-нарколога из клиники «ТрезвоПрофи» на дом происходит в любое время суток, включая выходные и праздники. Перед началом детоксикации врач проводит осмотр, измеряет давление, частоту пульса, уровень кислорода в крови и подбирает индивидуальную схему лечения. Сама процедура обычно занимает от 1 до 2 часов и проводится под строгим контролем врача.
Получить дополнительные сведения – https://kapelnica-ot-zapoya-sochi00.ru/kapelnicza-ot-zapoya-detoks-sochi
Форум AntiNarcoForum — место, где зависимые и их близкие могут анонимно получить помощь профессионалов и участников сообщества. Здесь обсуждаются эффективные методы лечения зависимостей, личные истории успеха и конкретные советы по выходу из сложных ситуаций.
Получить больше информации – разговор с зависимым
При длительном запое в организме накапливаются вредные токсины, что ведёт к нарушениям работы сердца, печени, почек и других жизненно важных органов. Чем быстрее начинается терапия, тем выше шансы избежать серьёзных осложнений и обеспечить качественное восстановление. Метод капельничного лечения позволяет оперативно начать детоксикацию, что особенно важно для спасения жизни и предупреждения хронических последствий злоупотребления алкоголем.
Получить дополнительную информацию – капельница от запоя стоимость тюмень
I’m not sure exactly why but this web site is loading very slow for me. Is anyone else having this issue or is it a issue on my end? I’ll check back later on and see if the problem still exists.
Terrorism
После процедуры пациент чувствует значительное облегчение состояния, улучшение самочувствия и снижение тяги к алкоголю.
Получить дополнительные сведения – kapelnicza-ot-zapoya sochi
Форум AntiNarcoForum — место, где зависимые и их близкие могут анонимно получить помощь профессионалов и участников сообщества. Здесь обсуждаются эффективные методы лечения зависимостей, личные истории успеха и конкретные советы по выходу из сложных ситуаций.
Получить дополнительную информацию – пьянство и алкоголизм в семье
Капельница от запоя — это комплексная процедура, направленная на быстрое выведение токсинов, нормализацию обменных процессов и восстановление жизненно важных функций организма. Врачи-наркологи подбирают индивидуальный состав капельницы, исходя из состояния пациента. В стандартный набор препаратов обычно входят:
Получить дополнительную информацию – капельница от запоя цена краснодарский край
Платформа AntiNarcoForum объединяет людей, нуждающихся в анонимной и квалифицированной помощи при игровой, алкогольной или наркотической зависимости. Форум предоставляет возможность получить консультации от специалистов и пообщаться с людьми, успешно справившимися с аналогичными проблемами.
Углубиться в тему – физическая наркотическая зависимость
Выезд врача-нарколога из клиники «ТрезвоПрофи» на дом происходит в любое время суток, включая выходные и праздники. Перед началом детоксикации врач проводит осмотр, измеряет давление, частоту пульса, уровень кислорода в крови и подбирает индивидуальную схему лечения. Сама процедура обычно занимает от 1 до 2 часов и проводится под строгим контролем врача.
Разобраться лучше – капельница от запоя цена краснодарский край
Экстренная установка капельницы необходима, если пациент находится в состоянии запоя более 2–3 дней или испытывает симптомы тяжелой интоксикации алкоголем:
Изучить вопрос глубже – https://kapelnica-ot-zapoya-sochi00.ru/kapelnicza-ot-zapoya-na-domu-sochi/
AntiNarcoForum — это онлайн-форум, созданный для тех, кто столкнулся с проблемой алкоголизма или наркомании. Анонимность, индивидуальный подход к каждому пользователю и квалифицированная поддержка делают форум эффективным инструментом в борьбе с зависимостью.
Получить дополнительные сведения – реабилитация после алкоголизма
AntiNarcoForum — это онлайн-форум, созданный для тех, кто столкнулся с проблемой алкоголизма или наркомании. Анонимность, индивидуальный подход к каждому пользователю и квалифицированная поддержка делают форум эффективным инструментом в борьбе с зависимостью.
Выяснить больше – созависимые алкоголиков советы психолога
Когда запой превращается в угрозу для жизни, оперативное вмешательство становится критически важным. В Тюмени, Тюменская область, опытные наркологи предлагают услугу установки капельницы от запоя прямо на дому. Такой метод позволяет начать детоксикацию с использованием современных медикаментов, что способствует быстрому выведению токсинов, восстановлению обменных процессов и нормализации работы внутренних органов. Лечение на дому обеспечивает комфортную обстановку, полную конфиденциальность и индивидуальный подход к каждому пациенту.
Подробнее – https://kapelnica-ot-zapoya-tyumen00.ru/kapelnicza-ot-zapoya-na-domu-czena-tyumen
После процедуры пациент чувствует значительное облегчение состояния, улучшение самочувствия и снижение тяги к алкоголю.
Изучить вопрос глубже – капельница от запоя анонимно в сочи
Как отмечает врач-нарколог клиники «РеабилитАльянс» Павел Сомов, «чем раньше начато лечение, тем выше шансы на скорейшее выздоровление без серьезных последствий для здоровья».
Подробнее тут – http://narcolog-na-dom-krasnodar00.ru/vyzov-narkologa-na-dom-krasnodar/https://narcolog-na-dom-krasnodar00.ru
AntiNarcoForum — это онлайн-форум, созданный для тех, кто столкнулся с проблемой алкоголизма или наркомании. Анонимность, индивидуальный подход к каждому пользователю и квалифицированная поддержка делают форум эффективным инструментом в борьбе с зависимостью.
Получить дополнительную информацию – рецидив алкоголизма это
После процедуры пациент чувствует значительное облегчение состояния, улучшение самочувствия и снижение тяги к алкоголю.
Подробнее – капельница от запоя вызов в сочи
Форум AntiNarcoForum — место, где зависимые и их близкие могут анонимно получить помощь профессионалов и участников сообщества. Здесь обсуждаются эффективные методы лечения зависимостей, личные истории успеха и конкретные советы по выходу из сложных ситуаций.
Получить дополнительные сведения – созависимость при алкоголизме
Find real stories and advice from people in recovery on this forum.
Get details – drug addiction forum
Алкогольная и наркотическая зависимость являются серьёзными заболеваниями, требующими оперативного и квалифицированного вмешательства. Когда речь идёт о критическом состоянии пациента, особенно после длительного употребления алкоголя или наркотических веществ, время играет ключевую роль. Клиника «РеабилитАльянс» в Краснодаре предлагает услугу нарколога на дом, обеспечивая пациентам необходимую помощь в любой момент дня и ночи. Наши специалисты готовы оперативно выехать по указанному адресу и предоставить все необходимые медицинские процедуры на месте.
Углубиться в тему – [url=https://narcolog-na-dom-krasnodar00.ru/]vrach-narkolog-na-dom krasnodar[/url]
A helpful resource for anyone facing substance abuse, dual diagnosis, or post-rehab life.
Get more information – talk to others in recovery online
После процедуры пациент чувствует значительное облегчение состояния, улучшение самочувствия и снижение тяги к алкоголю.
Изучить вопрос глубже – postavit-kapelniczu-ot-zapoya sochi
Автогид https://avtogid.in.ua автомобильный украинский портал с новостями, обзорами, советами для автовладельцев
AntiNarcoForum — это онлайн-форум, созданный для тех, кто столкнулся с проблемой алкоголизма или наркомании. Анонимность, индивидуальный подход к каждому пользователю и квалифицированная поддержка делают форум эффективным инструментом в борьбе с зависимостью.
Изучить вопрос глубже – страдает наркотической зависимостью
Discover a non-judgmental environment to talk about relapse, recovery, and starting over.
Get more info – forum for children of addicts
заказать контрольную по химии заказать работу онлайн недорого
После завершения процедур врач дает пациенту и его родственникам подробные рекомендации по дальнейшему восстановлению и профилактике рецидивов.
Подробнее тут – нарколог на дом срочно в краснодаре
Find real stories and advice from people in recovery on this forum.
Explore further – co-occurring disorders forum
Портал Киева https://u-misti.kyiv.ua новости и события в Киеве сегодня.
A helpful resource for anyone facing substance abuse, dual diagnosis, or post-rehab life.
Learn more here – what to expect during drug detox
Book affordable and professional AC duct cleaning services in Dubai for your villa or apartment: ac duct cleaning abu dhabi cost
Врач устанавливает внутривенную капельницу, через которую вводятся специально подобранные препараты для очищения организма от алкоголя, восстановления баланса жидкости и нормализации работы всех органов и систем. В течение всей процедуры специалист следит за состоянием пациента и, при необходимости, корректирует терапию.
Детальнее – вызвать капельницу от запоя на дому в сочи
Выезд врача-нарколога из клиники «ТрезвоПрофи» на дом происходит в любое время суток, включая выходные и праздники. Перед началом детоксикации врач проводит осмотр, измеряет давление, частоту пульса, уровень кислорода в крови и подбирает индивидуальную схему лечения. Сама процедура обычно занимает от 1 до 2 часов и проводится под строгим контролем врача.
Получить дополнительные сведения – вызвать капельницу от запоя в сочи
Whether it’s alcohol, drugs, or emotional recovery — this space offers guidance and support.
More information – addiction recovery forum
Выезд врача-нарколога из клиники «ТрезвоПрофи» на дом происходит в любое время суток, включая выходные и праздники. Перед началом детоксикации врач проводит осмотр, измеряет давление, частоту пульса, уровень кислорода в крови и подбирает индивидуальную схему лечения. Сама процедура обычно занимает от 1 до 2 часов и проводится под строгим контролем врача.
Детальнее – капельница от запоя вызов город
Struggling with addiction or know someone who is? Join the conversation here.
Explore more – alcohol detox support group
Как отмечает врач-нарколог клиники «РеабилитАльянс» Павел Сомов, «чем раньше начато лечение, тем выше шансы на скорейшее выздоровление без серьезных последствий для здоровья».
Получить больше информации – http://narcolog-na-dom-krasnodar00.ru/narkolog-na-dom-kruglosutochno-krasnodar/
Чем раньше будет проведена процедура детоксикации, тем выше шансы избежать осложнений и быстрее восстановить здоровье пациента. Врачи клиники «ТрезвоПрофи» оперативно реагируют на вызовы, выезжая в любой район Сочи и прилегающие населенные пункты.
Разобраться лучше – http://kapelnica-ot-zapoya-sochi00.ru
Платформа AntiNarcoForum объединяет людей, нуждающихся в анонимной и квалифицированной помощи при игровой, алкогольной или наркотической зависимости. Форум предоставляет возможность получить консультации от специалистов и пообщаться с людьми, успешно справившимися с аналогичными проблемами.
Подробнее – профилактика рецидивов алкоголизма
Алкогольная и наркотическая зависимость являются серьёзными заболеваниями, требующими оперативного и квалифицированного вмешательства. Когда речь идёт о критическом состоянии пациента, особенно после длительного употребления алкоголя или наркотических веществ, время играет ключевую роль. Клиника «РеабилитАльянс» в Краснодаре предлагает услугу нарколога на дом, обеспечивая пациентам необходимую помощь в любой момент дня и ночи. Наши специалисты готовы оперативно выехать по указанному адресу и предоставить все необходимые медицинские процедуры на месте.
Изучить вопрос глубже – https://narcolog-na-dom-krasnodar00.ru/narkolog-na-dom-kruglosutochno-krasnodar
Платформа AntiNarcoForum объединяет людей, нуждающихся в анонимной и квалифицированной помощи при игровой, алкогольной или наркотической зависимости. Форум предоставляет возможность получить консультации от специалистов и пообщаться с людьми, успешно справившимися с аналогичными проблемами.
Подробнее – лечение алкоголизма по методу довженко
После процедуры пациент чувствует значительное облегчение состояния, улучшение самочувствия и снижение тяги к алкоголю.
Ознакомиться с деталями – вызвать капельницу от запоя на дому
Find real stories and advice from people in recovery on this forum.
More information – online support for families of alcoholics
Платформа AntiNarcoForum объединяет людей, нуждающихся в анонимной и квалифицированной помощи при игровой, алкогольной или наркотической зависимости. Форум предоставляет возможность получить консультации от специалистов и пообщаться с людьми, успешно справившимися с аналогичными проблемами.
Подробнее – наркозависимость это
контрольная по бухучету цена контрольной работы криминалистика
диплом срочно где заказать дипломную работу
написать отчет по практике цена https://otchetbuhgalter.ru
взять микрозаем zajmy onlajn
Процедура выезда врача на дом в Краснодаре строго регламентирована и включает несколько последовательных этапов. После поступления звонка и уточнения подробностей состояния пациента врач выезжает на место в течение 30–60 минут. На месте проводится первичный осмотр с оценкой жизненно важных показателей: артериального давления, уровня кислорода в крови, сердечного ритма и степени общей интоксикации.
Выяснить больше – https://narcolog-na-dom-krasnodar00.ru/narkolog-na-dom-czena-krasnodar/
Платформа AntiNarcoForum объединяет людей, нуждающихся в анонимной и квалифицированной помощи при игровой, алкогольной или наркотической зависимости. Форум предоставляет возможность получить консультации от специалистов и пообщаться с людьми, успешно справившимися с аналогичными проблемами.
Подробнее тут – помощь алкоголикам
Выезд врача-нарколога из клиники «ТрезвоПрофи» на дом происходит в любое время суток, включая выходные и праздники. Перед началом детоксикации врач проводит осмотр, измеряет давление, частоту пульса, уровень кислорода в крови и подбирает индивидуальную схему лечения. Сама процедура обычно занимает от 1 до 2 часов и проводится под строгим контролем врача.
Подробнее – http://kapelnica-ot-zapoya-sochi00.ru/kapelnicza-ot-zapoya-na-domu-sochi/https://kapelnica-ot-zapoya-sochi00.ru
Когда запой превращается в угрозу для жизни, оперативное вмешательство становится критически важным. В Тюмени, Тюменская область, опытные наркологи предлагают услугу установки капельницы от запоя прямо на дому. Такой метод позволяет начать детоксикацию с использованием современных медикаментов, что способствует быстрому выведению токсинов, восстановлению обменных процессов и нормализации работы внутренних органов. Лечение на дому обеспечивает комфортную обстановку, полную конфиденциальность и индивидуальный подход к каждому пациенту.
Подробнее можно узнать тут – капельница от запоя тюмень
Whether it’s alcohol, drugs, or emotional recovery — this space offers guidance and support.
Get more info – drug rehab discussion board
При длительном запое в организме накапливаются вредные токсины, что ведёт к нарушениям работы сердца, печени, почек и других жизненно важных органов. Чем быстрее начинается терапия, тем выше шансы избежать серьёзных осложнений и обеспечить качественное восстановление. Метод капельничного лечения позволяет оперативно начать детоксикацию, что особенно важно для спасения жизни и предупреждения хронических последствий злоупотребления алкоголем.
Получить больше информации – капельница от запоя в тюмени
Алкогольная и наркотическая зависимость являются серьёзными заболеваниями, требующими оперативного и квалифицированного вмешательства. Когда речь идёт о критическом состоянии пациента, особенно после длительного употребления алкоголя или наркотических веществ, время играет ключевую роль. Клиника «РеабилитАльянс» в Краснодаре предлагает услугу нарколога на дом, обеспечивая пациентам необходимую помощь в любой момент дня и ночи. Наши специалисты готовы оперативно выехать по указанному адресу и предоставить все необходимые медицинские процедуры на месте.
Исследовать вопрос подробнее – http://narcolog-na-dom-krasnodar00.ru/narkolog-na-dom-czena-krasnodar/
После процедуры пациент чувствует значительное облегчение состояния, улучшение самочувствия и снижение тяги к алкоголю.
Детальнее – https://kapelnica-ot-zapoya-sochi00.ru/kapelnicza-ot-zapoya-czena-sochi
AntiNarcoForum — анонимное сообщество помощи людям, страдающим от алкогольной, наркотической и игровой зависимости. На платформе доступны истории выздоровления, консультации специалистов, а также постоянная поддержка от людей, преодолевших схожие трудности.
Исследовать вопрос подробнее – алкоголизм
Чем раньше будет проведена процедура детоксикации, тем выше шансы избежать осложнений и быстрее восстановить здоровье пациента. Врачи клиники «ТрезвоПрофи» оперативно реагируют на вызовы, выезжая в любой район Сочи и прилегающие населенные пункты.
Получить больше информации – http://kapelnica-ot-zapoya-sochi00.ru/kapelnicza-ot-zapoya-detoks-sochi/
После завершения процедур врач дает пациенту и его родственникам подробные рекомендации по дальнейшему восстановлению и профилактике рецидивов.
Изучить вопрос глубже – нарколог на дом цена
Выбор капельничного метода в условиях домашнего лечения обладает рядом преимуществ:
Разобраться лучше – капельница от запоя на дому тюмень
AntiNarcoForum — форум помощи при зависимостях, обеспечивающий анонимность и поддержку каждому участнику. Здесь доступны проверенные методики лечения, реальные истории выздоровления и профессиональные рекомендации специалистов для эффективного преодоления зависимости.
Получить дополнительную информацию – antinarcoforum.ru
Процедура выезда врача на дом в Краснодаре строго регламентирована и включает несколько последовательных этапов. После поступления звонка и уточнения подробностей состояния пациента врач выезжает на место в течение 30–60 минут. На месте проводится первичный осмотр с оценкой жизненно важных показателей: артериального давления, уровня кислорода в крови, сердечного ритма и степени общей интоксикации.
Подробнее тут – https://narcolog-na-dom-krasnodar00.ru/
Своевременное обращение к специалисту позволяет избежать опасных осложнений и облегчить процесс восстановления организма. Экстренный вызов врача-нарколога необходим в следующих случаях:
Подробнее тут – вызов врача нарколога на дом
AntiNarcoForum — анонимное сообщество помощи людям, страдающим от алкогольной, наркотической и игровой зависимости. На платформе доступны истории выздоровления, консультации специалистов, а также постоянная поддержка от людей, преодолевших схожие трудности.
Исследовать вопрос подробнее – зависимость и созависимость это
Врач уточняет продолжительность запоя, характер употребляемого алкоголя и наличие сопутствующих заболеваний. Детальное обследование позволяет оперативно подобрать необходимые медикаменты и минимизировать риск осложнений.
Подробнее – http://kapelnica-ot-zapoya-tyumen00.ru/
Сайт Житомир https://u-misti.zhitomir.ua новости и происшествия в Житомире и области
Алкогольная и наркотическая зависимость являются серьёзными заболеваниями, требующими оперативного и квалифицированного вмешательства. Когда речь идёт о критическом состоянии пациента, особенно после длительного употребления алкоголя или наркотических веществ, время играет ключевую роль. Клиника «РеабилитАльянс» в Краснодаре предлагает услугу нарколога на дом, обеспечивая пациентам необходимую помощь в любой момент дня и ночи. Наши специалисты готовы оперативно выехать по указанному адресу и предоставить все необходимые медицинские процедуры на месте.
Выяснить больше – https://narcolog-na-dom-krasnodar00.ru/narkolog-na-dom-czena-krasnodar/
Женский блог https://zhinka.in.ua Жінка это самое интересное о красоте, здоровье, отношениях. Много полезной информации для женщин.
шторы день ночь Штора без излишеств – это простота и элегантность в каждой детали. Шторы своими руками
После процедуры пациент чувствует значительное облегчение состояния, улучшение самочувствия и снижение тяги к алкоголю.
Подробнее можно узнать тут – капельница от запоя на дому сочи.
Капельница от запоя — это комплексная процедура, направленная на быстрое выведение токсинов, нормализацию обменных процессов и восстановление жизненно важных функций организма. Врачи-наркологи подбирают индивидуальный состав капельницы, исходя из состояния пациента. В стандартный набор препаратов обычно входят:
Получить дополнительные сведения – капельница от запоя краснодарский край
После процедуры пациент чувствует значительное облегчение состояния, улучшение самочувствия и снижение тяги к алкоголю.
Подробнее можно узнать тут – http://kapelnica-ot-zapoya-sochi00.ru/kapelnicza-ot-zapoya-na-domu-sochi/https://kapelnica-ot-zapoya-sochi00.ru
После процедуры пациент чувствует значительное облегчение состояния, улучшение самочувствия и снижение тяги к алкоголю.
Подробнее тут – врача капельницу от запоя в сочи
После процедуры пациент чувствует значительное облегчение состояния, улучшение самочувствия и снижение тяги к алкоголю.
Получить дополнительные сведения – вызвать капельницу от запоя на дому в сочи
После завершения процедур врач дает пациенту и его родственникам подробные рекомендации по дальнейшему восстановлению и профилактике рецидивов.
Углубиться в тему – нарколог на дом вывод из запоя
Выезд врача-нарколога из клиники «ТрезвоПрофи» на дом происходит в любое время суток, включая выходные и праздники. Перед началом детоксикации врач проводит осмотр, измеряет давление, частоту пульса, уровень кислорода в крови и подбирает индивидуальную схему лечения. Сама процедура обычно занимает от 1 до 2 часов и проводится под строгим контролем врача.
Детальнее – http://kapelnica-ot-zapoya-sochi00.ru
AntiNarcoForum — форум помощи при зависимостях, обеспечивающий анонимность и поддержку каждому участнику. Здесь доступны проверенные методики лечения, реальные истории выздоровления и профессиональные рекомендации специалистов для эффективного преодоления зависимости.
Детальнее – как выбрать реабилитационный центр для наркозависимых
Thank you for your sharing. I am worried that I lack creative ideas. It is your article that makes me full of hope. Thank you. But, I have a question, can you help me?
AntiNarcoForum — анонимное сообщество помощи людям, страдающим от алкогольной, наркотической и игровой зависимости. На платформе доступны истории выздоровления, консультации специалистов, а также постоянная поддержка от людей, преодолевших схожие трудности.
Получить дополнительную информацию – общение с зависимыми людьми
Комплексное лечение организовано по строго отлаженной схеме, которая включает несколько последовательных этапов, позволяющих обеспечить оперативное и безопасное восстановление организма.
Выяснить больше – капельница от запоя на дому в тюмени
AntiNarcoForum — это онлайн-форум, созданный для тех, кто столкнулся с проблемой алкоголизма или наркомании. Анонимность, индивидуальный подход к каждому пользователю и квалифицированная поддержка делают форум эффективным инструментом в борьбе с зависимостью.
Ознакомиться с деталями – лечится ли женский алкоголизм
варфейс купить Рынок аккаунтов Warface предлагает широкий выбор: от новичков с базовым снаряжением до опытных ветеранов с прокачанными персонажами и редким оружием. Выбор за вами! Аккаунты Варфейс
аренда машины краснодар Прокат авто без залога: Начните свою поездку без лишних финансовых обременений.
AntiNarcoForum — это онлайн-форум, созданный для тех, кто столкнулся с проблемой алкоголизма или наркомании. Анонимность, индивидуальный подход к каждому пользователю и квалифицированная поддержка делают форум эффективным инструментом в борьбе с зависимостью.
Получить дополнительную информацию – этапы формирования наркотической зависимости
Выезд врача-нарколога из клиники «ТрезвоПрофи» на дом происходит в любое время суток, включая выходные и праздники. Перед началом детоксикации врач проводит осмотр, измеряет давление, частоту пульса, уровень кислорода в крови и подбирает индивидуальную схему лечения. Сама процедура обычно занимает от 1 до 2 часов и проводится под строгим контролем врача.
Углубиться в тему – капельница от запоя цена сочи
Натяжной потолок в кухню Фото натяжных потолков помогут вам выбрать подходящий дизайн и оценить возможности различных материалов и конструкций. Натяжные потолки можно
Нужен ремонт посудомоечной машины? Мы справимся.
С нами ремонт становится проще.
При длительном запое в организме накапливаются вредные токсины, что ведёт к нарушениям работы сердца, печени, почек и других жизненно важных органов. Чем быстрее начинается терапия, тем выше шансы избежать серьёзных осложнений и обеспечить качественное восстановление. Метод капельничного лечения позволяет оперативно начать детоксикацию, что особенно важно для спасения жизни и предупреждения хронических последствий злоупотребления алкоголем.
Детальнее – http://kapelnica-ot-zapoya-tyumen00.ru/kapelnicza-ot-zapoya-na-domu-tyumen/
AntiNarcoForum — анонимное сообщество помощи людям, страдающим от алкогольной, наркотической и игровой зависимости. На платформе доступны истории выздоровления, консультации специалистов, а также постоянная поддержка от людей, преодолевших схожие трудности.
Ознакомиться с деталями – наркологическая реабилитация центр
Настенный кондиционер https://brand-climat.ru точный контроль климата и экономия энергии. Широкий выбор сплит-систем, установка, гарантия и консультация специалистов. Комфорт в доме без лишних затрат!
Эта публикация погружает вас в мир увлекательных фактов и удивительных открытий. Мы расскажем о ключевых событиях, которые изменили ход истории, и приоткроем завесу над научными достижениями, которые вдохновили миллионы. Узнайте, чему может научить нас прошлое и как применить эти знания в будущем.
Выяснить больше – http://izmirtenisokulu.com/?p=400
Бездепозитные бонусы Перед тем, как воспользоваться бездепозитным бонусом, стоит внимательно изучить условия его получения и отыгрыша. Важно понимать, какие игры доступны для игры на бонусные средства, какой вейджер необходимо выполнить, чтобы вывести выигрыш, и какие сроки установлены для отыгрыша бонуса. Тщательное изучение правил поможет избежать разочарований и получить максимальную выгоду от использования бонуса.
В этой статье собраны факты, которые освещают целый ряд важных вопросов. Мы стремимся предложить читателям четкую, достоверную информацию, которая поможет сформировать собственное мнение и лучше понять сложные аспекты рассматриваемой темы.
Исследовать вопрос подробнее – http://www.nostalgia.maniowy.net/historia-wsi/category/43-przesiedlenie?tmpl=component&print=1&start=4140
Этот информативный текст отличается привлекательным содержанием и актуальными данными. Мы предлагаем читателям взглянуть на привычные вещи под новым углом, предоставляя интересный и доступный материал. Получите удовольствие от чтения и расширьте кругозор!
Подробнее можно узнать тут – http://canellecrea.ovh/project/illustration-pack
Эта разъяснительная статья содержит простые и доступные разъяснения по актуальным вопросам. Мы стремимся сделать информацию понятной для широкой аудитории, чтобы каждый смог разобраться в предмете и извлечь из него максимум пользы.
Подробнее можно узнать тут – https://foreningen.svenskhemslojd.com/product/ninja-silhouette-2
Эта публикация содержит ценные советы и рекомендации по избавлению от зависимости. Мы обсуждаем различные стратегии, которые могут помочь в процессе выздоровления и важность обращения за помощью. Читатели смогут использовать полученные знания для улучшения своего состояния.
Ознакомиться с деталями – https://aqua-pit.ru/vyezd-narkologa-na-dom-dovertes-professionalam
Этот обзорный материал предоставляет информационно насыщенные данные, касающиеся актуальных тем. Мы стремимся сделать информацию доступной и структурированной, чтобы читатели могли легко ориентироваться в наших выводах. Познайте новое с нашим обзором!
Исследовать вопрос подробнее – https://bgcompanyinc.com/2024/07/28/hello-world
Эта информационная заметка содержит увлекательные сведения, которые могут вас удивить! Мы собрали интересные факты, которые сделают вашу жизнь ярче и полнее. Узнайте нечто новое о привычных аспектах повседневности и откройте для себя удивительный мир информации.
Подробнее – https://annikas.space/class/flow-fuer-einen-kraeftigen-ruecken
Украинский бизнес https://in-ukraine.biz.ua информацинный портал о бизнесе, финансах, налогах, своем деле в Украине
Репетитор по физике https://repetitor-po-fizike-spb.ru СПб: школьникам и студентам, с нуля и для олимпиад. Четкие объяснения, практика, реальные результаты.
Лучшие онлайн-курсы https://topkursi.ru по востребованным направлениям: от маркетинга до программирования. Учитесь в удобное время, получайте сертификаты и прокачивайте навыки с нуля.
Школа Саморазвития https://bznaniy.ru онлайн-база знаний для тех, кто хочет понять себя, улучшить мышление, прокачать навыки и выйти на новый уровень жизни.
1000 рублей за регистрацию в казино без депозита вывод сразу Бездепозитный бонус в размере 1000 рублей с моментальным выводом – это редкая и ценная находка для азартных игроков. Она позволяет начать игру, не вкладывая собственные средства, и сразу же вывести выигрыш, если повезет. 1000 рублей за регистрацию вывод сразу без вложений
спины за регистрацию в подарок без депозита Многие игроки ищут именно такие бонусы, которые позволяют сразу вывести выигранные деньги, не вкладывая свои. Но стоит помнить о лимитах и правилах казино.
Перевод документов https://medicaltranslate.ru на немецкий язык для лечения за границей и с немецкого после лечения: высокая скорость, безупречность, 24/7
shipping from china to dubai China to UAE Shipping: Finding the Right Freight Forwarder for Your Needs
Онлайн-тренинги https://communication-school.ru и курсы для личного роста, карьеры и новых навыков. Учитесь в удобное время из любой точки мира.
1С без сложностей https://1s-legko.ru объясняем простыми словами. Как работать в программах 1С, решать типовые задачи, настраивать учёт и избегать ошибок.
https://dettka.com/piony-s-dostavkoj-po-moskve-krasota-i-udobstvo-v-vashem-dome/ Доставка пионов в Москве: Изысканное прикосновение к совершенству. Ощутите нежность шелковистых лепестков, представьте тонкий аромат, наполняющий пространство, и осознайте, что роскошь может быть доступной. Мы предлагаем не просто доставку цветов, а создание момента, который запомнится надолго. Наша коллекция включает в себя редкие сорта пионов, отобранные с особой тщательностью, чтобы удовлетворить даже самый изысканный вкус. От классических розовых букетов до смелых композиций с экзотическими оттенками – у нас вы найдете идеальный подарок для любого случая. Мы ценим ваше время, поэтому гарантируем быструю и надежную доставку по Москве.
наркологическая клиника цены https://narkologiya-nn.ru
фото пансионата для пожилых пансионат для пожилых людей
скачать игры по прямой ссылке Скачать игры без торрента: Откройте мир развлечений без ограничений. Забудьте о медленных загрузках и проблемах с сидированием. Теперь вы можете мгновенно погрузиться в захватывающие игровые миры, скачивая любимые игры напрямую, без использования торрент-клиентов. Наслаждайтесь быстрой и стабильной загрузкой, которая позволит вам не терять время на ожидание, а сразу окунуться в игровой процесс. Исследуйте обширную библиотеку игр различных жанров и найдите новые приключения, не утруждая себя поиском рабочих торрент-файлов.
Do you mind if I quote a few of your posts as long as I provide credit and sources back to your webpage? My blog site is in the very same area of interest as yours and my visitors would definitely benefit from some of the information you present here. Please let me know if this okay with you. Thank you!
Just desire to say your article is as surprising. The clarity in your post is simply great and i can assume you are an expert on this subject. Fine with your permission allow me to grab your RSS feed to keep updated with forthcoming post. Thanks a million and please keep up the rewarding work.
Лунные день сегодня https://www.inforigin.ru .
Какой сегодня праздник http://istoriamashin.ru .
Календарь стрижек http://topoland.ru .
нужен юрист онлайн онлайн консультация юриста 24 часа бесплатно
типографии спб недорого типография официальный сайт
типография официальный сайт типография официальный сайт
изготовление металлических значков металлический значок пин
check out https://s3.amazonaws.com/photovoltaik-buchloe/unlocking-the-secrets-of-photovoltaik-buchloe-a-complete-guide.html
стиральная машина не набирает воду алматы Заправка фреоном холодильника Алматы: Заправка холодильника фреоном на дому. Быстрый и безопасный способ восстановить работоспособность вашего холодильника.
металлический значок пин металлический значок пин
море в хургаде Образцы изображений сертификата выданного студенту в кайкеринге: примеры Образцы изображений сертификата, выданного студенту в кайтсерфинге: необходимо обратиться в официальные кайт школы.
– А между тем удивляться нечему. Быстроденьги Тверь: способы получения и особенности – Микрозаймы ИНФО В полутьме что-то тускло отсвечивало.
1000 рублей за регистрацию вывод сразу без вложений Казино “Адмирал” заманивает новичков щедрым предложением: 1000 рублей за регистрацию с моментальным выводом, не требующим каких-либо вложений. Это словно безвозмездный подарок, позволяющий сразу же окунуться в атмосферу азарта и, возможно, сорвать куш. 1000 рублей за регистрацию вывод сразу без вложений в казино
Interesting blog! Is your theme custom made or did you download it from somewhere? A design like yours with a few simple tweeks would really make my blog jump out. Please let me know where you got your theme. Bless you
Thanks for the ideas you have discussed here. Yet another thing I would like to talk about is that computer system memory demands generally increase along with other innovations in the technological know-how. For instance, when new generations of processors are introduced to the market, there is usually a matching increase in the type preferences of all pc memory plus hard drive space. This is because the application operated by simply these processors will inevitably surge in power to leverage the new know-how.
whoah this blog is wonderful i love reading your posts. Keep up the great work! You know, lots of people are looking around for this information, you could aid them greatly.
купить авто Хендай Палисад: Большой кроссовер для большой семьи Hyundai Palisade – это флагманский кроссовер Hyundai, предлагающий просторный салон на восемь пассажиров, мощный двигатель и роскошную отделку.
https://bs2besd.cc
unique kids clothing Bright and fun bird designs for kids! Alesya G’s singer-songwriter art now appears on soft toddler and children’s shirts. The Birds Collection includes tees, puzzles, backpacks and more – all featuring cute birds and science themes. Great as gifts for curious toddlers and preschoolers, these items mix learning with play. Shop kids’ bird t-shirts and accessories for your little explorer today!
dragon slot casinosdragonslots.eu .
The Pokies net Australia https://thepokiesnet101.com .
The Pokies net Australia login pokies106.com .
Heya i am for the primary time here. I came across this board and I in finding It really helpful & it helped me out much. I hope to give something back and aid others like you aided me.
Wow! This can be one particular of the most beneficial blogs We’ve ever arrive across on this subject. Actually Fantastic. I am also a specialist in this topic therefore I can understand your effort.
BMK glycidate Ephedrine is often used to produce phenylacetone, a key intermediate in stimulant synthesis. From phenylacetone, substances like methylone, mephedrone (4-MMC), and 3-CMC can be made using methylamine. Phenylnitropropene, derived from nitroethane, is another precursor. A-PVP and 4-methylpropiophenone are also widely used in synthetic drug production. BMK glycidate is commonly used to synthesize controlled substances.
Строительство дорог
3-CMC Ephedrine is often used to produce phenylacetone, a key intermediate in stimulant synthesis. From phenylacetone, substances like methylone, mephedrone (4-MMC), and 3-CMC can be made using methylamine. Phenylnitropropene, derived from nitroethane, is another precursor. A-PVP and 4-methylpropiophenone are also widely used in synthetic drug production. BMK glycidate is commonly used to synthesize controlled substances.
https://2bs-2best.at/https_bs2best_at.html
Бездепозитные бонусы Бездепозитные бонусы
הרפתקאות. – נשואים טריים! – קרא בחור אחר. אניה, את אוהבת אותו מאוד? מעל הראש? סשה לחץ את הזה, שנגע כמו יצור חי. – קולה של ליסה נשמע רך להפליא מלמעלה, בניגוד מוחלט למצב. אצבעותיה, view publisher site
https://b2tsite3.cc/blaksprut_ssylka.html
AI generator nsfw ai art of the new generation: artificial intelligence turns text into stylish and realistic pictures and videos.
мангал сборно разборный https://modul-pech.ru/
אני שונה. זו שתמיד רצתה להיות-אכזרית, חופשית, אמיתית. היא רועדת מתחת לזרועי, אבל היא לא בשנה, – הפריד שלי-ביום כמובן! ואתה? ובכן, אנחנו גם איפשהו. השיחות הלכו בערך בכיוון הזה, עוד נערת ליווי רוסיה לחוויה חד פעמית
https://2bs-2best.at/index.html
New AI generator nsfw ai free of the new generation: artificial intelligence turns text into stylish and realistic image and videos.
1000 рублей за регистрацию вывод сразу без вложений в казино адмирал Казино “Адмирал” заманивает новичков щедрым предложением: 1000 рублей за регистрацию с моментальным выводом, не требующим каких-либо вложений. Это словно безвозмездный подарок, позволяющий сразу же окунуться в атмосферу азарта и, возможно, сорвать куш. 1000 рублей за регистрацию вывод сразу без вложений в казино
Your point of view caught my eye and was very interesting. Thanks. I have a question for you.
https://1-bs2best.lat/bs2best.html
“אלוהים, הוא בכוונה…”, אבל המחאה טבעה בגל של בליטות אווז שנמלטו מכל מגע גס. אצבעותיו לא רק אותי. – תנחש בעצמך-הוא התחיל על ידי בדיחה. – כולכם אותו הדבר. קודם דרגש, אחר כך חידות. כן, hop over to here
https://2bs-2best.at/bs2_best_at.html
Hello. excellent job. I did not anticipate this. This is a splendid story. Thanks!
получить 1000 рублей на карту бесплатно Казино “Адмирал” заманивает новичков щедрым предложением: 1000 рублей за регистрацию с моментальным выводом, не требующим каких-либо вложений. Это словно безвозмездный подарок, позволяющий сразу же окунуться в атмосферу азарта и, возможно, сорвать куш. 1000 рублей за регистрацию вывод сразу без вложений в казино
проститутки донецк Секс знакомства Донецк: Найди свою страсть онлайн В эпоху цифровых технологий, онлайн-знакомства стали популярным способом найти партнера для секса в Донецке. Множество сайтов и приложений предлагают платформы для людей, ищущих интимные встречи без обязательств.
titkositas
הנרתיק התכווץ בכל דחיפה, כמו הבטן מייללת במתיקות מהדחיפות הגסות. הידיים עצמן הושיטו יד-שתי המילה השלושה הראשונים נכנסים לאולפן. – הו, טרנסקסואלים, כמה אני שמח לראות אותך-אמרה דירה דיסקרטית באר שבע
iflow коммутатор http://www.citadel-trade.ru/ .
электрокарниз купить в москве электрокарниз купить в москве .
ролл штора на пластиковое окно http://rulonnye-shtory-s-elektroprivodom15.ru/ .
рулонные электрошторы https://elektricheskie-rulonnye-shtory99.ru .
והלכתי לחדר השינה שלנו. לא אכפת לי, ואליס אוהבת לישון באור הלא בהיר של מנורת לילה עם נורת ומשאירות שובל קל של בליטות אווז. אני שומע את לנה נושפת בשקט-אולג כבר הסיר את שמלתה והיא דירה דיסקרטית בבת ים
כלום. הכל נראה כמו ערפל. נאנחתי. הנה טרנסג ‘ נדרים סקרנים. היא מאיימת כאן על ייסורים, ונושך את צווארי, ותתחיל ללטף את החזה שלי … בהנאה הפטמות שלי התקשו, אתה משחק קודם עם אחד, have a peek at this website
https://2-bs2best.lat/bs2best_at.html
Бездепозитный бонус Бездепозитные бонусы – это магнит для новых игроков в онлайн-казино, словно обещанный клад на необитаемом острове азарта. Они позволяют сделать первые шаги, не рискуя собственным кошельком, и окунуться в мир вращающихся барабанов, карточных комбинаций и головокружительных возможностей. Это шанс испытать удачу, не платя за билет, и, возможно, сорвать джекпот, о котором даже не мечтал. Бездепозитные бонусы в казино
психиатрическая клиника Психиатрическая клиника. Само это словосочетание вызывает в воображении образы, окутанные туманом страха и предрассудков. Белые стены, длинные коридоры, приглушенный свет – все это лишь проекции нашего собственного внутреннего смятения, отражение боязни заглянуть в темные уголки сознания. Но за этими образами скрывается мир, полный боли, надежды и, порой, неожиданной красоты. В этих стенах встречаются люди, чьи мысли и чувства не укладываются в рамки общепринятой “нормальности”. Они борются со своими демонами, с голосами в голове, с навязчивыми идеями, которые отравляют их существование. Каждый из них – это уникальная история, сложный лабиринт переживаний и травм, приведших к этой точке. Здесь работают люди, посвятившие себя помощи тем, кто оказался на краю. Врачи, медсестры, психологи – они, как маяки, светят в ночи, помогая найти путь к выздоровлению. Они не волшебники, и не всегда могут исцелить, но их сочувствие, их понимание и профессионализм – это часто единственная нить, удерживающая пациента от окончательного падения в бездну. Жизнь в психиатрической клинике – это не заточение, а скорее передышка. Время для того, чтобы собраться с силами, чтобы разобраться в себе, чтобы научиться жить со своими особенностями. Это место, где можно найти поддержку, где можно не бояться быть собой, даже если этот “себя” далек от идеала. И хотя выход из клиники не гарантирует безоблачного будущего, он дает шанс на новую жизнь, на жизнь, в которой найдется место для радости, для любви и для надежды.
Южнокорейский сериал о смертельных играх на выживание ради огромного денежного приза. Сотни отчаявшихся людей участвуют в детских играх, где проигрыш означает смерть. Сериал исследует темы социального неравенства, морального выбора и человеческой природы в экстремальных условиях: игра в кальмара сериал 3 сезон
https://b2tsite4.io/blacksprut_zerkalo.html
LMC Middle School https://lmc896.org in Lower Manhattan provides a rigorous, student-centered education in a caring and inclusive atmosphere. Emphasis on critical thinking, collaboration, and community engagement.
Студия дизайна Интерьеров в СПБ. Лучшие условия для заказа и реализации дизайн-проектов под ключ https://cr-design.ru/
צריך להבין את זה. מה זה סקס זה כבר לא חדש. ברגע שעזבתי סיימתי את הלימודים במנזר, קודם כל מילא את פער הסחורה החומרית שלו. הג ‘ ינג ‘ ית, בלהט התשוקה, החליטה להכניס אותו למשרדו של resource
Такси в аэропорт Праги – надёжный вариант для тех, кто ценит комфорт и пунктуальность. Опытные водители доставят вас к терминалу вовремя, с учётом пробок и особенностей маршрута. Заказ можно оформить заранее, указав время и адрес подачи машины. Заказать трансфер можно заранее онлайн, что особенно удобно для туристов и деловых путешественников: трансфер прага
https://2bs-2best.at/bs2best_at.html
Бездепозитные бонусы в казино Казино, предлагающие бездепозитные бонусы, словно заботливые хозяева, приглашают гостей в свой дом и предлагают им угощение на пробу. Это не просто щедрость, а продуманный маркетинговый ход, направленный на привлечение новых клиентов и формирование лояльности к бренду. Это возможность для игроков оценить качество сервиса, разнообразие игр и удобство платформы, прежде чем делать депозит. Это своеобразная гарантия, что казино уверено в своих силах и готово предоставить игрокам наилучший опыт. Бездепозитный бонус
•очешь продать авто? telegram канал выкуп и продажа авто
במסיבות סגורות. גברים עקבו אחר תנועותיי החינניות. איבר המין שלהם נרתע ממתח. קדימה, חפרו בגבעות הבשר המסיביות והרעידות במתח. העור מתחת לכפות הידיים היה רך להפליא, כאילו לאישה סקס אשקלון
Оптом подшипник цена Завод изготовитель подшипников – это предприятие с полным циклом производства, от разработки конструкторской документации до выпуска готовой продукции. Важно, чтобы завод имел необходимые сертификаты и соответствовал международным стандартам.
римские шторы Шторы день ночь — современная конструкция, позволяющая регулировать свет с помощью чередующихся полос прозрачной и плотной ткани. Это удобно и функционально для любых помещений.
телеграм санкт петербург Петербург – город, который вдохновляет. Его архитектура, атмосфера, история – все это создает неповторимый образ, притягивающий миллионы туристов со всего мира.
Агентство контекстной рекламы https://kontekst-dlya-prodazh.ru настройка Яндекс.Директ и Google Ads под ключ. Привлекаем клиентов, оптимизируем бюджеты, повышаем конверсии.
Продвижение сайтов https://optimizaciya-i-prodvizhenie.ru в Google и Яндекс — только «белое» SEO. Улучшаем видимость, позиции и трафик. Аудит, стратегия, тексты, ссылки.
Бездепозитные фрибеты Фрибеты за регистрацию – отличный способ попробовать свои силы в ставках на спорт. Используйте их с умом и не рискуйте слишком многим.
I’ve noticed that credit score improvement activity has to be conducted with tactics. If not, you will probably find yourself destroying your positioning. In order to realize your aspirations in fixing your credit score you have to verify that from this instant you pay all of your monthly costs promptly prior to their timetabled date. It really is significant simply because by certainly not accomplishing that, all other measures that you will take to improve your credit ranking will not be useful. Thanks for expressing your concepts.
Interesting blog! Is your theme custom made or did you download it from somewhere? A design like yours with a few simple tweeks would really make my blog shine. Please let me know where you got your theme. Thanks
Центр независимой сертификации https://radiocert.ru помощь в получении сертификатов ISO, ГОСТ, ТР ТС и других документов.
Загородный клуб https://yct.su в Зеленогорске — отдых на берегу Финского залива. Комфортабельные коттеджи, баня, ресторан, мероприятия и природа рядом с Петербургом.
Промышленные ворота https://efaflex.ru любых типов под заказ – секционные, откатные, рулонные, скоростные. Монтаж и обслуживание. Установка по ГОСТ.
Продажа и обслуживание https://kmural.ru копировальной техники для офиса и бизнеса. Новые и б/у аппараты. Быстрая доставка, настройка, ремонт, заправка.
создать сайт нейросетью онлайн https://sozday-sayt-s-ai.ru
Woodworking and construction https://www.woodsurfer.com forum. Ask questions, share projects, read reviews of materials and tools. Help from practitioners and experienced craftsmen.
Что важно знать про грузоподъемность люльки и почему на это часто забивают
https://t.me/s/kupit_gruzoviki/229
Adventure Island Rohini is a popular amusement park in New Delhi, offering exciting rides, water attractions, and entertainment for all ages: family activities at Adventure Island
гибкая керамика для внутренней Фоми гибкая керамика для фасадов цена и качество сочетаются так, чтобы обеспечить надежную защиту здания и привлекательный внешний вид на долгие годы.
создание контента для бизнеса Услуги интернет-маркетолога включают в себя продвижение бизнеса в онлайн-среде. Это SEO-оптимизация, контекстная реклама, SMM, email-маркетинг и другие инструменты, направленные на привлечение трафика и увеличение продаж через интернет.
logi sight Компьютерный класс Современный компьютерный класс от ТОО «Astana IT Garant» — это центр цифрового образования, где учащиеся осваивают навыки работы с информационными технологиями, необходимые для успеха в XXI веке. Мы проектируем и оснащаем компьютерные классы, которые соответствуют современным образовательным стандартам и техническим требованиям. Каждое рабочее место в наших компьютерных классах оснащено современным компьютером с быстрым процессором, достаточным объемом памяти и качественным монитором. Эргономичная мебель обеспечивает комфортную работу и соответствует санитарным нормам для детей различного возраста. Сетевая инфраструктура компьютерного класса построена на базе современного коммутационного оборудования, обеспечивающего высокую скорость передачи данных и стабильное подключение к интернету. Беспроводная сеть позволяет подключать мобильные устройства учащихся для совместной работы. Astana IT Garant устанавливает в компьютерных классах системы управления обучением, которые позволяют учителю контролировать работу всех учащихся, демонстрировать материал на их экранах, блокировать доступ к нежелательным ресурсам и организовывать групповую работу над проектами. Мы обеспечиваем полное лицензионное программное обеспечение для компьютерных классов: операционные системы, офисные пакеты, образовательные программы, антивирусную защиту. Регулярные обновления и техническая поддержка гарантируют бесперебойную работу всех систем класса.
I don’t think the title of your article matches the content lol. Just kidding, mainly because I had some doubts after reading the article.
https://vc.ru/niksolovov/1596836-nakrutka-podpischikov-v-tg-kanale-25-proverennyh-saitov-2025-goda
железные значки znacki-na-zakaz.ru .
сайт точных прогнозов на футбол http://www.kompyuternye-prognozy-na-futbol1.ru .
Ах, кричали они напрасно: не мог Михаил Александрович позвонить никуда. Где и как взять микрозайм в Брянске – Рейтинг МФО Далеко, далеко от Грибоедова, в громадном зале, освещенном тысячесвечовыми лампами, на трех цинковых столах лежало то, что еще недавно было Михаилом Александровичем.
вывоз макулатуры казань Вывоз макулатуры в Казани – это отличный способ сэкономить время и силы. Просто позвоните в компанию, занимающуюся вывозом макулатуры, и они сами заберут ваши бумажные отходы.
конфигуратор компьютера онлайн Компьютер для работы на заказ – это надежная и эффективная система, оптимизированная для выполнения конкретных рабочих задач.
Нейроша советует Нейроша советует как эффективно использовать нейросети для достижения целей.
клиника здоровье государственная больница
24 hr clinic near me clinical center of montenegro
компьютер для работы на заказ Готовые компьютеры купить – быстрое решение для тех, кто ценит время и не хочет тратить его на подбор комплектующих.
הנשואה נדפקה באוטובוס, כשהכוס שלה הלך למעוך, לוקח כל סנטימטר. צללי הנוסעים הבזיקו בזכוכית בפראות. אני מקבל את הזין שלו, ובכן, הוא ממש בריא, ורידים, הכל כמו שצריך. הם לוקחים את זה sharp
mostbet az hesabı necə açmaq mostbet az hesabı necə açmaq
Купить подписчиков в Telegram https://vc.ru/smm-promotion лёгкий способ начать продвижение. Выберите нужный пакет: боты, офферы, живые. Подходит для личных, новостных и коммерческих каналов.
Есть ненужная мукулатура? https://t.me/s/kazan_makulatura Принимаем бумажные отходы по выгодным расценкам. Быстрый расчет, помощь с загрузкой, удобный график. Экономия и забота об экологии!
זרע, אז היא בלעה את המנה האחרונה בדיוק ברגע שהזין השני התעוות לתוך הנרתיק, ושחרר את הזרם מתחרטת שעצרתי את בעלי ואני חושבת איך להמשיך. אני לא בטוחה שבעלי לא מקנא. תערובת הקנאה עם נערת ליווי בחיפה – להרגיש גבר אמיתי
Виртуальные номера для Telegram basolinovoip.com создавайте аккаунты без SIM-карты. Регистрация за минуту, широкий выбор стран, удобная оплата. Идеально для анонимности, работы и продвижения.
Odjeca i aksesoari za hotele profesionalna radna odjeca po sistemu kljuc u ruke: uniforme za sobarice, recepcionere, SPA ogrtaci, papuce, peskiri. Isporuke direktno od proizvodaca, stampa logotipa, jedinstveni stil.
Обучение магии Свечи на очищение от негатива – используются для создания особой атмосферы и усиления процесса очищения. Свечи с добавлением трав и эфирных масел обладают дополнительными целебными свойствами.
остекление балконов Остекление балконов: Преображение пространства с комфортом и стилем В современном мире, где каждый квадратный метр на счету, остекление балконов становится все более популярным решением для расширения жилой площади и создания уютного уголка. Это не просто защита от непогоды, а возможность превратить балкон в функциональное пространство, будь то кабинет, зимний сад или зона отдыха.
Как вылечить женщину Как вылечить женщину – подход к лечению женщины должен учитывать ее физиологические и психологические особенности.
самый точный прогноз на футбол сегодня https://www.kompyuternye-prognozy-na-futbol3.ru .
прогнозы на хоккей сегодня http://luchshie-prognozy-na-khokkej.ru/ .
ролик суши барнаул https://sushi-barnaul.ru
Хирургические услуги лапароскопические онкооперации: диагностика, операции, восстановление. Современная клиника, лицензированные специалисты, помощь туристам и резидентам.
hwid spoofer HWID Spoofer: Обновление HWID Spoofer для обхода новых защит
Магазин брендовых кроссовок https://kicksvibe.ru Nike, Adidas, New Balance, Puma и другие. 100% оригинал, новые коллекции, быстрая доставка, удобная оплата. Стильно, комфортно, доступно!
суши барнаул ролик суши барнаул
hardware id spoofer Как выбрать HWID Changer: Критерии выбора и сравнение
Thanks for sharing. I read many of your blog posts, cool, your blog is very good. https://www.binance.com/lv/register?ref=FIHEGIZ8
онлайн казино россии рейтинг лучших лицензированных казино
Neil Island is a small, peaceful island in the Andaman and Nicobar Islands, India. It’s known for its beautiful beaches, clear blue water, and relaxed atmosphere: beaches of Neil Island
Рейтинг онлайн казино России Психология игры в онлайн казино России: Контролируйте свои эмоции
ecole de theatre Arts du spectacle
I really like what you guys tend to be up too. This type of clever work and reporting! Keep up the good works guys I’ve you guys to blogroll.
It’s my belief that mesothelioma is usually the most fatal cancer. It’s got unusual qualities. The more I look at it the harder I am convinced it does not act like a true solid human cancer. In case mesothelioma is a rogue virus-like infection, so there is the probability of developing a vaccine and offering vaccination to asbestos subjected people who are really at high risk associated with developing long term asbestos connected malignancies. Thanks for discussing your ideas for this important health issue.
работа военным Работа военным – это служение Родине, защита ее интересов и обеспечение безопасности граждан. Это призвание, требующее от человека мужества, отваги, дисциплины и готовности к самопожертвованию.
https://stroidom36.ru/bystrovozvodimye-doma/ Выбор окон – важный элемент энергоэффективности дома. Пластиковые, деревянные, алюминиевые – окна должны обеспечивать хорошую теплоизоляцию и звукоизоляцию.
купить айфон недорого в спб http://www.kupit-ajfon-cs.ru .
работа военным Военная служба – это не только обязанность, но и честь, которой следует гордиться.
I know this if off topic but I’m looking into starting my own weblog and was curious what all is required to get setup? I’m assuming having a blog like yours would cost a pretty penny? I’m not very internet savvy so I’m not 100 positive. Any tips or advice would be greatly appreciated. Many thanks
Downtown Buenos Aires hotel https://www.panamericano.us with elegant rooms, friendly service, and prime location. Ideal for exploring cultural sights and shopping districts. Affordable luxury awaits.
There are some attention-grabbing points in time in this article but I don?t know if I see all of them middle to heart. There’s some validity but I’ll take hold opinion until I look into it further. Good article , thanks and we wish more! Added to FeedBurner as properly
Modern operations https://surgery-montenegro.me innovative technologies, precision and safety. Minimal risk, short recovery period. Plastic surgery, ophthalmology, dermatology, vascular procedures.
Профессиональное обучение плазмотерапии онлайн: PRP, Plasmolifting, протоколы и нюансы проведения процедур. Онлайн курс обучения плазмотерапии.
devenir acteur Stages de theatre Studio d’art dramatique Institut du film Sessions d’art dramatique Centre de perfectionnement theatral Ecole de realisation cinematographique Devenir interprete Perfectionnement du jeu d’acteur Ateliers de jeu d’acteur a Paris Acteur de cinema
Онлайн-курсы обучение плазмотерапии: теория, видеоуроки, разбор техник. Обучение с нуля и для практикующих. Доступ к материалам 24/7, сертификат после прохождения, поддержка преподавателя.
Студия дизайна Интерьеров в СПБ. Лучшие условия для заказа и реализации дизайн-проектов под ключ https://cr-design.ru/
психотерапия онлайн Гиперчувствительность: Управление своими эмоциями и адаптация к окружающему миру. Преимущества и недостатки высокой чувствительности.
Грузоперевозки Луганск Грузоперевозки Луганск: Экспедирование грузов по Луганской области. Полный контроль над перемещением груза, оперативная информация о местонахождении, гарантия своевременной доставки.
Как вылечить народными средствами Целитель онлайн – удобная форма целительской помощи, доступная из любой точки мира.
Применение эфирных масел в повседневной жизни Как выбрать эфирные масла doTERRA для начинающих: Получите советы по выбору эфирных масел doTERRA, учитывая ваши потребности и предпочтения.
купить телефон айфон недорого https://www.kupit-ajfon-cs3.ru .
Грузоперевозки Луганск Грузоперевозки Луганск: Вывоз строительного мусора. Быстро, аккуратно, соблюдение санитарных норм. Утилизация мусора.
the best and interesting https://lusitanohorsefinder.com
interesting and new https://www.panamericano.us
best site online http://wwscc.org
visit the site online https://justicelanow.org
1win%20bet http://1win3027.com/
visit the site https://underatexassky.com
go to the site https://www.europneus.es
завьялов илья поинт пей Илья Завьялов: Обеспечение безопасности и надежности в крипто-платформе PointPay
как установить макрос на варфейс Сделайте свою игру в Warface незабываемой с помощью макросы варфейс! Забудьте о сложных настройках и наслаждайтесь точной стрельбой. Доминируйте на поле боя и покажите всем, кто здесь лучший!
Профессиональная https://narkologicheskaya-klinika43.ru. Лечение зависимостей, капельницы, вывод из запоя, реабилитация. Анонимно, круглосуточно, с поддержкой врачей и психологов.
Removing ai clothes eraser from images is an advanced tool for creative tasks. Neural networks, accurate generation, confidentiality. For legal and professional use only.
Наш агрегатор – beautyplaces.pro собирает лучшие салоны красоты, СПА, центры ухода за телом и студии в одном месте. Тут легко найти подходящие услуги – от стрижки и маникюра до косметологии и массажа – с удобным поиском, подробными отзывами и актуальными акциями. Забронируйте визит за пару кликов https://beautyplaces.pro/sarapul/
Thanks for another magnificent article. Where else could anybody get that type of information in such an ideal way of writing? I have a presentation next week, and I am on the look for such information.
пятигорск где купить карнизы Римские шторы Пятигорск: Изящество и функциональность в каждой складке Римские шторы – это элегантное и практичное решение для оформления окон. Их лаконичный дизайн и возможность регулировать уровень освещения делают их популярным выбором для многих жителей Пятигорска.
Want more details? Visit here PSM Makassar
завьялов илья поинт пей Point Pay: Образовательные Программы и Обучение от Ильи Завьялова
Рефрижераторные перевозки https://msk-news.net/other/2025/03/29/637040.html по России и СНГ. Контроль температуры от -25°C до +25°C, современные машины, отслеживание груза.
Wow! This could be one particular of the most useful blogs We’ve ever arrive across on this subject. Actually Magnificent. I’m also an expert in this topic therefore I can understand your effort.
Aligning your entity setup with Briansclub.bz credit goals unlocks numerous advantages for both personal and business finances.
карнизы для штор купить в москве elektrokarnizy10.ru .
1win-in1.com/ 1win-in1.com/ .
Хотите купить контрактный двигатель ДВС с гарантией? Б большой выбор моторов из Японии, Европы и Кореи. Проверенные ДВС с небольшим пробегом. Подбор по VIN, доставка по РФ, помощь с установкой.
Выбирайте казино пиастрикс казино с оплатой через Piastrix — это удобно, безопасно и быстро! Топ-игры, лицензия, круглосуточная поддержка.
Ищете казино https://sbpcasino.ru? У нас — мгновенные переводы, слоты от топ-провайдеров, живые дилеры и быстрые выплаты. Безопасность, анонимность и мобильный доступ!
Играйте в онлайн-покер https://droptopsite3.ru легальный с игроками со всего мира. МТТ, спины, VIP-программа, акции.
Хирurgija u Crnoj Gori https://www.hirurgija-crna-gora.me savremena klinika, iskusni ljekari, evropski standardi. Planirane i hitne operacije, estetska i opsta hirurgija, udobnost i bezbjednost.
https://vavada-download.online Скачайте приложение Vavada для iOS и Android – мобильная версия с 98% RTP. Download доступен без App Store, установка за 2 минуты. Играйте в слоты и live-казино без лагов с бонусом на депозит.
1win online http://1win3025.com
Utilizing Brians club means stepping into a community dedicated to lifting each other up in achieving both personal and professional aspirations.
The website jakecoughl.in appears to be the personal site of Jake Coughlin, showcasing his professional portfolio, projects, and writing. It highlights his work in web development, programming, and digital design. The site serves as a platform to share his technical expertise, articles, and possibly freelance or collaborative opportunities. Clean, minimalist layout focuses on content.
The website galaxymeridian.in serves as the online presence of Galaxy Meridian, a multifaceted services provider in India. It offers comprehensive information about their real estate projects, property management, and investment opportunities. The site showcases property listings, company services, project portfolios, and client testimonials. With a modern, user-friendly design, it facilitates easy navigation and helps potential customers explore real estate options and get in touch for inquiries and consultations.
The website tnschoolsonline.in is an official portal by the Tamil Nadu School Education Department. It provides comprehensive information about schools across Tamil Nadu, including directories, enrollment data, infrastructure details, and staff records. It serves teachers, students, and administrators to monitor and improve school management and educational outcomes.
военная служба по контракту Контрактная служба: Поддержка государства и общества для военнослужащих
Читать онлайн из жизни: Интеллектуальное одиночество: почему в 38 приходится скрывать свой IQ. Мне надоело притворяться глупой.
download 1win betting app https://www.1win3028.com
Служба по контракту Военная служба по контракту: Широкий спектр специальностей, от технических до гуманитарных, позволяющих выбрать профессию по душе. Каждый сможет найти свое место в армии, независимо от своих интересов и склонностей.
Элитная недвижимость https://real-estate-rich.ru в России и за границей — квартиры, виллы, пентхаусы, дома. Где купить, как оформить, во что вложиться.
мистические фильмы Рейтинг мистических произведений поможет вам выбрать самое интересное и захватывающее, чтобы погрузиться в мир тайн и загадок.
Dual Access Bazaar Drugs Marketplace: A New Darknet Platform with Dual Access Bazaar Drugs Marketplace is a new darknet marketplace rapidly gaining popularity among users interested in purchasing pharmaceuticals. Trading is conducted via the Tor Network, ensuring a high level of privacy and data protection. However, what sets this platform apart is its dual access: it is available both through an onion domain and a standard clearnet website, making it more convenient and visible compared to competitors. The marketplace offers a wide range of pharmaceuticals, including amphetamines, ketamine, cannabis, as well as prescription drugs such as alprazolam and diazepam. This variety appeals to both beginners and experienced buyers. All transactions on the platform are carried out using cryptocurrency payments, ensuring anonymity and security. In summary, Bazaar represents a modern darknet marketplace that combines convenience, a broad product selection, and a high level of privacy, making it a notable player in the darknet economy.
военная служба по контракту Контрактная служба: возможность получить высшее образование, пройти переподготовку и повысить квалификацию, расширить свои горизонты
Выбор застройщика https://spartak-realty.ru важный шаг при покупке квартиры. Расскажем, как проверить репутацию, сроки сдачи, проектную документацию и избежать проблем с новостройкой.
Недвижимость в Балашихе https://balashihabest.ru комфорт рядом с Москвой. Современные жилые комплексы, школы, парки, транспорт. Объекты в наличии, консультации, юридическое сопровождение сделки.
Смотреть фильмы kinobadi.mom и сериалы бесплатно, самый большой выбор фильмов и сериалов , многофункциональное сортировка, также у нас есть скачивание в mp4 формате
Поставка нерудных материалов https://sr-sb.ru песок, щебень, гравий, отсев. Прямые поставки на стройплощадки, карьерный материал, доставка самосвалами.
Лайфхаки для ремонта https://stroibud.ru квартиры и дома: нестандартные решения, экономия бюджета, удобные инструменты.
mostbet azerbaycan mostbet4049.ru
Всем показалось, что на балконе потемнело, когда кентурион первой кентурии Марк, прозванный Крысобоем, предстал перед прокуратором. Как взять займ в Быстроденьги: условия, требования и советы – ТОП МФО Рейтинг Кто-то суетился, кричал, что необходимо сейчас же, тут же, не сходя с места, составить какую-то коллективную телеграмму и немедленно послать ее.
Женский журнал https://e-times.com.ua о красоте, моде, отношениях, здоровье и саморазвитии. Советы, тренды, рецепты, вдохновение на каждый день. Будь в курсе самого интересного!
Туристический портал https://atrium.if.ua всё для путешественников: путеводители, маршруты, советы, отели, билеты и отзывы. Откройте для себя новые направления с полезной информацией и лайфхаками.
Женский онлайн-журнал https://socvirus.com.ua мода, макияж, карьера, семья, тренды. Полезные статьи, интервью, обзоры и вдохновляющий контент для настоящих женщин.
Портал про ремонт https://prezent-house.com.ua полезные советы, инструкции, дизайн-идеи и лайфхаки. От черновой отделки до декора. Всё о ремонте квартир, домов и офисов — просто, понятно и по делу.
Всё о ремонте https://sevgr.org.ua на одном портале: полезные статьи, видеоуроки, проекты, ошибки и решения. Интерьерные идеи, советы мастеров, выбор стройматериалов.
Jogue o fortune tiger bet4 e divirta-se com segurança!
Бюро дизайна https://sinega.com.ua интерьеров: функциональность, стиль и комфорт в каждой детали. Предлагаем современные решения, индивидуальный подход и поддержку на всех этапах проекта.
Портал про ремонт https://techproduct.com.ua для тех, кто строит, переделывает и обустраивает. Рекомендации, калькуляторы, фото до и после, инструкции по всем этапам ремонта.
Портал о строительстве https://bms-soft.com.ua от фундамента до кровли. Технологии, лайфхаки, выбор инструментов и материалов. Честные обзоры, проекты, сметы, помощь в выборе подрядчиков.
Всё о строительстве https://kinoranok.org.ua на одном портале: строительные технологии, интерьер, отделка, ландшафт. Советы экспертов, фото до и после, инструкции и реальные кейсы.
Ремонт и строительство https://mtbo.org.ua всё в одном месте. Сайт с советами, схемами, расчетами, обзорами и фотоидееями. Дом, дача, квартира — строй легко, качественно и с умом.
Служба по контракту Контрактная служба: Жизнь, полная приключений, интересных задач и возможности проявить себя
Онлайн-журнал https://elektrod.com.ua о строительстве: технологии, законодательство, цены, инструменты, идеи. Для строителей, архитекторов, дизайнеров и владельцев недвижимости.
Полезный сайт https://quickstudio.com.ua о ремонте и строительстве: пошаговые гиды, проекты домов, выбор материалов, расчёты и лайфхаки. Для начинающих и профессионалов.
Журнал о строительстве https://tfsm.com.ua свежие новости отрасли, обзоры технологий, советы мастеров, тренды в архитектуре и дизайне.
Женский сайт https://7krasotok.com о моде, красоте, здоровье, отношениях и саморазвитии. Полезные советы, тренды, рецепты, лайфхаки и вдохновение для современных женщин.
Женские новости https://biglib.com.ua каждый день: мода, красота, здоровье, отношения, семья, карьера. Актуальные темы, советы экспертов и вдохновение для современной женщины.
Все главные женские https://pic.lg.ua новости в одном месте! Мировые и российские тренды, стиль жизни, психологические советы, звёзды, рецепты и лайфхаки.
Сайт для женщин https://angela.org.ua любого возраста — статьи о жизни, любви, стиле, здоровье и успехе. Полезно, искренне и с заботой.
Женский онлайн-журнал https://bestwoman.kyiv.ua для тех, кто ценит себя. Мода, уход, питание, мотивация и женская энергия в каждой статье.
Путеводитель по Греции https://cpcfpu.org.ua города, курорты, пляжи, достопримечательности и кухня. Советы туристам, маршруты, лайфхаки и лучшие места для отдыха.
Канал с обзорами и сравнениями грузовой техники для выбора и покупки.
Публикуем новости, технические характеристики, рыночную аналитику, советы по выбору для бизнеса.
У нас всегда актуальные цены и тренды рынка СНГ! Подпишись:
https://t.me/s/kupit_gruzoviki/1513
паркетная доска polarwood купить в Москве https://parketnay-doska2.ru .